 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning on 3D Neural Fields
Dec 20, 2023



In recent years, Neural Fields (NFs) have emerged as an effective tool for encoding diverse continuous signals such as images, videos, audio, and 3D shapes. When applied to 3D data, NFs offer a solution to the fragmentation and limitations associated with prevalent discrete representations. However, given that NFs are essentially neural networks, it remains unclear whether and how they can be seamlessly integrated into deep learning pipelines for solving downstream tasks. This paper addresses this research problem and introduces nf2vec, a framework capable of generating a compact latent representation for an input NF in a single inference pass. We demonstrate that nf2vec effectively embeds 3D objects represented by the input NFs and showcase how the resulting embeddings can be employed in deep learning pipelines to successfully address various tasks, all while processing exclusively NFs. We test this framework on several NFs used to represent 3D surfaces, such as unsigned/signed distance and occupancy fields. Moreover, we demonstrate the effectiveness of our approach with more complex NFs that encompass both geometry and appearance of 3D objects such as neural radiance fields.
ReLight My NeRF: A Dataset for Novel View Synthesis and Relighting of Real World Objects
Apr 20, 2023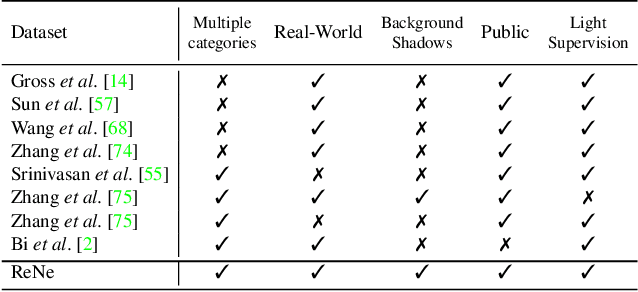



In this paper, we focus on the problem of rendering novel views from a Neural Radiance Field (NeRF) under unobserved light conditions. To this end, we introduce a novel dataset, dubbed ReNe (Relighting NeRF), framing real world objects under one-light-at-time (OLAT) conditions, annotated with accurate ground-truth camera and light poses. Our acquisition pipeline leverages two robotic arms holding, respectively, a camera and an omni-directional point-wise light source. We release a total of 20 scenes depicting a variety of objects with complex geometry and challenging materials. Each scene includes 2000 images, acquired from 50 different points of views under 40 different OLAT conditions. By leveraging the dataset, we perform an ablation study on the relighting capability of variants of the vanilla NeRF architecture and identify a lightweight architecture that can render novel views of an object under novel light conditions, which we use to establish a non-trivial baseline for the dataset. Dataset and benchmark are available at https://eyecan-ai.github.io/rene.
Deep Learning on Implicit Neural Representations of Shapes
Feb 10, 2023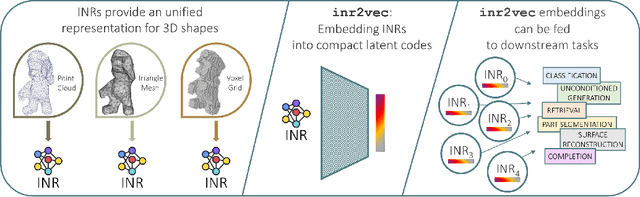

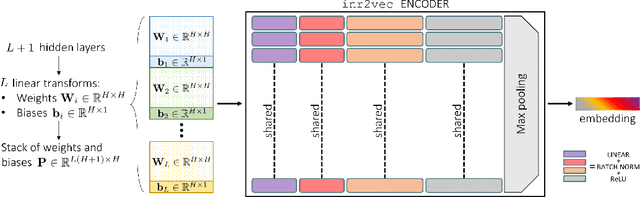

Implicit Neural Representations (INRs) have emerged in the last few years as a powerful tool to encode continuously a variety of different signals like images, videos, audio and 3D shapes. When applied to 3D shapes, INRs allow to overcome the fragmentation and shortcomings of the popular discrete representations used so far. Yet, considering that INRs consist in neural networks, it is not clear whether and how it may be possible to feed them into deep learning pipelines aimed at solving a downstream task. In this paper, we put forward this research problem and propose inr2vec, a framework that can compute a compact latent representation for an input INR in a single inference pass. We verify that inr2vec can embed effectively the 3D shapes represented by the input INRs and show how the produced embeddings can be fed into deep learning pipelines to solve several tasks by processing exclusively INRs.
Self-Distillation for Unsupervised 3D Domain Adaptation
Oct 15, 2022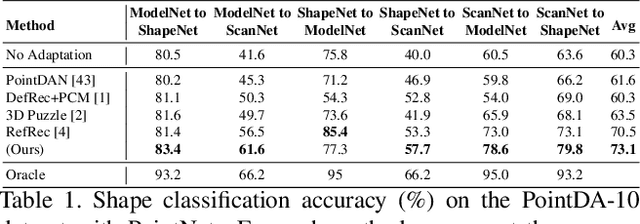
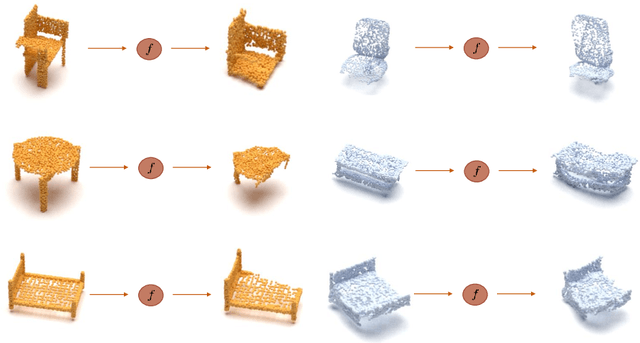

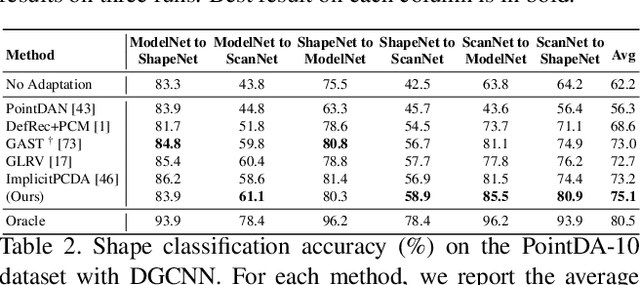
Point cloud classification is a popular task in 3D vision. However, previous works, usually assume that point clouds at test time are obtained with the same procedure or sensor as those at training time. Unsupervised Domain Adaptation (UDA) instead, breaks this assumption and tries to solve the task on an unlabeled target domain, leveraging only on a supervised source domain. For point cloud classification, recent UDA methods try to align features across domains via auxiliary tasks such as point cloud reconstruction, which however do not optimize the discriminative power in the target domain in feature space. In contrast, in this work, we focus on obtaining a discriminative feature space for the target domain enforcing consistency between a point cloud and its augmented version. We then propose a novel iterative self-training methodology that exploits Graph Neural Networks in the UDA context to refine pseudo-labels. We perform extensive experiments and set the new state-of-the-art in standard UDA benchmarks for point cloud classification. Finally, we show how our approach can be extended to more complex tasks such as part segmentation.
RefRec: Pseudo-labels Refinement via Shape Reconstruction for Unsupervised 3D Domain Adaptation
Oct 21, 2021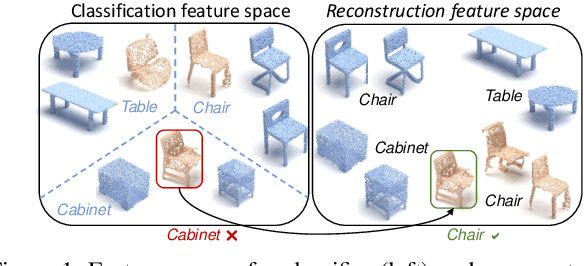



Unsupervised Domain Adaptation (UDA) for point cloud classification is an emerging research problem with relevant practical motivations. Reliance on multi-task learning to align features across domains has been the standard way to tackle it. In this paper, we take a different path and propose RefRec, the first approach to investigate pseudo-labels and self-training in UDA for point clouds. We present two main innovations to make self-training effective on 3D data: i) refinement of noisy pseudo-labels by matching shape descriptors that are learned by the unsupervised task of shape reconstruction on both domains; ii) a novel self-training protocol that learns domain-specific decision boundaries and reduces the negative impact of mislabelled target samples and in-domain intra-class variability. RefRec sets the new state of the art in both standard benchmarks used to test UDA for point cloud classification, showcasing the effectiveness of self-training for this important problem.
Go with the Flows: Mixtures of Normalizing Flows for Point Cloud Generation and Reconstruction
Jun 18, 2021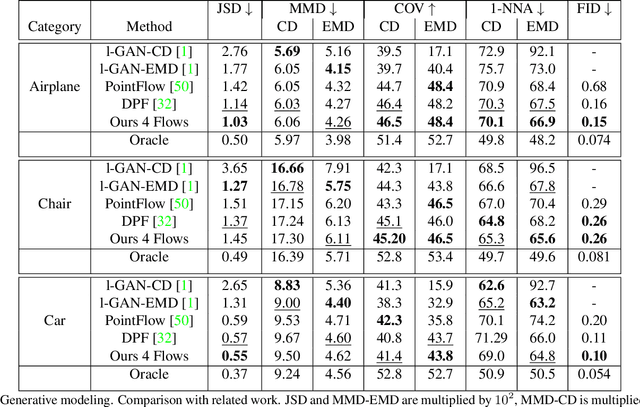
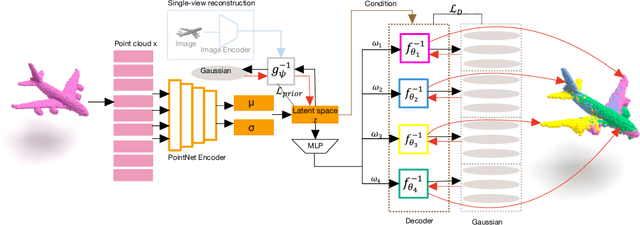
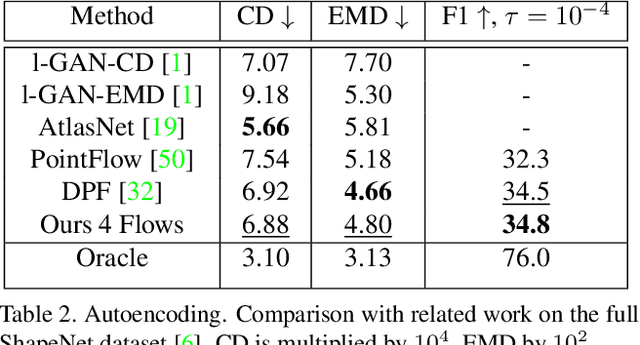
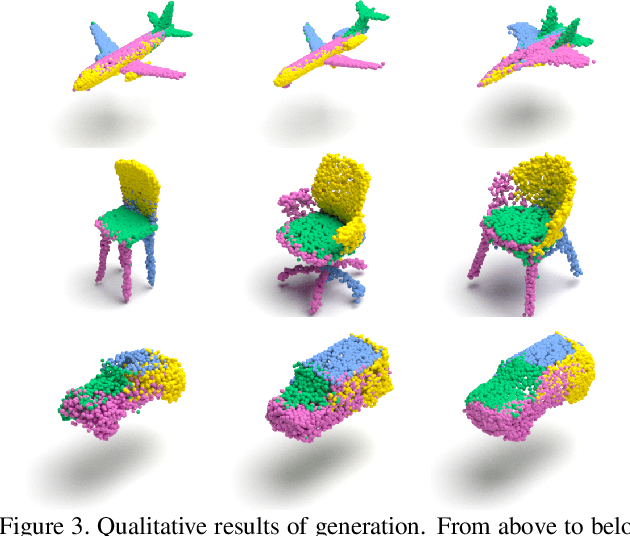
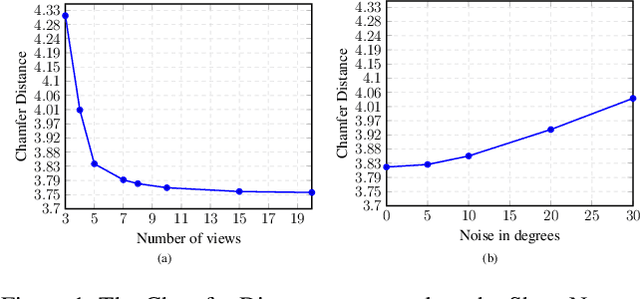
Recently normalizing flows (NFs) have demonstrated state-of-the-art performance on modeling 3D point clouds while allowing sampling with arbitrary resolution at inference time. However, these flow-based models still require long training times and large models for representing complicated geometries. This work enhances their representational power by applying mixtures of NFs to point clouds. We show that in this more general framework each component learns to specialize in a particular subregion of an object in a completely unsupervised fashion. By instantiating each mixture component with a comparatively small NF we generate point clouds with improved details compared to single-flow-based models while using fewer parameters and considerably reducing the inference runtime. We further demonstrate that by adding data augmentation, individual mixture components can learn to specialize in a semantically meaningful manner. We evaluate mixtures of NFs on generation, autoencoding and single-view reconstruction based on the ShapeNet dataset.
A Divide et Impera Approach for 3D Shape Reconstruction from Multiple Views
Nov 18, 2020
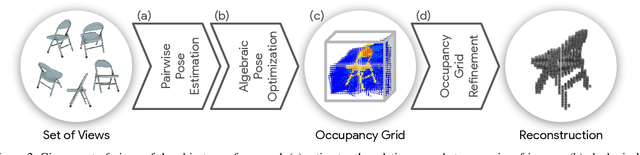

Estimating the 3D shape of an object from a single or multiple images has gained popularity thanks to the recent breakthroughs powered by deep learning. Most approaches regress the full object shape in a canonical pose, possibly extrapolating the occluded parts based on the learned priors. However, their viewpoint invariant technique often discards the unique structures visible from the input images. In contrast, this paper proposes to rely on viewpoint variant reconstructions by merging the visible information from the given views. Our approach is divided into three steps. Starting from the sparse views of the object, we first align them into a common coordinate system by estimating the relative pose between all the pairs. Then, inspired by the traditional voxel carving, we generate an occupancy grid of the object taken from the silhouette on the images and their relative poses. Finally, we refine the initial reconstruction to build a clean 3D model which preserves the details from each viewpoint. To validate the proposed method, we perform a comprehensive evaluation on the ShapeNet reference benchmark in terms of relative pose estimation and 3D shape reconstruction.
Learning to Orient Surfaces by Self-supervised Spherical CNNs
Nov 13, 2020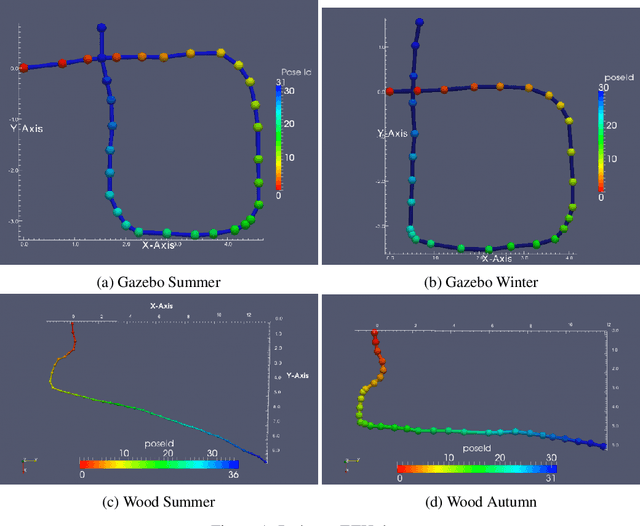
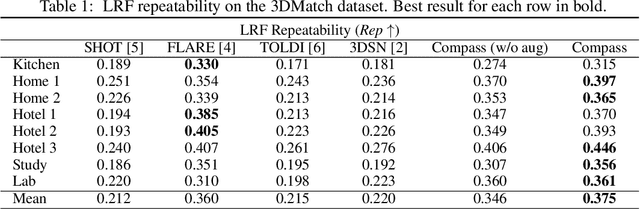
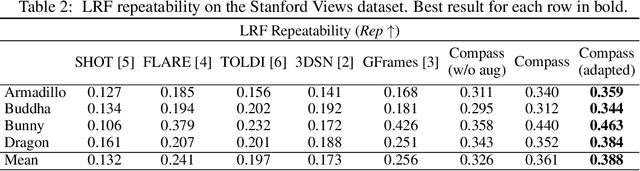
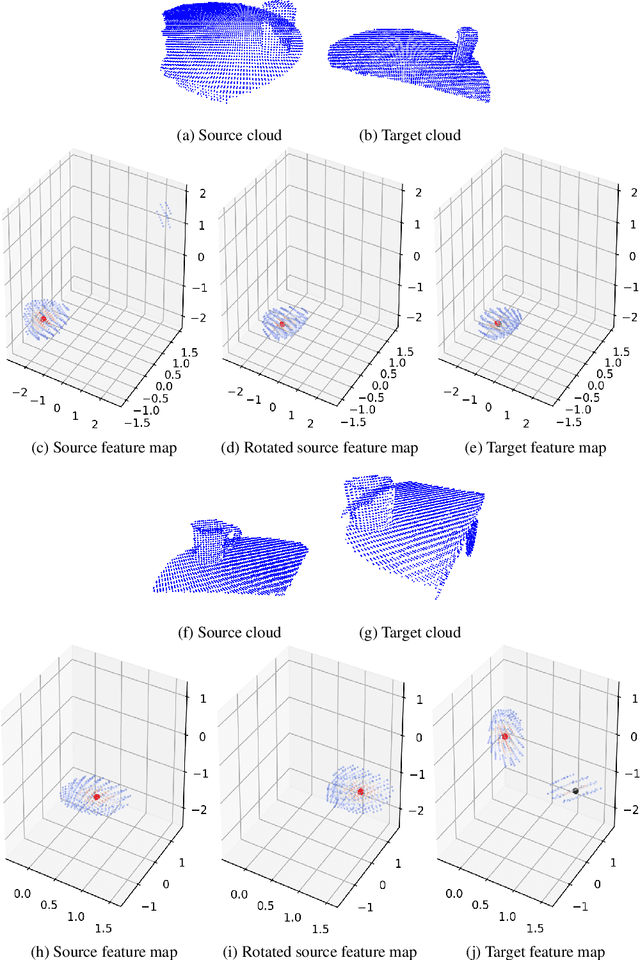
Defining and reliably finding a canonical orientation for 3D surfaces is key to many Computer Vision and Robotics applications. This task is commonly addressed by handcrafted algorithms exploiting geometric cues deemed as distinctive and robust by the designer. Yet, one might conjecture that humans learn the notion of the inherent orientation of 3D objects from experience and that machines may do so alike. In this work, we show the feasibility of learning a robust canonical orientation for surfaces represented as point clouds. Based on the observation that the quintessential property of a canonical orientation is equivariance to 3D rotations, we propose to employ Spherical CNNs, a recently introduced machinery that can learn equivariant representations defined on the Special Orthogonal group SO(3). Specifically, spherical correlations compute feature maps whose elements define 3D rotations. Our method learns such feature maps from raw data by a self-supervised training procedure and robustly selects a rotation to transform the input point cloud into a learned canonical orientation. Thereby, we realize the first end-to-end learning approach to define and extract the canonical orientation of 3D shapes, which we aptly dub Compass. Experiments on several public datasets prove its effectiveness at orienting local surface patches as well as whole objects.
Boosting Object Recognition in Point Clouds by Saliency Detection
Nov 06, 2019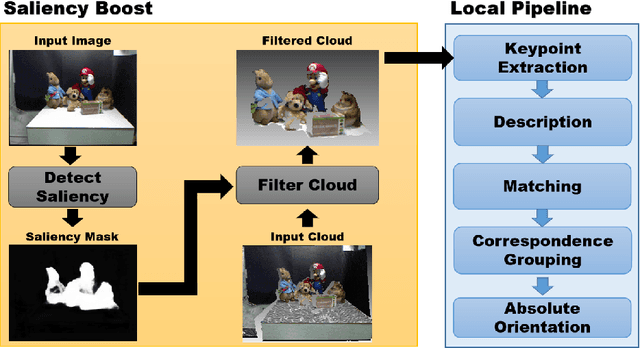


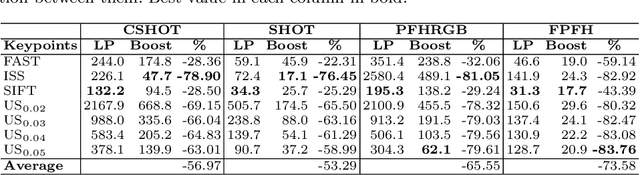
Object recognition in 3D point clouds is a challenging task, mainly when time is an important factor to deal with, such as in industrial applications. Local descriptors are an amenable choice whenever the 6 DoF pose of recognized objects should also be estimated. However, the pipeline for this kind of descriptors is highly time-consuming. In this work, we propose an update to the traditional pipeline, by adding a preliminary filtering stage referred to as saliency boost. We perform tests on a standard object recognition benchmark by considering four keypoint detectors and four local descriptors, in order to compare time and recognition performance between the traditional pipeline and the boosted one. Results on time show that the boosted pipeline could turn out up to 5 times faster, with the recognition rate improving in most of the cases and exhibiting only a slight decrease in the others. These results suggest that the boosted pipeline can speed-up processing time substantially with limited impacts or even benefits in recognition accuracy.
Learning an Effective Equivariant 3D Descriptor Without Supervision
Sep 15, 2019



Establishing correspondences between 3D shapes is a fundamental task in 3D Computer Vision, typically addressed by matching local descriptors. Recently, a few attempts at applying the deep learning paradigm to the task have shown promising results. Yet, the only explored way to learn rotation invariant descriptors has been to feed neural networks with highly engineered and invariant representations provided by existing hand-crafted descriptors, a path that goes in the opposite direction of end-to-end learning from raw data so successfully deployed for 2D images. In this paper, we explore the benefits of taking a step back in the direction of end-to-end learning of 3D descriptors by disentangling the creation of a robust and distinctive rotation equivariant representation, which can be learned from unoriented input data, and the definition of a good canonical orientation, required only at test time to obtain an invariant descriptor. To this end, we leverage two recent innovations: spherical convolutional neural networks to learn an equivariant descriptor and plane folding decoders to learn without supervision. The effectiveness of the proposed approach is experimentally validated by outperforming hand-crafted and learned descriptors on a standard benchmark.