 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantEval: A Benchmark for Financial Quantitative Tasks in Large Language Models
Jan 13, 2026Large Language Models (LLMs) have shown strong capabilities across many domains, yet their evaluation in financial quantitative tasks remains fragmented and mostly limited to knowledge-centric question answering. We introduce QuantEval, a benchmark that evaluates LLMs across three essential dimensions of quantitative finance: knowledge-based QA, quantitative mathematical reasoning, and quantitative strategy coding. Unlike prior financial benchmarks, QuantEval integrates a CTA-style backtesting framework that executes model-generated strategies and evaluates them using financial performance metrics, enabling a more realistic assessment of quantitative coding ability. We evaluate some state-of-the-art open-source and proprietary LLMs and observe substantial gaps to human experts, particularly in reasoning and strategy coding. Finally, we conduct large-scale supervised fine-tuning and reinforcement learning experiments on domain-aligned data, demonstrating consistent improvements. We hope QuantEval will facilitate research on LLMs' quantitative finance capabilities and accelerate their practical adoption in real-world trading workflows. We additionally release the full deterministic backtesting configuration (asset universe, cost model, and metric definitions) to ensure strict reproducibility.
LaoBench: A Large-Scale Multidimensional Lao Benchmark for Large Language Models
Nov 14, 2025The rapid advancement of large language models (LLMs) has not been matched by their evaluation in low-resource languages, especially Southeast Asian languages like Lao. To fill this gap, we introduce LaoBench, the first large-scale, high-quality, and multidimensional benchmark dataset dedicated to assessing LLMs' comprehensive language understanding and reasoning abilities in Lao. LaoBench comprises over 17,000 carefully curated samples spanning three core dimensions: knowledge application, K12 foundational education, and bilingual translation among Lao, Chinese, and English. The dataset is divided into open-source and closed-source subsets, with the closed-source portion enabling black-box evaluation on an official platform to ensure fairness and data security. Our data construction pipeline integrates expert human curation with automated agent-assisted verification, ensuring linguistic accuracy, cultural relevance, and educational value. Benchmarking multiple state-of-the-art LLMs on LaoBench reveals that current models still face significant challenges in mastering Lao across diverse tasks. We hope LaoBench will catalyze further research and development of AI technologies for underrepresented Southeast Asian languages.
FlagEvalMM: A Flexible Framework for Comprehensive Multimodal Model Evaluation
Jun 10, 2025We present FlagEvalMM, an open-source evaluation framework designed to comprehensively assess multimodal models across a diverse range of vision-language understanding and generation tasks, such as visual question answering, text-to-image/video generation, and image-text retrieval. We decouple model inference from evaluation through an independent evaluation service, thus enabling flexible resource allocation and seamless integration of new tasks and models. Moreover, FlagEvalMM utilizes advanced inference acceleration tools (e.g., vLLM, SGLang) and asynchronous data loading to significantly enhance evaluation efficiency. Extensive experiments show that FlagEvalMM offers accurate and efficient insights into model strengths and limitations, making it a valuable tool for advancing multimodal research. The framework is publicly accessible athttps://github.com/flageval-baai/FlagEvalMM.
Memorization or Reasoning? Exploring the Idiom Understanding of LLMs
May 22, 2025Idioms have long posed a challenge due to their unique linguistic properties, which set them apart from other common expressions. While recent studies have leveraged large language models (LLMs) to handle idioms across various tasks, e.g., idiom-containing sentence generation and idiomatic machine translation, little is known about the underlying mechanisms of idiom processing in LLMs, particularly in multilingual settings. To this end, we introduce MIDAS, a new large-scale dataset of idioms in six languages, each paired with its corresponding meaning. Leveraging this resource, we conduct a comprehensive evaluation of LLMs' idiom processing ability, identifying key factors that influence their performance. Our findings suggest that LLMs rely not only on memorization, but also adopt a hybrid approach that integrates contextual cues and reasoning, especially when processing compositional idioms. This implies that idiom understanding in LLMs emerges from an interplay between internal knowledge retrieval and reasoning-based inference.
HalluDial: A Large-Scale Benchmark for Automatic Dialogue-Level Hallucination Evaluation
Jun 11, 2024



Large Language Models (LLMs) have significantly advanced the field of Natural Language Processing (NLP), achieving remarkable performance across diverse tasks and enabling widespread real-world applications. However, LLMs are prone to hallucination, generating content that either conflicts with established knowledge or is unfaithful to the original sources. Existing hallucination benchmarks primarily focus on sentence- or passage-level hallucination detection, neglecting dialogue-level evaluation, hallucination localization, and rationale provision. They also predominantly target factuality hallucinations while underestimating faithfulness hallucinations, often relying on labor-intensive or non-specialized evaluators. To address these limitations, we propose HalluDial, the first comprehensive large-scale benchmark for automatic dialogue-level hallucination evaluation. HalluDial encompasses both spontaneous and induced hallucination scenarios, covering factuality and faithfulness hallucinations. The benchmark includes 4,094 dialogues with a total of 146,856 samples. Leveraging HalluDial, we conduct a comprehensive meta-evaluation of LLMs' hallucination evaluation capabilities in information-seeking dialogues and introduce a specialized judge language model, HalluJudge. The high data quality of HalluDial enables HalluJudge to achieve superior or competitive performance in hallucination evaluation, facilitating the automatic assessment of dialogue-level hallucinations in LLMs and providing valuable insights into this phenomenon. The dataset and the code are available at https://github.com/FlagOpen/HalluDial.
Bi-DCSpell: A Bi-directional Detector-Corrector Interactive Framework for Chinese Spelling Check
Jun 04, 2024



Chinese Spelling Check (CSC) aims to detect and correct potentially misspelled characters in Chinese sentences. Naturally, it involves the detection and correction subtasks, which interact with each other dynamically. Such interactions are bi-directional, i.e., the detection result would help reduce the risk of over-correction and under-correction while the knowledge learnt from correction would help prevent false detection. Current CSC approaches are of two types: correction-only or single-directional detection-to-correction interactive frameworks. Nonetheless, they overlook the bi-directional interactions between detection and correction. This paper aims to fill the gap by proposing a Bi-directional Detector-Corrector framework for CSC (Bi-DCSpell). Notably, Bi-DCSpell contains separate detection and correction encoders, followed by a novel interactive learning module facilitating bi-directional feature interactions between detection and correction to improve each other's representation learning. Extensive experimental results demonstrate a robust correction performance of Bi-DCSpell on widely used benchmarking datasets while possessing a satisfactory detection ability.
CMMU: A Benchmark for Chinese Multi-modal Multi-type Question Understanding and Reasoning
Jan 26, 2024

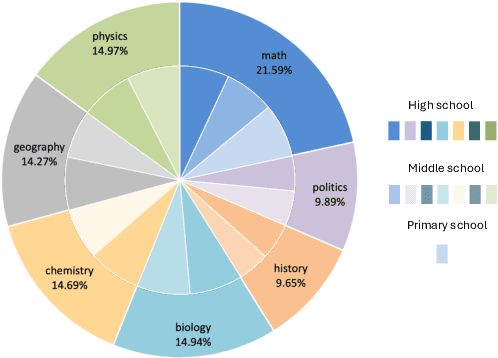

Multi-modal large language models(MLLMs) have achieved remarkable progress and demonstrated powerful knowledge comprehension and reasoning abilities. However, the mastery of domain-specific knowledge, which is essential for evaluating the intelligence of MLLMs, continues to be a challenge. Current multi-modal benchmarks for domain-specific knowledge concentrate on multiple-choice questions and are predominantly available in English, which imposes limitations on the comprehensiveness of the evaluation. To this end, we introduce CMMU, a novel benchmark for multi-modal and multi-type question understanding and reasoning in Chinese. CMMU consists of 3,603 questions in 7 subjects, covering knowledge from primary to high school. The questions can be categorized into 3 types: multiple-choice, multiple-response, and fill-in-the-blank, bringing greater challenges to MLLMs. In addition, we propose a rigorous evaluation strategy called ShiftCheck for assessing multiple-choice questions. The strategy aims to reduce position bias, minimize the influence of randomness on correctness, and perform a quantitative analysis of position bias. We evaluate seven open-source MLLMs along with GPT4-V, Gemini-Pro, and Qwen-VL-Plus. The results demonstrate that CMMU poses a significant challenge to the recent MLLMs.