 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiM3D: Single-instance Multiview Multimodal and Multisetup 3D Anomaly Detection Benchmark
Jun 26, 2025We propose SiM3D, the first benchmark considering the integration of multiview and multimodal information for comprehensive 3D anomaly detection and segmentation (ADS), where the task is to produce a voxel-based Anomaly Volume. Moreover, SiM3D focuses on a scenario of high interest in manufacturing: single-instance anomaly detection, where only one object, either real or synthetic, is available for training. In this respect, SiM3D stands out as the first ADS benchmark that addresses the challenge of generalising from synthetic training data to real test data. SiM3D includes a novel multimodal multiview dataset acquired using top-tier industrial sensors and robots. The dataset features multiview high-resolution images (12 Mpx) and point clouds (7M points) for 333 instances of eight types of objects, alongside a CAD model for each type. We also provide manually annotated 3D segmentation GTs for anomalous test samples. To establish reference baselines for the proposed multiview 3D ADS task, we adapt prominent singleview methods and assess their performance using novel metrics that operate on Anomaly Volumes.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
Scaling LLaNA: Advancing NeRF-Language Understanding Through Large-Scale Training
Apr 18, 2025Recent advances in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities in understanding both images and 3D data, yet these modalities face inherent limitations in comprehensively representing object geometry and appearance. Neural Radiance Fields (NeRFs) have emerged as a promising alternative, encoding both geometric and photorealistic properties within the weights of a simple Multi-Layer Perceptron (MLP). This work investigates the feasibility and effectiveness of ingesting NeRFs into an MLLM. We introduce LLaNA, the first MLLM able to perform new tasks such as NeRF captioning and Q\&A, by directly processing the weights of a NeRF's MLP. Notably, LLaNA is able to extract information about the represented objects without the need to render images or materialize 3D data structures. In addition, we build the first large-scale NeRF-language dataset, composed by more than 300K NeRFs trained on ShapeNet and Objaverse, with paired textual annotations that enable various NeRF-language tasks. Based on this dataset, we develop a benchmark to evaluate the NeRF understanding capability of our method. Results show that directly processing NeRF weights leads to better performance on NeRF-Language tasks compared to approaches that rely on either 2D or 3D representations derived from NeRFs.
Embed Any NeRF: Graph Meta-Networks for Neural Tasks on Arbitrary NeRF Architectures
Feb 13, 2025Neural Radiance Fields (NeRFs) have emerged as a groundbreaking paradigm for representing 3D objects and scenes by encoding shape and appearance information into the weights of a neural network. Recent works have shown how such weights can be used as input to frameworks processing them to solve deep learning tasks. Yet, these frameworks can only process NeRFs with a specific, predefined architecture. In this paper, we present the first framework that can ingest NeRFs with multiple architectures and perform inference on architectures unseen at training time. We achieve this goal by training a Graph Meta-Network in a representation learning framework. Moreover, we show how a contrastive objective is conducive to obtaining an architecture-agnostic latent space. In experiments on both MLP-based and tri-planar NeRFs, our approach demonstrates robust performance in classification and retrieval tasks that either matches or exceeds that of existing frameworks constrained to single architectures, thus providing the first architecture-agnostic method to perform tasks on NeRFs by processing their weights.
Diffusion Models for Monocular Depth Estimation: Overcoming Challenging Conditions
Jul 23, 2024We present a novel approach designed to address the complexities posed by challenging, out-of-distribution data in the single-image depth estimation task. Starting with images that facilitate depth prediction due to the absence of unfavorable factors, we systematically generate new, user-defined scenes with a comprehensive set of challenges and associated depth information. This is achieved by leveraging cutting-edge text-to-image diffusion models with depth-aware control, known for synthesizing high-quality image content from textual prompts while preserving the coherence of 3D structure between generated and source imagery. Subsequent fine-tuning of any monocular depth network is carried out through a self-distillation protocol that takes into account images generated using our strategy and its own depth predictions on simple, unchallenging scenes. Experiments on benchmarks tailored for our purposes demonstrate the effectiveness and versatility of our proposal.
Looking for Tiny Defects via Forward-Backward Feature Transfer
Jul 04, 2024Motivated by efficiency requirements, most anomaly detection and segmentation (AD&S) methods focus on processing low-resolution images, e.g., $224\times 224$ pixels, obtained by downsampling the original input images. In this setting, downsampling is typically applied also to the provided ground-truth defect masks. Yet, as numerous industrial applications demand identification of both large and tiny defects, the above-described protocol may fall short in providing a realistic picture of the actual performance attainable by current methods. Hence, in this work, we introduce a novel benchmark that evaluates methods on the original, high-resolution image and ground-truth masks, focusing on segmentation performance as a function of the size of anomalies. Our benchmark includes a metric that captures robustness with respect to defect size, i.e., the ability of a method to preserve good localization from large anomalies to tiny ones. Furthermore, we introduce an AD&S approach based on a novel Teacher-Student paradigm which relies on two shallow MLPs (the Students) that learn to transfer patch features across the layers of a frozen vision transformer (the Teacher). By means of our benchmark, we evaluate our proposal and other recent AD&S methods on high-resolution inputs containing large and tiny defects. Our proposal features the highest robustness to defect size, runs at the fastest speed, yields state-of-the-art performance on the MVTec AD dataset and state-of-the-art segmentation performance on the VisA dataset.
LLaNA: Large Language and NeRF Assistant
Jun 17, 2024



Multimodal Large Language Models (MLLMs) have demonstrated an excellent understanding of images and 3D data. However, both modalities have shortcomings in holistically capturing the appearance and geometry of objects. Meanwhile, Neural Radiance Fields (NeRFs), which encode information within the weights of a simple Multi-Layer Perceptron (MLP), have emerged as an increasingly widespread modality that simultaneously encodes the geometry and photorealistic appearance of objects. This paper investigates the feasibility and effectiveness of ingesting NeRF into MLLM. We create LLaNA, the first general-purpose NeRF-language assistant capable of performing new tasks such as NeRF captioning and Q\&A. Notably, our method directly processes the weights of the NeRF's MLP to extract information about the represented objects without the need to render images or materialize 3D data structures. Moreover, we build a dataset of NeRFs with text annotations for various NeRF-language tasks with no human intervention. Based on this dataset, we develop a benchmark to evaluate the NeRF understanding capability of our method. Results show that processing NeRF weights performs favourably against extracting 2D or 3D representations from NeRFs.
Connecting NeRFs, Images, and Text
Apr 11, 2024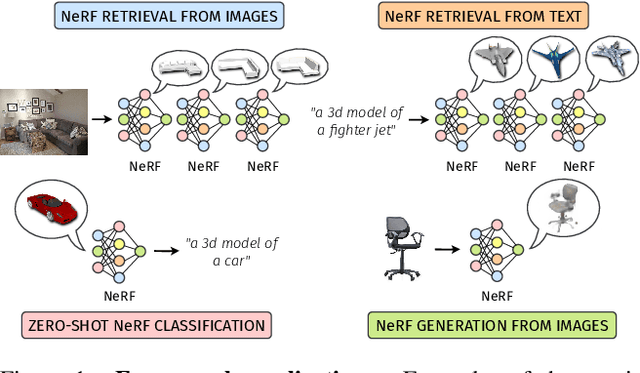
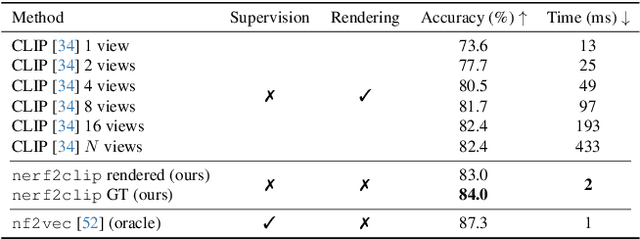
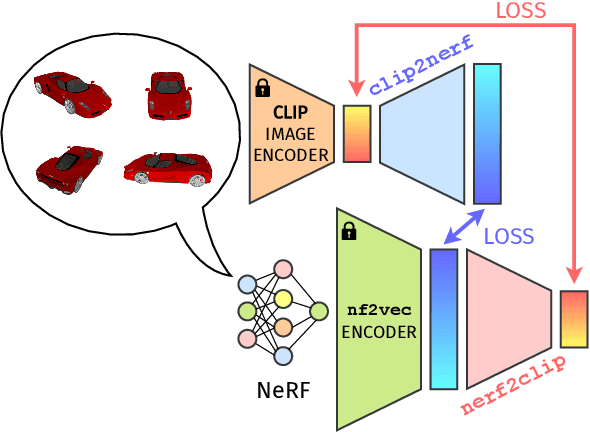
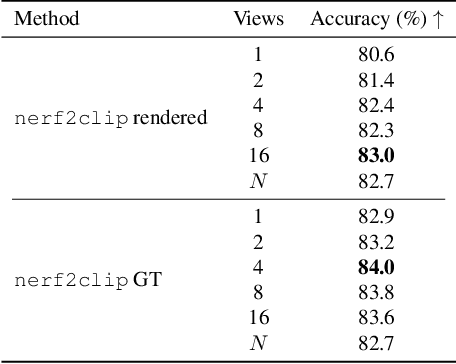
Neural Radiance Fields (NeRFs) have emerged as a standard framework for representing 3D scenes and objects, introducing a novel data type for information exchange and storage. Concurrently, significant progress has been made in multimodal representation learning for text and image data. This paper explores a novel research direction that aims to connect the NeRF modality with other modalities, similar to established methodologies for images and text. To this end, we propose a simple framework that exploits pre-trained models for NeRF representations alongside multimodal models for text and image processing. Our framework learns a bidirectional mapping between NeRF embeddings and those obtained from corresponding images and text. This mapping unlocks several novel and useful applications, including NeRF zero-shot classification and NeRF retrieval from images or text.
Test Time Training for Industrial Anomaly Segmentation
Apr 04, 2024Anomaly Detection and Segmentation (AD&S) is crucial for industrial quality control. While existing methods excel in generating anomaly scores for each pixel, practical applications require producing a binary segmentation to identify anomalies. Due to the absence of labeled anomalies in many real scenarios, standard practices binarize these maps based on some statistics derived from a validation set containing only nominal samples, resulting in poor segmentation performance. This paper addresses this problem by proposing a test time training strategy to improve the segmentation performance. Indeed, at test time, we can extract rich features directly from anomalous samples to train a classifier that can discriminate defects effectively. Our general approach can work downstream to any AD&S method that provides an anomaly score map as output, even in multimodal settings. We demonstrate the effectiveness of our approach over baselines through extensive experimentation and evaluation on MVTec AD and MVTec 3D-AD.
Deep Learning on 3D Neural Fields
Dec 20, 2023



In recent years, Neural Fields (NFs) have emerged as an effective tool for encoding diverse continuous signals such as images, videos, audio, and 3D shapes. When applied to 3D data, NFs offer a solution to the fragmentation and limitations associated with prevalent discrete representations. However, given that NFs are essentially neural networks, it remains unclear whether and how they can be seamlessly integrated into deep learning pipelines for solving downstream tasks. This paper addresses this research problem and introduces nf2vec, a framework capable of generating a compact latent representation for an input NF in a single inference pass. We demonstrate that nf2vec effectively embeds 3D objects represented by the input NFs and showcase how the resulting embeddings can be employed in deep learning pipelines to successfully address various tasks, all while processing exclusively NFs. We test this framework on several NFs used to represent 3D surfaces, such as unsigned/signed distance and occupancy fields. Moreover, we demonstrate the effectiveness of our approach with more complex NFs that encompass both geometry and appearance of 3D objects such as neural radiance fields.