 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Transcription: Unified Audio Schema for Perception-Aware AudioLLMs
Apr 14, 2026Recent Audio Large Language Models (AudioLLMs) exhibit a striking performance inversion: while excelling at complex reasoning tasks, they consistently underperform on fine-grained acoustic perception. We attribute this gap to a fundamental limitation of ASR-centric training, which provides precise linguistic targets but implicitly teaches models to suppress paralinguistic cues and acoustic events as noise. To address this, we propose Unified Audio Schema (UAS), a holistic and structured supervision framework that organizes audio information into three explicit components -- Transcription, Paralinguistics, and Non-linguistic Events -- within a unified JSON format. This design achieves comprehensive acoustic coverage without sacrificing the tight audio-text alignment that enables reasoning. We validate the effectiveness of this supervision strategy by applying it to both discrete and continuous AudioLLM architectures. Extensive experiments on MMSU, MMAR, and MMAU demonstrate that UAS-Audio yields consistent improvements, boosting fine-grained perception by 10.9% on MMSU over the same-size state-of-the-art models while preserving robust reasoning capabilities. Our code and model are publicly available at https://github.com/Tencent/Unified_Audio_Schema.
Measuring and Mitigating Post-hoc Rationalization in Reverse Chain-of-Thought Generation
Feb 16, 2026Reverse Chain-of-Thought Generation (RCG) synthesizes reasoning traces from query-answer pairs, but runs the risk of producing post-hoc rationalizations: when models can see the answer during generation, the answer serves as a cognitive anchor that shapes the entire explanation. We formalize this phenomenon through a three-level measurement hierarchy: lexical, entropic, and probabilistic anchoring, each captures surface artifacts, entropy dynamics, and latent answer dependence, respectively. We analyze semantic suppression, the intuitive mitigation strategy that instructs models to ignore the answer, to find out its counterproduction: while it reduces lexical overlap, it paradoxically increases entropic and probabilistic anchoring. Drawing on Ironic Process Theory from cognitive psychology, we attribute this failure to active monitoring of the forbidden answer, which inadvertently deepens dependence on it. To break this cycle, we propose Structural Skeleton-guided Reasoning (SSR), a two-phase approach that first generates an answer-invariant functional skeleton structure, then uses this skeleton to guide full trace generation. By redirecting the information flow to structural planning rather than answer monitoring, SSR consistently reduces anchoring across all three levels. We further introduce Distilled SSR (SSR-D), which fine-tunes models on teacher-generated SSR traces to ensure reliable structural adherence. Experiments across open-ended reasoning benchmarks demonstrate that SSR-D achieves up to 10% improvement over suppression baselines while preserving out-of-distribution (OOD) generalization.
Two Pathways to Truthfulness: On the Intrinsic Encoding of LLM Hallucinations
Jan 12, 2026Despite their impressive capabilities, large language models (LLMs) frequently generate hallucinations. Previous work shows that their internal states encode rich signals of truthfulness, yet the origins and mechanisms of these signals remain unclear. In this paper, we demonstrate that truthfulness cues arise from two distinct information pathways: (1) a Question-Anchored pathway that depends on question-answer information flow, and (2) an Answer-Anchored pathway that derives self-contained evidence from the generated answer itself. First, we validate and disentangle these pathways through attention knockout and token patching. Afterwards, we uncover notable and intriguing properties of these two mechanisms. Further experiments reveal that (1) the two mechanisms are closely associated with LLM knowledge boundaries; and (2) internal representations are aware of their distinctions. Finally, building on these insightful findings, two applications are proposed to enhance hallucination detection performance. Overall, our work provides new insight into how LLMs internally encode truthfulness, offering directions for more reliable and self-aware generative systems.
Mitigating Overthinking through Reasoning Shaping
Oct 10, 2025Large reasoning models (LRMs) boosted by Reinforcement Learning from Verifier Reward (RLVR) have shown great power in problem solving, yet they often cause overthinking: excessive, meandering reasoning that inflates computational cost. Prior designs of penalization in RLVR manage to reduce token consumption while often harming model performance, which arises from the oversimplicity of token-level supervision. In this paper, we argue that the granularity of supervision plays a crucial role in balancing efficiency and accuracy, and propose Group Relative Segment Penalization (GRSP), a step-level method to regularize reasoning. Since preliminary analyses show that reasoning segments are strongly correlated with token consumption and model performance, we design a length-aware weighting mechanism across segment clusters. Extensive experiments demonstrate that GRSP achieves superior token efficiency without heavily compromising accuracy, especially the advantages with harder problems. Moreover, GRSP stabilizes RL training and scales effectively across model sizes.
StableToken: A Noise-Robust Semantic Speech Tokenizer for Resilient SpeechLLMs
Sep 26, 2025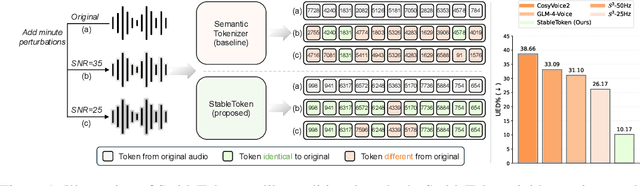
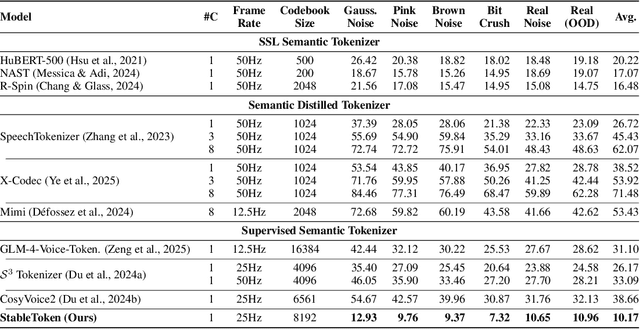
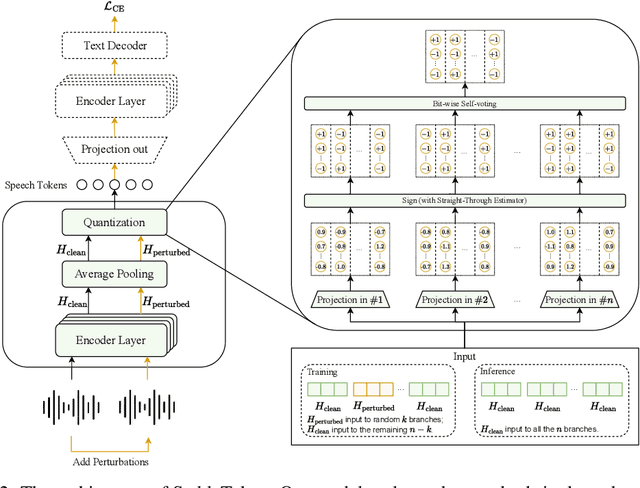

Prevalent semantic speech tokenizers, designed to capture linguistic content, are surprisingly fragile. We find they are not robust to meaning-irrelevant acoustic perturbations; even at high Signal-to-Noise Ratios (SNRs) where speech is perfectly intelligible, their output token sequences can change drastically, increasing the learning burden for downstream LLMs. This instability stems from two flaws: a brittle single-path quantization architecture and a distant training signal indifferent to intermediate token stability. To address this, we introduce StableToken, a tokenizer that achieves stability through a consensus-driven mechanism. Its multi-branch architecture processes audio in parallel, and these representations are merged via a powerful bit-wise voting mechanism to form a single, stable token sequence. StableToken sets a new state-of-the-art in token stability, drastically reducing Unit Edit Distance (UED) under diverse noise conditions. This foundational stability translates directly to downstream benefits, significantly improving the robustness of SpeechLLMs on a variety of tasks.
P-Aligner: Enabling Pre-Alignment of Language Models via Principled Instruction Synthesis
Aug 06, 2025
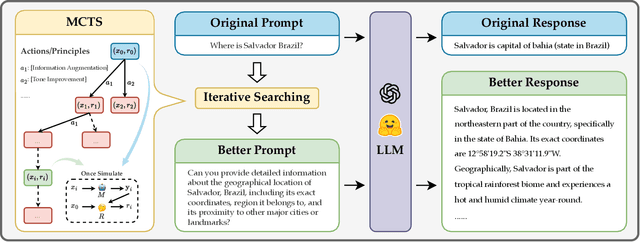
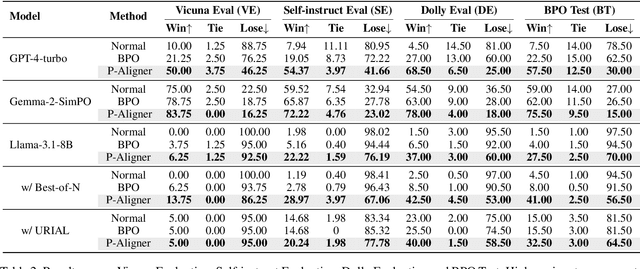
Large Language Models (LLMs) are expected to produce safe, helpful, and honest content during interaction with human users, but they frequently fail to align with such values when given flawed instructions, e.g., missing context, ambiguous directives, or inappropriate tone, leaving substantial room for improvement along multiple dimensions. A cost-effective yet high-impact way is to pre-align instructions before the model begins decoding. Existing approaches either rely on prohibitive test-time search costs or end-to-end model rewrite, which is powered by a customized training corpus with unclear objectives. In this work, we demonstrate that the goal of efficient and effective preference alignment can be achieved by P-Aligner, a lightweight module generating instructions that preserve the original intents while being expressed in a more human-preferred form. P-Aligner is trained on UltraPrompt, a new dataset synthesized via a proposed principle-guided pipeline using Monte-Carlo Tree Search, which systematically explores the space of candidate instructions that are closely tied to human preference. Experiments across different methods show that P-Aligner generally outperforms strong baselines across various models and benchmarks, including average win-rate gains of 28.35% and 8.69% on GPT-4-turbo and Gemma-2-SimPO, respectively. Further analyses validate its effectiveness and efficiency through multiple perspectives, including data quality, search strategies, iterative deployment, and time overhead.
Well Begun is Half Done: Low-resource Preference Alignment by Weak-to-Strong Decoding
Jun 09, 2025



Large Language Models (LLMs) require alignment with human preferences to avoid generating offensive, false, or meaningless content. Recently, low-resource methods for LLM alignment have been popular, while still facing challenges in obtaining both high-quality and aligned content. Motivated by the observation that the difficulty of generating aligned responses is concentrated at the beginning of decoding, we propose a novel framework, Weak-to-Strong Decoding (WSD), to enhance the alignment ability of base models by the guidance of a small aligned model. The small model first drafts well-aligned beginnings, followed by the large base model to continue the rest, controlled by a well-designed auto-switch mechanism. We also collect a new dataset, GenerAlign, to fine-tune a small-sized Pilot-3B as the draft model, which effectively enhances different base models under the WSD framework to outperform all baseline methods, while avoiding degradation on downstream tasks, termed as the alignment tax. Extensive experiments are further conducted to examine the impact of different settings and time efficiency, as well as analyses on the intrinsic mechanisms of WSD in depth.
TIME: A Multi-level Benchmark for Temporal Reasoning of LLMs in Real-World Scenarios
May 19, 2025Temporal reasoning is pivotal for Large Language Models (LLMs) to comprehend the real world. However, existing works neglect the real-world challenges for temporal reasoning: (1) intensive temporal information, (2) fast-changing event dynamics, and (3) complex temporal dependencies in social interactions. To bridge this gap, we propose a multi-level benchmark TIME, designed for temporal reasoning in real-world scenarios. TIME consists of 38,522 QA pairs, covering 3 levels with 11 fine-grained sub-tasks. This benchmark encompasses 3 sub-datasets reflecting different real-world challenges: TIME-Wiki, TIME-News, and TIME-Dial. We conduct extensive experiments on reasoning models and non-reasoning models. And we conducted an in-depth analysis of temporal reasoning performance across diverse real-world scenarios and tasks, and summarized the impact of test-time scaling on temporal reasoning capabilities. Additionally, we release TIME-Lite, a human-annotated subset to foster future research and standardized evaluation in temporal reasoning. The code is available at https://github.com/sylvain-wei/TIME , and the dataset is available at https://huggingface.co/datasets/SylvainWei/TIME .
Odysseus Navigates the Sirens' Song: Dynamic Focus Decoding for Factual and Diverse Open-Ended Text Generation
Mar 11, 2025Large Language Models (LLMs) are increasingly required to generate text that is both factually accurate and diverse across various open-ended applications. However, current stochastic decoding methods struggle to balance such objectives. We introduce Dynamic Focus Decoding (DFD), a novel plug-and-play stochastic approach that resolves this trade-off without requiring additional data, knowledge, or models. DFD adaptively adjusts the decoding focus based on distributional differences across layers, leveraging the modular and hierarchical nature of factual knowledge within LLMs. This dynamic adjustment improves factuality in knowledge-intensive decoding steps and promotes diversity in less knowledge-reliant steps. DFD can be easily integrated with existing decoding methods, enhancing both factuality and diversity with minimal computational overhead. Extensive experiments across seven datasets demonstrate that DFD significantly improves performance, providing a scalable and efficient solution for open-ended text generation.
FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation
Mar 09, 2025Implementing new features in repository-level codebases is a crucial application of code generation models. However, current benchmarks lack a dedicated evaluation framework for this capability. To fill this gap, we introduce FEA-Bench, a benchmark designed to assess the ability of large language models (LLMs) to perform incremental development within code repositories. We collect pull requests from 83 GitHub repositories and use rule-based and intent-based filtering to construct task instances focused on new feature development. Each task instance containing code changes is paired with relevant unit test files to ensure that the solution can be verified. The feature implementation requires LLMs to simultaneously possess code completion capabilities for new components and code editing abilities for other relevant parts in the code repository, providing a more comprehensive evaluation method of LLMs' automated software engineering capabilities. Experimental results show that LLMs perform significantly worse in the FEA-Bench, highlighting considerable challenges in such repository-level incremental code development.