 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-Aware Multi-Behavior Dynamic Graph Transformer for Sequential Recommendation
Feb 11, 2026In the landscape of contemporary recommender systems, user-item interactions are inherently dynamic and sequential, often characterized by various behaviors. Prior research has explored the modeling of user preferences through sequential interactions and the user-item interaction graph, utilizing advanced techniques such as graph neural networks and transformer-based architectures. However, these methods typically fall short in simultaneously accounting for the dynamic nature of graph topologies and the sequential pattern of interactions in user preference models. Moreover, they often fail to adequately capture the multiple user behavior boundaries during model optimization. To tackle these challenges, we introduce a boundary-aware Multi-Behavioral Dynamic Graph Transformer (MB-DGT) model that dynamically refines the graph structure to reflect the evolving patterns of user behaviors and interactions. Our model involves a transformer-based dynamic graph aggregator for user preference modeling, which assimilates the changing graph structure and the sequence of user behaviors. This integration yields a more comprehensive and dynamic representation of user preferences. For model optimization, we implement a user-specific multi-behavior loss function that delineates the interest boundaries among different behaviors, thereby enriching the personalized learning of user preferences. Comprehensive experiments across three datasets indicate that our model consistently delivers remarkable recommendation performance.
GUIGuard: Toward a General Framework for Privacy-Preserving GUI Agents
Jan 26, 2026GUI agents enable end-to-end automation through direct perception of and interaction with on-screen interfaces. However, these agents frequently access interfaces containing sensitive personal information, and screenshots are often transmitted to remote models, creating substantial privacy risks. These risks are particularly severe in GUI workflows: GUIs expose richer, more accessible private information, and privacy risks depend on interaction trajectories across sequential scenes. We propose GUIGuard, a three-stage framework for privacy-preserving GUI agents: (1) privacy recognition, (2) privacy protection, and (3) task execution under protection. We further construct GUIGuard-Bench, a cross-platform benchmark with 630 trajectories and 13,830 screenshots, annotated with region-level privacy grounding and fine-grained labels of risk level, privacy category, and task necessity. Evaluations reveal that existing agents exhibit limited privacy recognition, with state-of-the-art models achieving only 13.3% accuracy on Android and 1.4% on PC. Under privacy protection, task-planning semantics can still be maintained, with closed-source models showing stronger semantic consistency than open-source ones. Case studies on MobileWorld show that carefully designed protection strategies achieve higher task accuracy while preserving privacy. Our results highlight privacy recognition as a critical bottleneck for practical GUI agents. Project: https://futuresis.github.io/GUIGuard-page/
Beyond Models! Explainable Data Valuation and Metric Adaption for Recommendation
Feb 12, 2025User behavior records serve as the foundation for recommender systems. While the behavior data exhibits ease of acquisition, it often suffers from varying quality. Current methods employ data valuation to discern high-quality data from low-quality data. However, they tend to employ black-box design, lacking transparency and interpretability. Besides, they are typically tailored to specific evaluation metrics, leading to limited generality across various tasks. To overcome these issues, we propose an explainable and versatile framework DVR which can enhance the efficiency of data utilization tailored to any requirements of the model architectures and evaluation metrics. For explainable data valuation, a data valuator is presented to evaluate the data quality via calculating its Shapley value from the game-theoretic perspective, ensuring robust mathematical properties and reliability. In order to accommodate various evaluation metrics, including differentiable and non-differentiable ones, a metric adapter is devised based on reinforcement learning, where a metric is treated as the reinforcement reward that guides model optimization. Extensive experiments conducted on various benchmarks verify that our framework can improve the performance of current recommendation algorithms on various metrics including ranking accuracy, diversity, and fairness. Specifically, our framework achieves up to 34.7\% improvements over existing methods in terms of representative NDCG metric. The code is available at https://github.com/renqii/DVR.
Cognitive Personalized Search Integrating Large Language Models with an Efficient Memory Mechanism
Feb 16, 2024



Traditional search engines usually provide identical search results for all users, overlooking individual preferences. To counter this limitation, personalized search has been developed to re-rank results based on user preferences derived from query logs. Deep learning-based personalized search methods have shown promise, but they rely heavily on abundant training data, making them susceptible to data sparsity challenges. This paper proposes a Cognitive Personalized Search (CoPS) model, which integrates Large Language Models (LLMs) with a cognitive memory mechanism inspired by human cognition. CoPS employs LLMs to enhance user modeling and user search experience. The cognitive memory mechanism comprises sensory memory for quick sensory responses, working memory for sophisticated cognitive responses, and long-term memory for storing historical interactions. CoPS handles new queries using a three-step approach: identifying re-finding behaviors, constructing user profiles with relevant historical information, and ranking documents based on personalized query intent. Experiments show that CoPS outperforms baseline models in zero-shot scenarios.
CMMU: A Benchmark for Chinese Multi-modal Multi-type Question Understanding and Reasoning
Jan 26, 2024


Multi-modal large language models(MLLMs) have achieved remarkable progress and demonstrated powerful knowledge comprehension and reasoning abilities. However, the mastery of domain-specific knowledge, which is essential for evaluating the intelligence of MLLMs, continues to be a challenge. Current multi-modal benchmarks for domain-specific knowledge concentrate on multiple-choice questions and are predominantly available in English, which imposes limitations on the comprehensiveness of the evaluation. To this end, we introduce CMMU, a novel benchmark for multi-modal and multi-type question understanding and reasoning in Chinese. CMMU consists of 3,603 questions in 7 subjects, covering knowledge from primary to high school. The questions can be categorized into 3 types: multiple-choice, multiple-response, and fill-in-the-blank, bringing greater challenges to MLLMs. In addition, we propose a rigorous evaluation strategy called ShiftCheck for assessing multiple-choice questions. The strategy aims to reduce position bias, minimize the influence of randomness on correctness, and perform a quantitative analysis of position bias. We evaluate seven open-source MLLMs along with GPT4-V, Gemini-Pro, and Qwen-VL-Plus. The results demonstrate that CMMU poses a significant challenge to the recent MLLMs.
Learning Explicit User Interest Boundary for Recommendation
Nov 22, 2021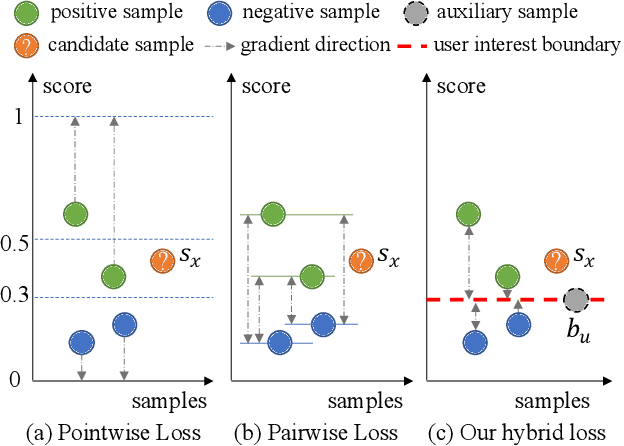

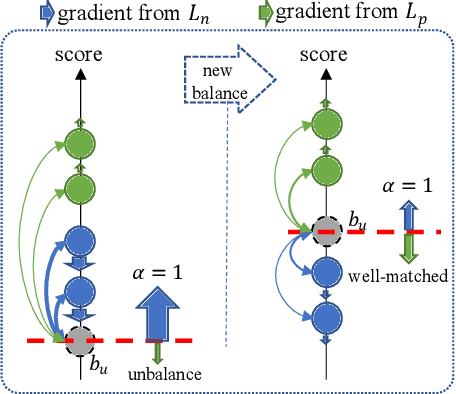

The core objective of modelling recommender systems from implicit feedback is to maximize the positive sample score $s_p$ and minimize the negative sample score $s_n$, which can usually be summarized into two paradigms: the pointwise and the pairwise. The pointwise approaches fit each sample with its label individually, which is flexible in weighting and sampling on instance-level but ignores the inherent ranking property. By qualitatively minimizing the relative score $s_n - s_p$, the pairwise approaches capture the ranking of samples naturally but suffer from training efficiency. Additionally, both approaches are hard to explicitly provide a personalized decision boundary to determine if users are interested in items unseen. To address those issues, we innovatively introduce an auxiliary score $b_u$ for each user to represent the User Interest Boundary(UIB) and individually penalize samples that cross the boundary with pairwise paradigms, i.e., the positive samples whose score is lower than $b_u$ and the negative samples whose score is higher than $b_u$. In this way, our approach successfully achieves a hybrid loss of the pointwise and the pairwise to combine the advantages of both. Analytically, we show that our approach can provide a personalized decision boundary and significantly improve the training efficiency without any special sampling strategy. Extensive results show that our approach achieves significant improvements on not only the classical pointwise or pairwise models but also state-of-the-art models with complex loss function and complicated feature encoding.
Is There More Pattern in Knowledge Graph? Exploring Proximity Pattern for Knowledge Graph Embedding
Oct 02, 2021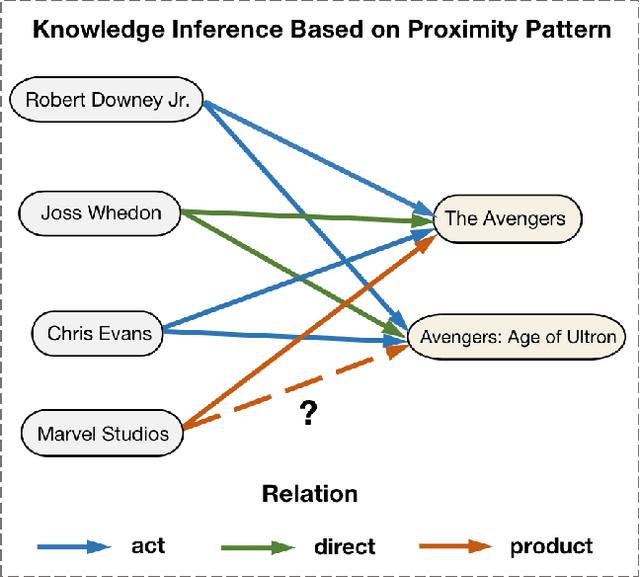

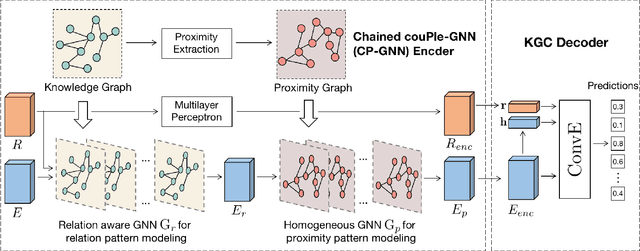
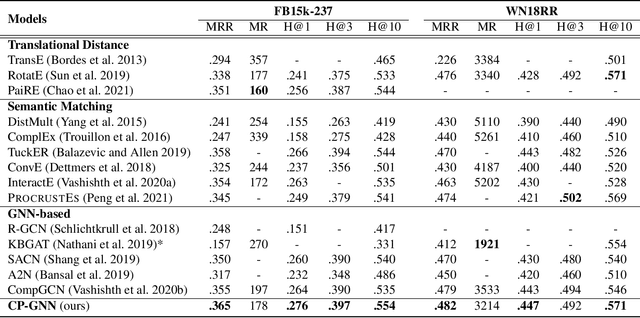
Modeling of relation pattern is the core focus of previous Knowledge Graph Embedding works, which represents how one entity is related to another semantically by some explicit relation. However, there is a more natural and intuitive relevancy among entities being always ignored, which is that how one entity is close to another semantically, without the consideration of any explicit relation. We name such semantic phenomenon in knowledge graph as proximity pattern. In this work, we explore the problem of how to define and represent proximity pattern, and how it can be utilized to help knowledge graph embedding. Firstly, we define the proximity of any two entities according to their statistically shared queries, then we construct a derived graph structure and represent the proximity pattern from global view. Moreover, with the original knowledge graph, we design a Chained couPle-GNN (CP-GNN) architecture to deeply merge the two patterns (graphs) together, which can encode a more comprehensive knowledge embedding. Being evaluated on FB15k-237 and WN18RR datasets, CP-GNN achieves state-of-the-art results for Knowledge Graph Completion task, and can especially boost the modeling capacity for complex queries that contain multiple answer entities, proving the effectiveness of introduced proximity pattern.
How Does Knowledge Graph Embedding Extrapolate to Unseen Data: a Semantic Evidence View
Sep 24, 2021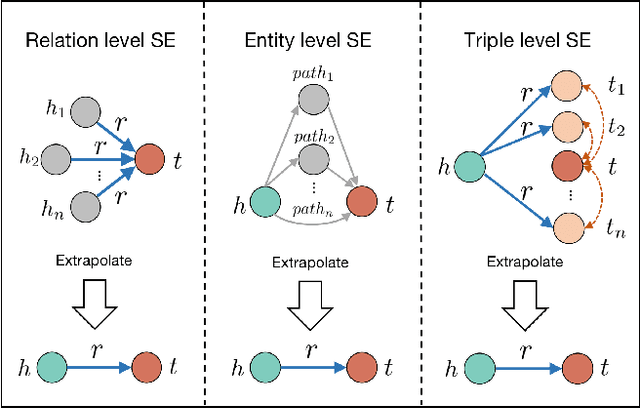
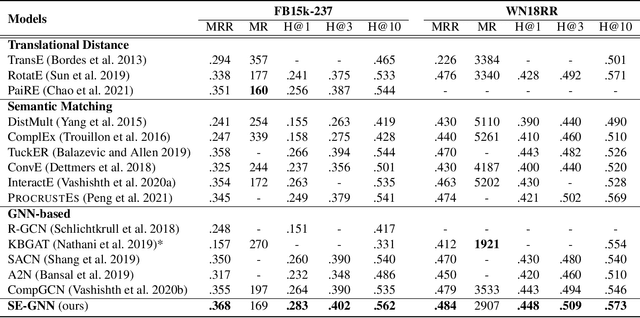
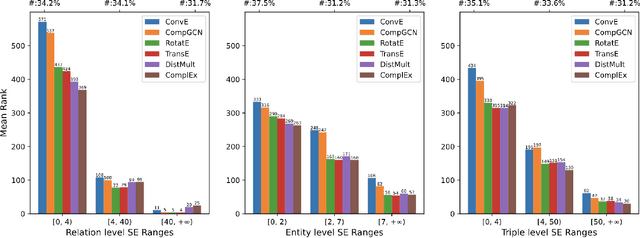
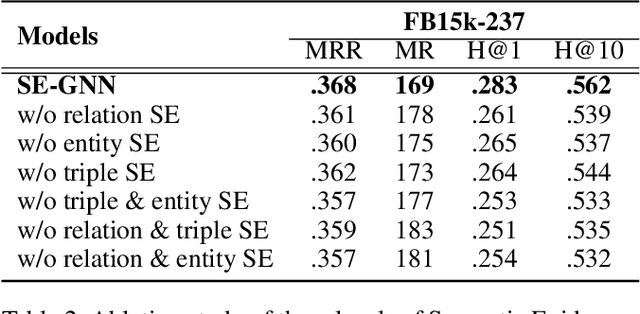
Knowledge Graph Embedding (KGE) aims to learn representations for entities and relations. Most KGE models have gained great success, especially on extrapolation scenarios. Specifically, given an unseen triple (h, r, t), a trained model can still correctly predict t from (h, r, ?), or h from (?, r, t), such extrapolation ability is impressive. However, most existing KGE works focus on the design of delicate triple modeling function, which mainly tell us how to measure the plausibility of observed triples, but we have limited understanding of why the methods can extrapolate to unseen data, and what are the important factors to help KGE extrapolate. Therefore in this work, we attempt to, from a data relevant view, study KGE extrapolation of two problems: 1. How does KGE extrapolate to unseen data? 2. How to design the KGE model with better extrapolation ability? For the problem 1, we first discuss the impact factors for extrapolation and from relation, entity and triple level respectively, propose three Semantic Evidences (SEs), which can be observed from training set and provide important semantic information for extrapolation to unseen data. Then we verify the effectiveness of SEs through extensive experiments on several typical KGE methods, and demonstrate that SEs serve as an important role for understanding the extrapolation ability of KGE. For the problem 2, to make better use of the SE information for more extrapolative knowledge representation, we propose a novel GNN-based KGE model, called Semantic Evidence aware Graph Neural Network (SE-GNN). Finally, through extensive experiments on FB15k-237 and WN18RR datasets, we show that SE-GNN achieves state-of-the-art performance on Knowledge Graph Completion task and perform a better extrapolation ability.