 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning on 3D Neural Fields
Dec 20, 2023



In recent years, Neural Fields (NFs) have emerged as an effective tool for encoding diverse continuous signals such as images, videos, audio, and 3D shapes. When applied to 3D data, NFs offer a solution to the fragmentation and limitations associated with prevalent discrete representations. However, given that NFs are essentially neural networks, it remains unclear whether and how they can be seamlessly integrated into deep learning pipelines for solving downstream tasks. This paper addresses this research problem and introduces nf2vec, a framework capable of generating a compact latent representation for an input NF in a single inference pass. We demonstrate that nf2vec effectively embeds 3D objects represented by the input NFs and showcase how the resulting embeddings can be employed in deep learning pipelines to successfully address various tasks, all while processing exclusively NFs. We test this framework on several NFs used to represent 3D surfaces, such as unsigned/signed distance and occupancy fields. Moreover, we demonstrate the effectiveness of our approach with more complex NFs that encompass both geometry and appearance of 3D objects such as neural radiance fields.
Deep Learning on Implicit Neural Representations of Shapes
Feb 10, 2023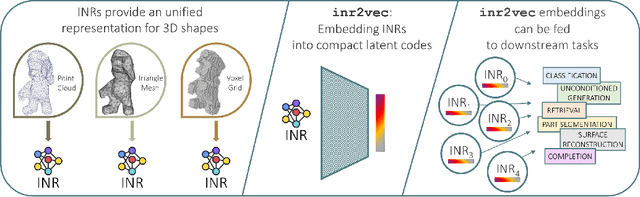

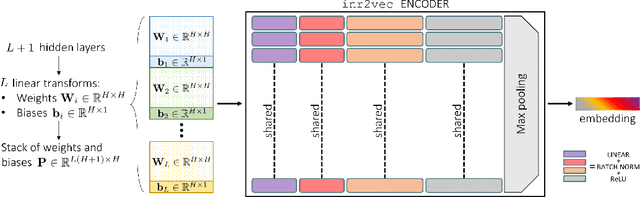

Implicit Neural Representations (INRs) have emerged in the last few years as a powerful tool to encode continuously a variety of different signals like images, videos, audio and 3D shapes. When applied to 3D shapes, INRs allow to overcome the fragmentation and shortcomings of the popular discrete representations used so far. Yet, considering that INRs consist in neural networks, it is not clear whether and how it may be possible to feed them into deep learning pipelines aimed at solving a downstream task. In this paper, we put forward this research problem and propose inr2vec, a framework that can compute a compact latent representation for an input INR in a single inference pass. We verify that inr2vec can embed effectively the 3D shapes represented by the input INRs and show how the produced embeddings can be fed into deep learning pipelines to solve several tasks by processing exclusively INRs.
Learning Good Features to Transfer Across Tasks and Domains
Jan 26, 2023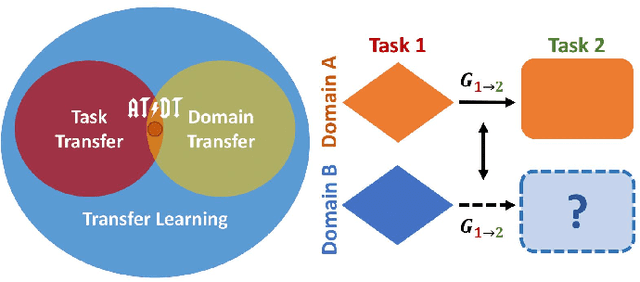

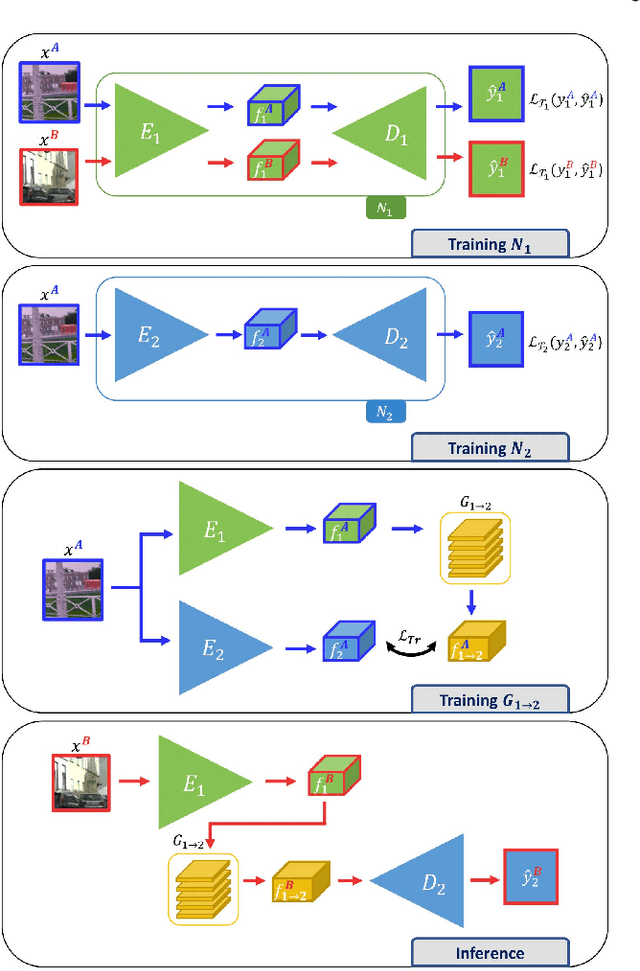
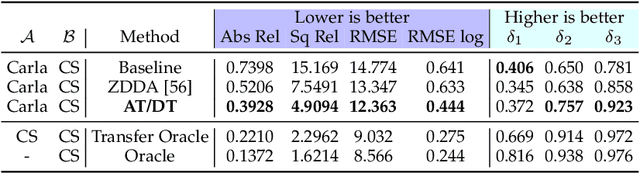
Availability of labelled data is the major obstacle to the deployment of deep learning algorithms for computer vision tasks in new domains. The fact that many frameworks adopted to solve different tasks share the same architecture suggests that there should be a way of reusing the knowledge learned in a specific setting to solve novel tasks with limited or no additional supervision. In this work, we first show that such knowledge can be shared across tasks by learning a mapping between task-specific deep features in a given domain. Then, we show that this mapping function, implemented by a neural network, is able to generalize to novel unseen domains. Besides, we propose a set of strategies to constrain the learned feature spaces, to ease learning and increase the generalization capability of the mapping network, thereby considerably improving the final performance of our framework. Our proposal obtains compelling results in challenging synthetic-to-real adaptation scenarios by transferring knowledge between monocular depth estimation and semantic segmentation tasks.
ScanNeRF: a Scalable Benchmark for Neural Radiance Fields
Dec 20, 2022



In this paper, we propose the first-ever real benchmark thought for evaluating Neural Radiance Fields (NeRFs) and, in general, Neural Rendering (NR) frameworks. We design and implement an effective pipeline for scanning real objects in quantity and effortlessly. Our scan station is built with less than 500$ hardware budget and can collect roughly 4000 images of a scanned object in just 5 minutes. Such a platform is used to build ScanNeRF, a dataset characterized by several train/val/test splits aimed at benchmarking the performance of modern NeRF methods under different conditions. Accordingly, we evaluate three cutting-edge NeRF variants on it to highlight their strengths and weaknesses. The dataset is available on our project page, together with an online benchmark to foster the development of better and better NeRFs.
DrapeNet: Generating Garments and Draping them with Self-Supervision
Dec 07, 2022



Recent approaches to drape garments quickly over arbitrary human bodies leverage self-supervision to eliminate the need for large training sets. However, they are designed to train one network per clothing item, which severely limits their generalization abilities. In our work, we rely on self-supervision to train a single network to drape multiple garments. This is achieved by predicting a 3D deformation field conditioned on the latent codes of a generative network, which models garments as unsigned distance fields. Our pipeline can generate and drape previously unseen garments of any topology, whose shape can be edited by manipulating their latent codes. Being fully differentiable, our formulation makes it possible to recover accurate 3D models of garments from partial observations -- images or 3D scans -- via gradient descent. Our code will be made publicly available.
Learning the Space of Deep Models
Jun 10, 2022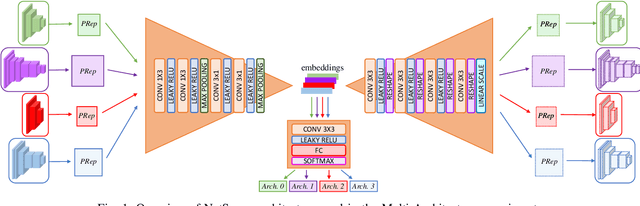
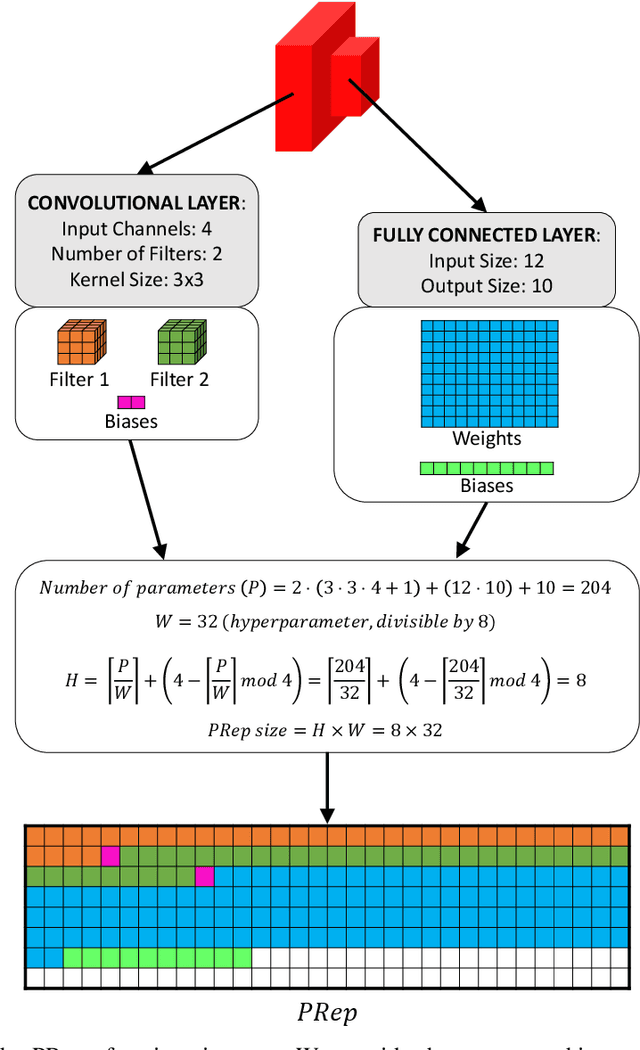
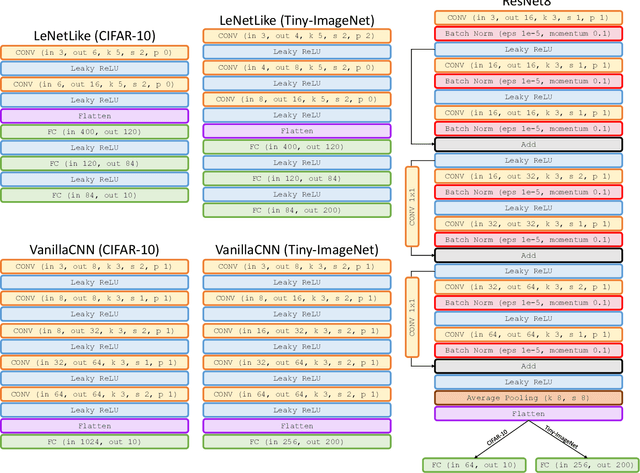
Embedding of large but redundant data, such as images or text, in a hierarchy of lower-dimensional spaces is one of the key features of representation learning approaches, which nowadays provide state-of-the-art solutions to problems once believed hard or impossible to solve. In this work, in a plot twist with a strong meta aftertaste, we show how trained deep models are as redundant as the data they are optimized to process, and how it is therefore possible to use deep learning models to embed deep learning models. In particular, we show that it is possible to use representation learning to learn a fixed-size, low-dimensional embedding space of trained deep models and that such space can be explored by interpolation or optimization to attain ready-to-use models. We find that it is possible to learn an embedding space of multiple instances of the same architecture and of multiple architectures. We address image classification and neural representation of signals, showing how our embedding space can be learnt so as to capture the notions of performance and 3D shape, respectively. In the Multi-Architecture setting we also show how an embedding trained only on a subset of architectures can learn to generate already-trained instances of architectures it never sees instantiated at training time.
Plugging Self-Supervised Monocular Depth into Unsupervised Domain Adaptation for Semantic Segmentation
Oct 13, 2021



Although recent semantic segmentation methods have made remarkable progress, they still rely on large amounts of annotated training data, which are often infeasible to collect in the autonomous driving scenario. Previous works usually tackle this issue with Unsupervised Domain Adaptation (UDA), which entails training a network on synthetic images and applying the model to real ones while minimizing the discrepancy between the two domains. Yet, these techniques do not consider additional information that may be obtained from other tasks. Differently, we propose to exploit self-supervised monocular depth estimation to improve UDA for semantic segmentation. On one hand, we deploy depth to realize a plug-in component which can inject complementary geometric cues into any existing UDA method. We further rely on depth to generate a large and varied set of samples to Self-Train the final model. Our whole proposal allows for achieving state-of-the-art performance (58.8 mIoU) in the GTA5->CS benchmark benchmark. Code is available at https://github.com/CVLAB-Unibo/d4-dbst.