 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLight My NeRF: A Dataset for Novel View Synthesis and Relighting of Real World Objects
Apr 20, 2023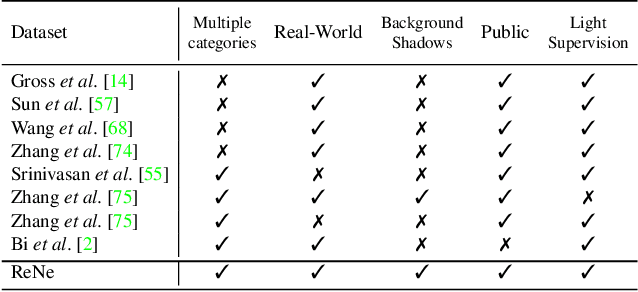



In this paper, we focus on the problem of rendering novel views from a Neural Radiance Field (NeRF) under unobserved light conditions. To this end, we introduce a novel dataset, dubbed ReNe (Relighting NeRF), framing real world objects under one-light-at-time (OLAT) conditions, annotated with accurate ground-truth camera and light poses. Our acquisition pipeline leverages two robotic arms holding, respectively, a camera and an omni-directional point-wise light source. We release a total of 20 scenes depicting a variety of objects with complex geometry and challenging materials. Each scene includes 2000 images, acquired from 50 different points of views under 40 different OLAT conditions. By leveraging the dataset, we perform an ablation study on the relighting capability of variants of the vanilla NeRF architecture and identify a lightweight architecture that can render novel views of an object under novel light conditions, which we use to establish a non-trivial baseline for the dataset. Dataset and benchmark are available at https://eyecan-ai.github.io/rene.
NeRF-Supervised Deep Stereo
Mar 30, 2023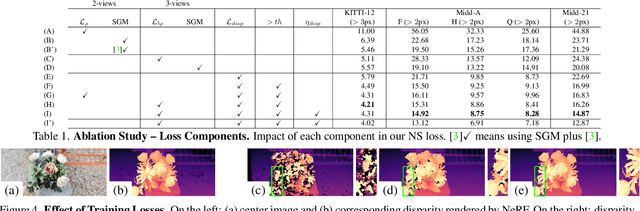
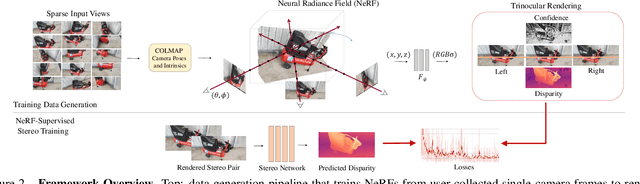


We introduce a novel framework for training deep stereo networks effortlessly and without any ground-truth. By leveraging state-of-the-art neural rendering solutions, we generate stereo training data from image sequences collected with a single handheld camera. On top of them, a NeRF-supervised training procedure is carried out, from which we exploit rendered stereo triplets to compensate for occlusions and depth maps as proxy labels. This results in stereo networks capable of predicting sharp and detailed disparity maps. Experimental results show that models trained under this regime yield a 30-40% improvement over existing self-supervised methods on the challenging Middlebury dataset, filling the gap to supervised models and, most times, outperforming them at zero-shot generalization.
ScanNeRF: a Scalable Benchmark for Neural Radiance Fields
Dec 20, 2022



In this paper, we propose the first-ever real benchmark thought for evaluating Neural Radiance Fields (NeRFs) and, in general, Neural Rendering (NR) frameworks. We design and implement an effective pipeline for scanning real objects in quantity and effortlessly. Our scan station is built with less than 500$ hardware budget and can collect roughly 4000 images of a scanned object in just 5 minutes. Such a platform is used to build ScanNeRF, a dataset characterized by several train/val/test splits aimed at benchmarking the performance of modern NeRF methods under different conditions. Accordingly, we evaluate three cutting-edge NeRF variants on it to highlight their strengths and weaknesses. The dataset is available on our project page, together with an online benchmark to foster the development of better and better NeRFs.
The Eyecandies Dataset for Unsupervised Multimodal Anomaly Detection and Localization
Oct 10, 2022
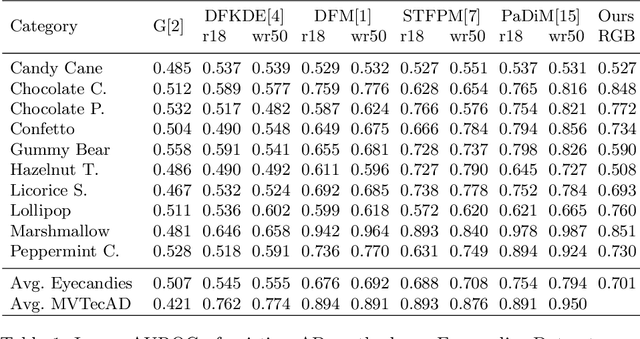
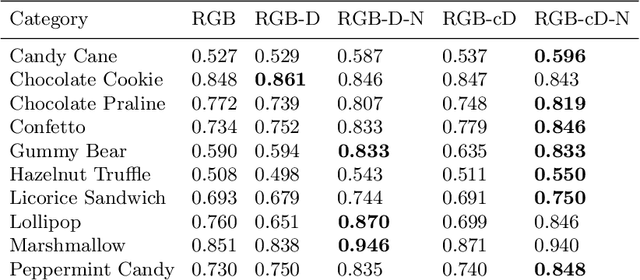
We present Eyecandies, a novel synthetic dataset for unsupervised anomaly detection and localization. Photo-realistic images of procedurally generated candies are rendered in a controlled environment under multiple lightning conditions, also providing depth and normal maps in an industrial conveyor scenario. We make available anomaly-free samples for model training and validation, while anomalous instances with precise ground-truth annotations are provided only in the test set. The dataset comprises ten classes of candies, each showing different challenges, such as complex textures, self-occlusions and specularities. Furthermore, we achieve large intra-class variation by randomly drawing key parameters of a procedural rendering pipeline, which enables the creation of an arbitrary number of instances with photo-realistic appearance. Likewise, anomalies are injected into the rendering graph and pixel-wise annotations are automatically generated, overcoming human-biases and possible inconsistencies. We believe this dataset may encourage the exploration of original approaches to solve the anomaly detection task, e.g. by combining color, depth and normal maps, as they are not provided by most of the existing datasets. Indeed, in order to demonstrate how exploiting additional information may actually lead to higher detection performance, we show the results obtained by training a deep convolutional autoencoder to reconstruct different combinations of inputs.
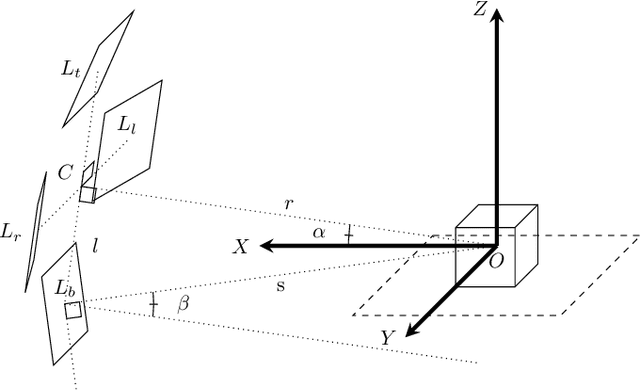
Effective Deployment of CNNs for 3DoF Pose Estimation and Grasping in Industrial Settings
Dec 24, 2020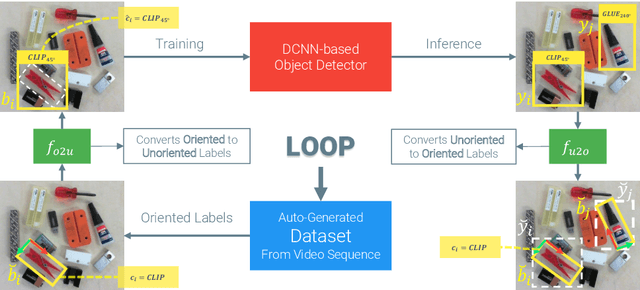
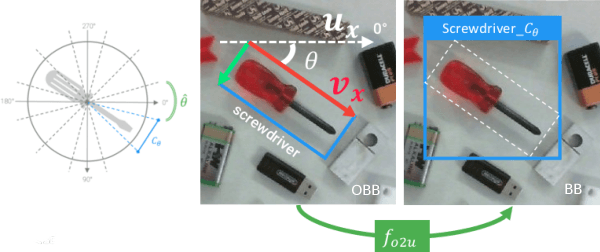
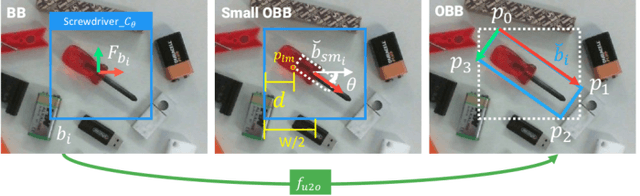
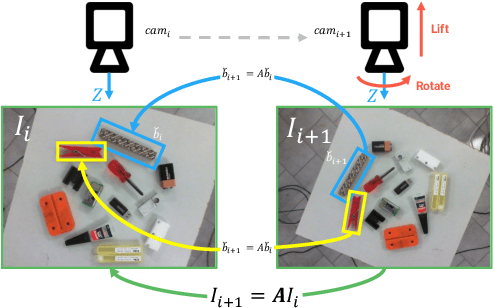
In this paper we investigate how to effectively deploy deep learning in practical industrial settings, such as robotic grasping applications. When a deep-learning based solution is proposed, usually lacks of any simple method to generate the training data. In the industrial field, where automation is the main goal, not bridging this gap is one of the main reasons why deep learning is not as widespread as it is in the academic world. For this reason, in this work we developed a system composed by a 3-DoF Pose Estimator based on Convolutional Neural Networks (CNNs) and an effective procedure to gather massive amounts of training images in the field with minimal human intervention. By automating the labeling stage, we also obtain very robust systems suitable for production-level usage. An open source implementation of our solution is provided, alongside with the dataset used for the experimental evaluation.
Shooting Labels: 3D Semantic Labeling by Virtual Reality
Oct 11, 2019



Availability of a few, large-size, annotated datasets, like ImageNet, Pascal VOC and COCO, has lead deep learning to revolutionize computer vision research by achieving astonishing results in several vision tasks. We argue that new tools to facilitate generation of annotated datasets may help spreading data-driven AI throughout applications and domains. In this work we propose Shooting Labels, the first 3D labeling tool for dense 3D semantic segmentation which exploits Virtual Reality to render the labeling task as easy and fun as playing a video-game. Our tool allows for semantically labeling large scale environments very expeditiously, whatever the nature of the 3D data at hand (e.g. pointclouds, mesh). Furthermore, Shooting Labels efficiently integrates multi-users annotations to improve the labeling accuracy automatically and compute a label uncertainty map. Besides, within our framework the 3D annotations can be projected into 2D images, thereby speeding up also a notoriously slow and expensive task such as pixel-wise semantic labeling. We demonstrate the accuracy and efficiency of our tool in two different scenarios: an indoor workspace provided by Matterport3D and a large-scale outdoor environment reconstructed from 1000+ KITTI images.
Semi-Automatic Labeling for Deep Learning in Robotics
Aug 05, 2019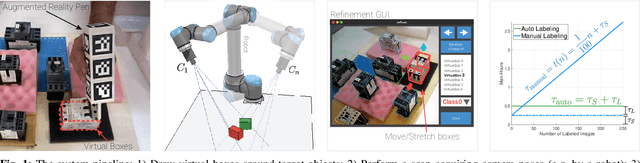
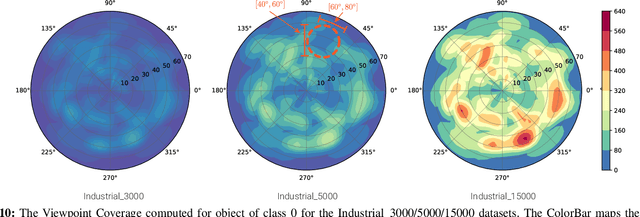
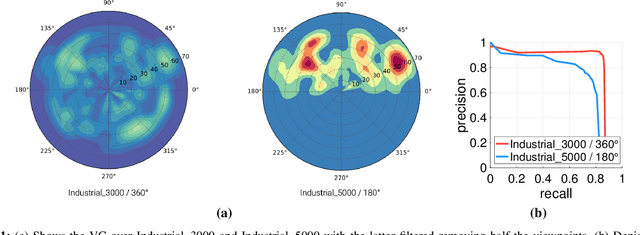
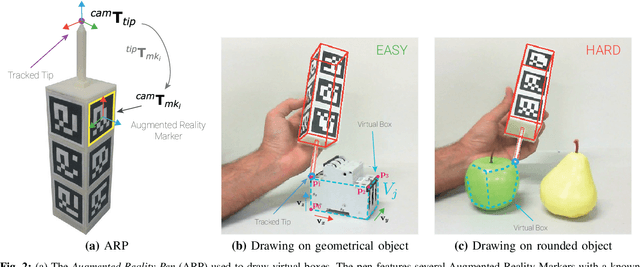
In this paper, we propose Augmented Reality Semi-automatic labeling (ARS), a semi-automatic method which leverages on moving a 2D camera by means of a robot, proving precise camera tracking, and an augmented reality pen to define initial object bounding box, to create large labeled datasets with minimal human intervention. By removing the burden of generating annotated data from humans, we make the Deep Learning technique applied to computer vision, that typically requires very large datasets, truly automated and reliable. With the ARS pipeline, we created effortlessly two novel datasets, one on electromechanical components (industrial scenario) and one on fruits (daily-living scenario), and trained robustly two state-of-the-art object detectors, based on convolutional neural networks, such as YOLO and SSD. With respect to the conventional manual annotation of 1000 frames that takes us slightly more than 10 hours, the proposed approach based on ARS allows annotating 9 sequences of about 35000 frames in less than one hour, with a gain factor of about 450. Moreover, both the precision and recall of object detection is increased by about 15\% with respect to manual labeling. All our software is available as a ROS package in a public repository alongside the novel annotated datasets.
Let's take a Walk on Superpixels Graphs: Deformable Linear Objects Segmentation and Model Estimation
Oct 10, 2018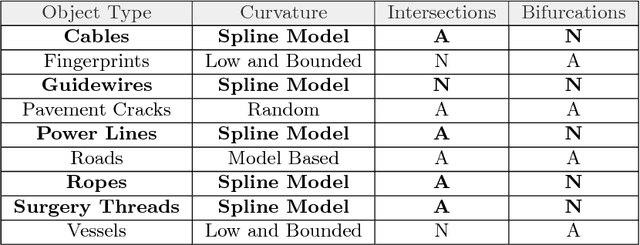
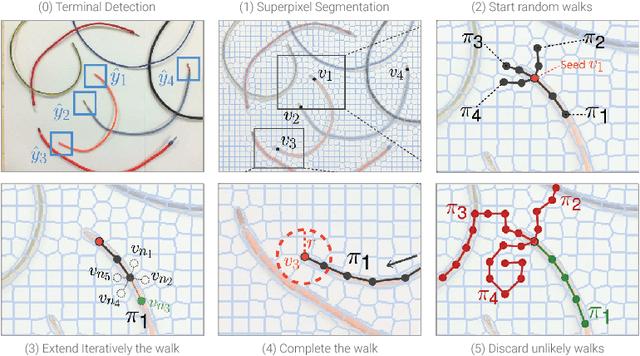
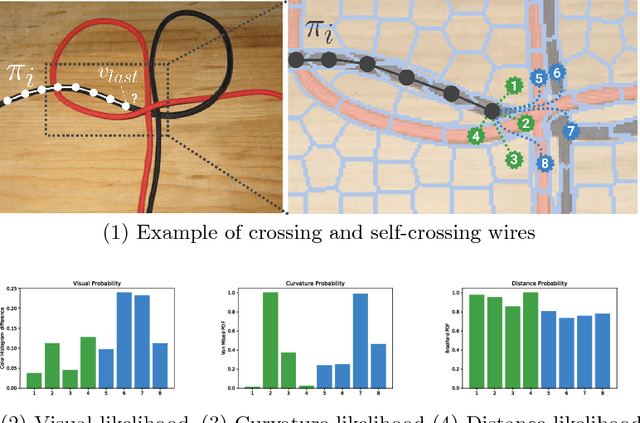
While robotic manipulation of rigid objects is quite straightforward, coping with deformable objects is an open issue. More specifically, tasks like tying a knot, wiring a connector or even surgical suturing deal with the domain of Deformable Linear Objects (DLOs). In particular the detection of a DLO is a non-trivial problem especially under clutter and occlusions (as well as self-occlusions). The pose estimation of a DLO results into the identification of its parameters related to a designed model, e.g. a basis spline. It follows that the stand-alone segmentation of a DLO might not be sufficient to conduct a full manipulation task. This is why we propose a novel framework able to perform both a semantic segmentation and b-spline modeling of multiple deformable linear objects simultaneously without strict requirements about environment (i.e. the background). The core algorithm is based on biased random walks over the Region Adiacency Graph built on a superpixel oversegmentation of the source image. The algorithm is initialized by a Convolutional Neural Networks that detects the DLO's endcaps. An open source implementation of the proposed approach is also provided to easy the reproduction of the whole detection pipeline along with a novel cables dataset in order to encourage further experiments.
SkiMap: An Efficient Mapping Framework for Robot Navigation
Apr 19, 2017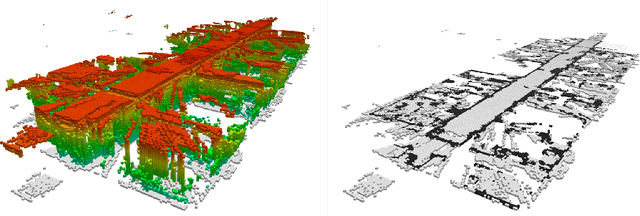

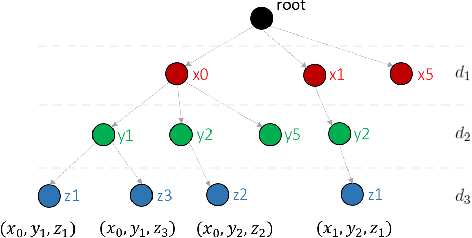
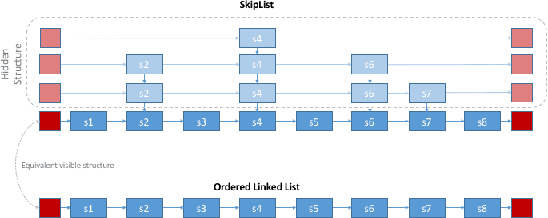
We present a novel mapping framework for robot navigation which features a multi-level querying system capable to obtain rapidly representations as diverse as a 3D voxel grid, a 2.5D height map and a 2D occupancy grid. These are inherently embedded into a memory and time efficient core data structure organized as a Tree of SkipLists. Compared to the well-known Octree representation, our approach exhibits a better time efficiency, thanks to its simple and highly parallelizable computational structure, and a similar memory footprint when mapping large workspaces. Peculiarly within the realm of mapping for robot navigation, our framework supports realtime erosion and re-integration of measurements upon reception of optimized poses from the sensor tracker, so as to improve continuously the accuracy of the map.