 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluDial: A Large-Scale Benchmark for Automatic Dialogue-Level Hallucination Evaluation
Jun 11, 2024



Large Language Models (LLMs) have significantly advanced the field of Natural Language Processing (NLP), achieving remarkable performance across diverse tasks and enabling widespread real-world applications. However, LLMs are prone to hallucination, generating content that either conflicts with established knowledge or is unfaithful to the original sources. Existing hallucination benchmarks primarily focus on sentence- or passage-level hallucination detection, neglecting dialogue-level evaluation, hallucination localization, and rationale provision. They also predominantly target factuality hallucinations while underestimating faithfulness hallucinations, often relying on labor-intensive or non-specialized evaluators. To address these limitations, we propose HalluDial, the first comprehensive large-scale benchmark for automatic dialogue-level hallucination evaluation. HalluDial encompasses both spontaneous and induced hallucination scenarios, covering factuality and faithfulness hallucinations. The benchmark includes 4,094 dialogues with a total of 146,856 samples. Leveraging HalluDial, we conduct a comprehensive meta-evaluation of LLMs' hallucination evaluation capabilities in information-seeking dialogues and introduce a specialized judge language model, HalluJudge. The high data quality of HalluDial enables HalluJudge to achieve superior or competitive performance in hallucination evaluation, facilitating the automatic assessment of dialogue-level hallucinations in LLMs and providing valuable insights into this phenomenon. The dataset and the code are available at https://github.com/FlagOpen/HalluDial.
Within-basket Recommendation via Neural Pattern Associator
Jan 25, 2024
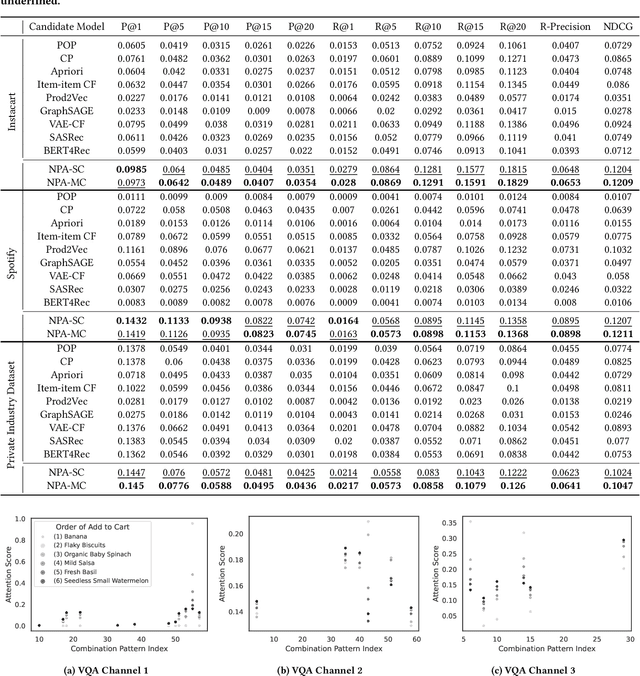
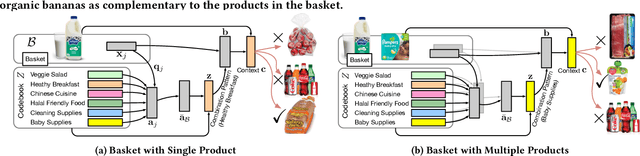

Within-basket recommendation (WBR) refers to the task of recommending items to the end of completing a non-empty shopping basket during a shopping session. While the latest innovations in this space demonstrate remarkable performance improvement on benchmark datasets, they often overlook the complexity of user behaviors in practice, such as 1) co-existence of multiple shopping intentions, 2) multi-granularity of such intentions, and 3) interleaving behavior (switching intentions) in a shopping session. This paper presents Neural Pattern Associator (NPA), a deep item-association-mining model that explicitly models the aforementioned factors. Specifically, inspired by vector quantization, the NPA model learns to encode common user intentions (or item-combination patterns) as quantized representations (a.k.a. codebook), which permits identification of users's shopping intentions via attention-driven lookup during the reasoning phase. This yields coherent and self-interpretable recommendations. We evaluated the proposed NPA model across multiple extensive datasets, encompassing the domains of grocery e-commerce (shopping basket completion) and music (playlist extension), where our quantitative evaluations show that the NPA model significantly outperforms a wide range of existing WBR solutions, reflecting the benefit of explicitly modeling complex user intentions.
Unintended Bias in Language Model-driven Conversational Recommendation
Jan 19, 2022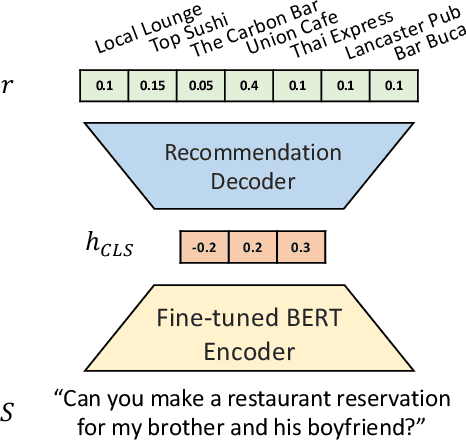


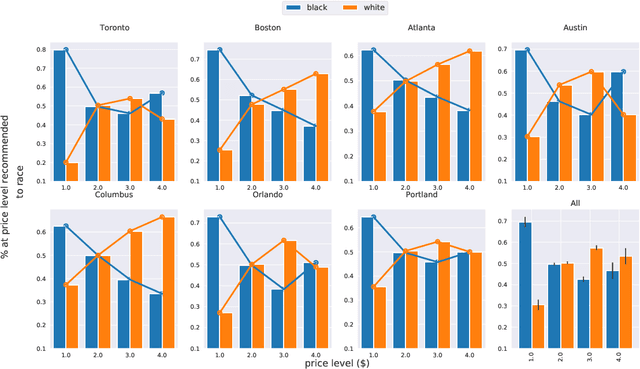
Conversational Recommendation Systems (CRSs) have recently started to leverage pretrained language models (LM) such as BERT for their ability to semantically interpret a wide range of preference statement variations. However, pretrained LMs are well-known to be prone to intrinsic biases in their training data, which may be exacerbated by biases embedded in domain-specific language data(e.g., user reviews) used to fine-tune LMs for CRSs. We study a recently introduced LM-driven recommendation backbone (termed LMRec) of a CRS to investigate how unintended bias i.e., language variations such as name references or indirect indicators of sexual orientation or location that should not affect recommendations manifests in significantly shifted price and category distributions of restaurant recommendations. The alarming results we observe strongly indicate that LMRec has learned to reinforce harmful stereotypes through its recommendations. For example, offhand mention of names associated with the black community significantly lowers the price distribution of recommended restaurants, while offhand mentions of common male-associated names lead to an increase in recommended alcohol-serving establishments. These and many related results presented in this work raise a red flag that advances in the language handling capability of LM-drivenCRSs do not come without significant challenges related to mitigating unintended bias in future deployed CRS assistants with a potential reach of hundreds of millions of end-users.