 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformMaster: An Interactive Physics-Neural World Model for Deformable Objects from Videos
May 10, 2026World models for deformable objects should recover not only geometry and appearance, but also underlying physical dynamics, interaction grounding, and material behavior. Learning such a model from real videos is challenging because deformable linear, planar, and volumetric objects evolve under high-dimensional deformation, noisy interactions, and complex material response. The model must therefore infer a physical state from visual observations, roll it forward under new interactions, and render the resulting dynamics with high visual fidelity. We present DeformMaster, a video-derived interactive physics--neural world model that turns real interaction videos into an online interactive model of deformable objects within a unified dynamics-and-appearance framework. DeformMaster preserves structured physical rollout while using a neural residual to compensate for unmodeled effects, grounds sparse hand motion as distributed compliant actuator for hand--continuum interaction, represents material response with spatially varying constitutive experts, and drives high-fidelity 4D appearance from the predicted physical evolution. Experiments on real-world deformable-object sequences demonstrate DeformMaster's ability to roll out future dynamics and render dynamic appearance, outperforming state-of-the-art baselines while supporting novel action rollout, material-parameter variation, and dynamic novel-view synthesis.
Automated Counting of Stacked Objects in Industrial Inspection
Mar 16, 2026Visual object counting is a fundamental computer vision task in industrial inspection, where accurate, high-throughput inventory tracking and quality assurance are critical. Moreover, manufactured parts are often too light to reliably deduce their count from their weight, or too heavy to move the stack on a scale safely and practically, making automated visual counting the more robust solution in many scenarios. However, existing methods struggle with stacked 3D items in containers, pallets, or bins, where most objects are heavily occluded and only a few are directly visible. To address this important yet underexplored challenge, we propose a novel 3D counting approach that decomposes the task into two complementary subproblems: estimating the 3D geometry of the stack and its occupancy ratio from multi-view images. By combining geometric reconstruction with deep learning-based depth analysis, our method can accurately count identical manufactured parts inside containers, even when they are irregularly stacked and partially hidden. We validate our 3D counting pipeline on large-scale synthetic and diverse real-world data with manually verified total counts, demonstrating robust performance under realistic inspection conditions.
Spatio-Temporal Garment Reconstruction Using Diffusion Mapping via Pattern Coordinates
Feb 27, 2026Reconstructing 3D clothed humans from monocular images and videos is a fundamental problem with applications in virtual try-on, avatar creation, and mixed reality. Despite significant progress in human body recovery, accurately reconstructing garment geometry, particularly for loose-fitting clothing, remains an open challenge. We propose a unified framework for high-fidelity 3D garment reconstruction from both single images and video sequences. Our approach combines Implicit Sewing Patterns (ISP) with a generative diffusion model to learn expressive garment shape priors in 2D UV space. Leveraging these priors, we introduce a mapping model that establishes correspondences between image pixels, UV pattern coordinates, and 3D geometry, enabling accurate and detailed garment reconstruction from single images. We further extend this formulation to dynamic reconstruction by introducing a spatio-temporal diffusion scheme with test-time guidance to enforce long-range temporal consistency. We also develop analytic projection-based constraints that preserve image-aligned geometry in visible regions while enforcing coherent completion in occluded areas over time. Although trained exclusively on synthetically simulated cloth data, our method generalizes well to real-world imagery and consistently outperforms existing approaches on both tight- and loose-fitting garments. The reconstructed garments preserve fine geometric detail while exhibiting realistic dynamic motion, supporting downstream applications such as texture editing, garment retargeting, and animation.
BrainStack: Neuro-MoE with Functionally Guided Expert Routing for EEG-Based Language Decoding
Jan 29, 2026Decoding linguistic information from electroencephalography (EEG) remains challenging due to the brain's distributed and nonlinear organization. We present BrainStack, a functionally guided neuro-mixture-of-experts (Neuro-MoE) framework that models the brain's modular functional architecture through anatomically partitioned expert networks. Each functional region is represented by a specialized expert that learns localized neural dynamics, while a transformer-based global expert captures cross-regional dependencies. A learnable routing gate adaptively aggregates these heterogeneous experts, enabling context-dependent expert coordination and selective fusion. To promote coherent representation across the hierarchy, we introduce cross-regional distillation, where the global expert provides top-down regularization to the regional experts. We further release SilentSpeech-EEG (SS-EEG), a large-scale benchmark comprising over 120 hours of EEG recordings from 12 subjects performing 24 silent words, the largest dataset of its kind. Experiments demonstrate that BrainStack consistently outperforms state-of-the-art models, achieving superior accuracy and generalization across subjects. Our results establish BrainStack as a functionally modular, neuro-inspired MoE paradigm that unifies neuroscientific priors with adaptive expert routing, paving the way for scalable and interpretable brain-language decoding.
Learning Sewing Patterns via Latent Flow Matching of Implicit Fields
Jan 25, 2026Sewing patterns define the structural foundation of garments and are essential for applications such as fashion design, fabrication, and physical simulation. Despite progress in automated pattern generation, accurately modeling sewing patterns remains difficult due to the broad variability in panel geometry and seam arrangements. In this work, we introduce a sewing pattern modeling method based on an implicit representation. We represent each panel using a signed distance field that defines its boundary and an unsigned distance field that identifies seam endpoints, and encode these fields into a continuous latent space that enables differentiable meshing. A latent flow matching model learns distributions over panel combinations in this representation, and a stitching prediction module recovers seam relations from extracted edge segments. This formulation allows accurate modeling and generation of sewing patterns with complex structures. We further show that it can be used to estimate sewing patterns from images with improved accuracy relative to existing approaches, and supports applications such as pattern completion and refitting, providing a practical tool for digital fashion design.
Single View Garment Reconstruction Using Diffusion Mapping Via Pattern Coordinates
Apr 11, 2025Reconstructing 3D clothed humans from images is fundamental to applications like virtual try-on, avatar creation, and mixed reality. While recent advances have enhanced human body recovery, accurate reconstruction of garment geometry -- especially for loose-fitting clothing -- remains an open challenge. We present a novel method for high-fidelity 3D garment reconstruction from single images that bridges 2D and 3D representations. Our approach combines Implicit Sewing Patterns (ISP) with a generative diffusion model to learn rich garment shape priors in a 2D UV space. A key innovation is our mapping model that establishes correspondences between 2D image pixels, UV pattern coordinates, and 3D geometry, enabling joint optimization of both 3D garment meshes and the corresponding 2D patterns by aligning learned priors with image observations. Despite training exclusively on synthetically simulated cloth data, our method generalizes effectively to real-world images, outperforming existing approaches on both tight- and loose-fitting garments. The reconstructed garments maintain physical plausibility while capturing fine geometric details, enabling downstream applications including garment retargeting and texture manipulation.
Counting Stacked Objects from Multi-View Images
Nov 28, 2024



Visual object counting is a fundamental computer vision task underpinning numerous real-world applications, from cell counting in biomedicine to traffic and wildlife monitoring. However, existing methods struggle to handle the challenge of stacked 3D objects in which most objects are hidden by those above them. To address this important yet underexplored problem, we propose a novel 3D counting approach that decomposes the task into two complementary subproblems - estimating the 3D geometry of the object stack and the occupancy ratio from multi-view images. By combining geometric reconstruction and deep learning-based depth analysis, our method can accurately count identical objects within containers, even when they are irregularly stacked. We validate our 3D Counting pipeline on diverse real-world and large-scale synthetic datasets, which we will release publicly to facilitate further research.
DiscoNeRF: Class-Agnostic Object Field for 3D Object Discovery
Aug 19, 2024
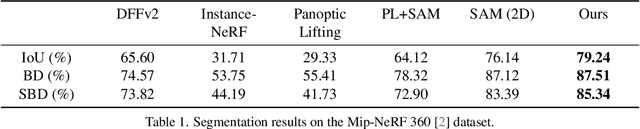
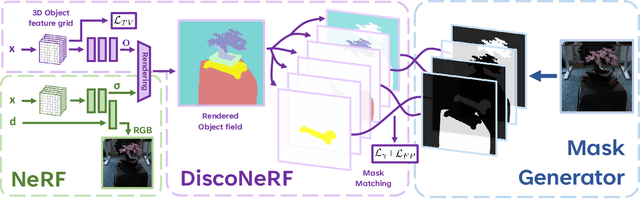
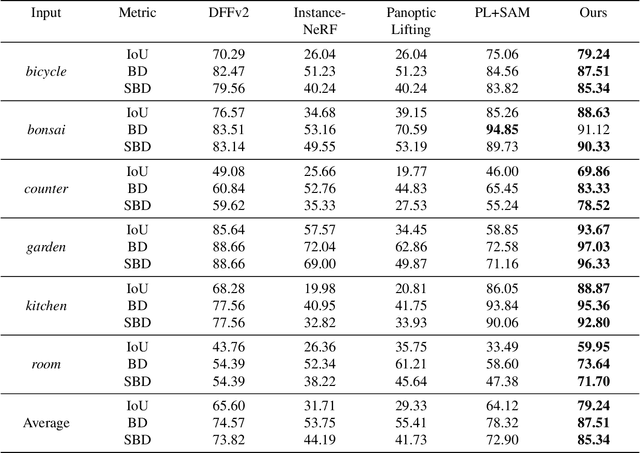
Neural Radiance Fields (NeRFs) have become a powerful tool for modeling 3D scenes from multiple images. However, NeRFs remain difficult to segment into semantically meaningful regions. Previous approaches to 3D segmentation of NeRFs either require user interaction to isolate a single object, or they rely on 2D semantic masks with a limited number of classes for supervision. As a consequence, they generalize poorly to class-agnostic masks automatically generated in real scenes. This is attributable to the ambiguity arising from zero-shot segmentation, yielding inconsistent masks across views. In contrast, we propose a method that is robust to inconsistent segmentations and successfully decomposes the scene into a set of objects of any class. By introducing a limited number of competing object slots against which masks are matched, a meaningful object representation emerges that best explains the 2D supervision and minimizes an additional regularization term. Our experiments demonstrate the ability of our method to generate 3D panoptic segmentations on complex scenes, and extract high-quality 3D assets from NeRFs that can then be used in virtual 3D environments.
Reconstruction of Manipulated Garment with Guided Deformation Prior
May 17, 2024
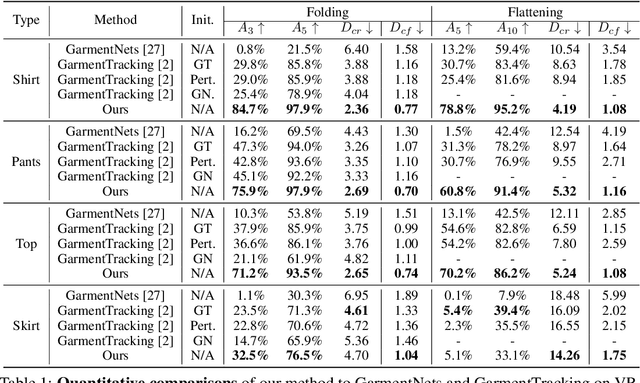
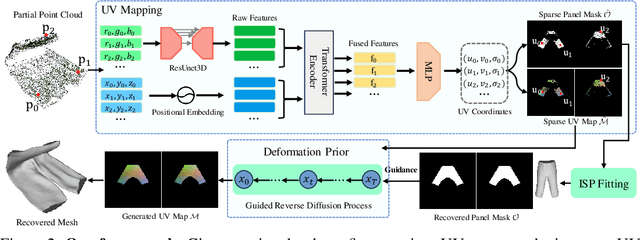

Modeling the shape of garments has received much attention, but most existing approaches assume the garments to be worn by someone, which constrains the range of shapes they can assume. In this work, we address shape recovery when garments are being manipulated instead of worn, which gives rise to an even larger range of possible shapes. To this end, we leverage the implicit sewing patterns (ISP) model for garment modeling and extend it by adding a diffusion-based deformation prior to represent these shapes. To recover 3D garment shapes from incomplete 3D point clouds acquired when the garment is folded, we map the points to UV space, in which our priors are learned, to produce partial UV maps, and then fit the priors to recover complete UV maps and 2D to 3D mappings. Experimental results demonstrate the superior reconstruction accuracy of our method compared to previous ones, especially when dealing with large non-rigid deformations arising from the manipulations.
Garment Recovery with Shape and Deformation Priors
Nov 17, 2023



While modeling people wearing tight-fitting clothing has made great strides in recent years, loose-fitting clothing remains a challenge. We propose a method that delivers realistic garment models from real-world images, regardless of garment shape or deformation. To this end, we introduce a fitting approach that utilizes shape and deformation priors learned from synthetic data to accurately capture garment shapes and deformations, including large ones. Not only does our approach recover the garment geometry accurately, it also yields models that can be directly used by downstream applications such as animation and simulation.