 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Failure Modes in Two-Stage Human-Object Interaction Detection
Apr 15, 2026Human-object interaction (HOI) detection aims to detect interactions between humans and objects in images. While recent advances have improved performance on existing benchmarks, their evaluations mainly focus on overall prediction accuracy and provide limited insight into the underlying causes of model failures. In particular, modern models often struggle in complex scenes involving multiple people and rare interaction combinations. In this work, we present a study to better understand the failure modes of two-stage HOI models, which form the basis of many current HOI detection approaches. Rather than constructing a large-scale benchmark, we instead decompose HOI detection into multiple interpretable perspectives and analyze model behavior across these dimensions to study different types of failure patterns. We curate a subset of images from an existing HOI dataset organized by human-object-interaction configurations (e.g., multi-person interactions and object sharing), and analyze model behavior under these configurations to examine different failure modes. This design allows us to analyze how these HOI models behave under different scene compositions and why their predictions fail. Importantly, high overall benchmark performance does not necessarily reflect robust visual reasoning about human-object relationships. We hope that this study can provide useful insights into the limitations of HOI models and offer observations for future research in this area.
Lessons and Open Questions from a Unified Study of Camera-Trap Species Recognition Over Time
Mar 20, 2026Camera traps are vital for large-scale biodiversity monitoring, yet accurate automated analysis remains challenging due to diverse deployment environments. While the computer vision community has mostly framed this challenge as cross-domain generalization, this perspective overlooks a primary challenge faced by ecological practitioners: maintaining reliable recognition at the fixed site over time, where the dynamic nature of ecosystems introduces profound temporal shifts in both background and animal distributions. To bridge this gap, we present the first unified study of camera-trap species recognition over time. We introduce a realistic benchmark comprising 546 camera traps with a streaming protocol that evaluates models over chronologically ordered intervals. Our end-user-centric study yields four key findings. (1) Biological foundation models (e.g., BioCLIP 2) underperform at numerous sites even in initial intervals, underscoring the necessity of site-specific adaptation. (2) Adaptation is challenging under realistic evaluation: when models are updated using past data and evaluated on future intervals (mirrors real deployment lifecycles), naive adaptation can even degrade below zero-shot performance. (3) We identify two drivers of this difficulty: severe class imbalance and pronounced temporal shift in both species distribution and backgrounds between consecutive intervals. (4) We find that effective integration of model-update and post-processing techniques can largely improve accuracy, though a gap from the upper bounds remains. Finally, we highlight critical open questions, such as predicting when zero-shot models will succeed at a new site and determining whether/when model updates are necessary. Our benchmark and analysis provide actionable deployment guidelines for ecological practitioners while establishing new directions for future research in vision and machine learning.
Revisiting Model Stitching In the Foundation Model Era
Mar 16, 2026Model stitching, connecting early layers of one model (source) to later layers of another (target) via a light stitch layer, has served as a probe of representational compatibility. Prior work finds that models trained on the same dataset remain stitchable (negligible accuracy drop) despite different initializations or objectives. We revisit stitching for Vision Foundation Models (VFMs) that vary in objectives, data, and modality mix (e.g., CLIP, DINOv2, SigLIP 2) and ask: Are heterogeneous VFMs stitchable? We introduce a systematic protocol spanning the stitch points, stitch layer families, training losses, and downstream tasks. Three findings emerge. (1) Stitch layer training matters: conventional approaches that match the intermediate features at the stitch point or optimize the task loss end-to-end struggle to retain accuracy, especially at shallow stitch points. (2) With a simple feature-matching loss at the target model's penultimate layer, heterogeneous VFMs become reliably stitchable across vision tasks. (3) For deep stitch points, the stitched model can surpass either constituent model at only a small inference overhead (for the stitch layer). Building on these findings, we further propose the VFM Stitch Tree (VST), which shares early layers across VFMs while retaining their later layers, yielding a controllable accuracy-latency trade-off for multimodal LLMs that often leverage multiple VFMs. Taken together, our study elevates stitching from a diagnostic probe to a practical recipe for integrating complementary VFM strengths and pinpointing where their representations align or diverge.
Continual Unlearning for Text-to-Image Diffusion Models: A Regularization Perspective
Nov 11, 2025Machine unlearning--the ability to remove designated concepts from a pre-trained model--has advanced rapidly, particularly for text-to-image diffusion models. However, existing methods typically assume that unlearning requests arrive all at once, whereas in practice they often arrive sequentially. We present the first systematic study of continual unlearning in text-to-image diffusion models and show that popular unlearning methods suffer from rapid utility collapse: after only a few requests, models forget retained knowledge and generate degraded images. We trace this failure to cumulative parameter drift from the pre-training weights and argue that regularization is crucial to addressing it. To this end, we study a suite of add-on regularizers that (1) mitigate drift and (2) remain compatible with existing unlearning methods. Beyond generic regularizers, we show that semantic awareness is essential for preserving concepts close to the unlearning target, and propose a gradient-projection method that constrains parameter drift orthogonal to their subspace. This substantially improves continual unlearning performance and is complementary to other regularizers for further gains. Taken together, our study establishes continual unlearning as a fundamental challenge in text-to-image generation and provides insights, baselines, and open directions for advancing safe and accountable generative AI.
AVA-Bench: Atomic Visual Ability Benchmark for Vision Foundation Models
Jun 10, 2025



The rise of vision foundation models (VFMs) calls for systematic evaluation. A common approach pairs VFMs with large language models (LLMs) as general-purpose heads, followed by evaluation on broad Visual Question Answering (VQA) benchmarks. However, this protocol has two key blind spots: (i) the instruction tuning data may not align with VQA test distributions, meaning a wrong prediction can stem from such data mismatch rather than a VFM' visual shortcomings; (ii) VQA benchmarks often require multiple visual abilities, making it hard to tell whether errors stem from lacking all required abilities or just a single critical one. To address these gaps, we introduce AVA-Bench, the first benchmark that explicitly disentangles 14 Atomic Visual Abilities (AVAs) -- foundational skills like localization, depth estimation, and spatial understanding that collectively support complex visual reasoning tasks. By decoupling AVAs and matching training and test distributions within each, AVA-Bench pinpoints exactly where a VFM excels or falters. Applying AVA-Bench to leading VFMs thus reveals distinctive "ability fingerprints," turning VFM selection from educated guesswork into principled engineering. Notably, we find that a 0.5B LLM yields similar VFM rankings as a 7B LLM while cutting GPU hours by 8x, enabling more efficient evaluation. By offering a comprehensive and transparent benchmark, we hope AVA-Bench lays the foundation for the next generation of VFMs.
BioCLIP 2: Emergent Properties from Scaling Hierarchical Contrastive Learning
May 29, 2025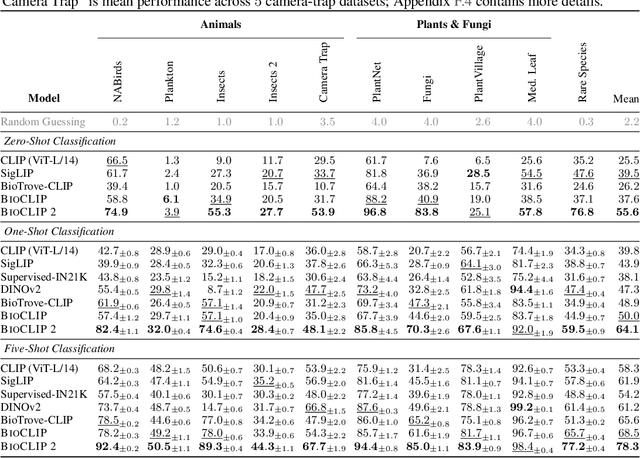
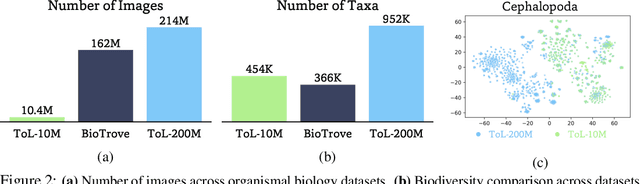
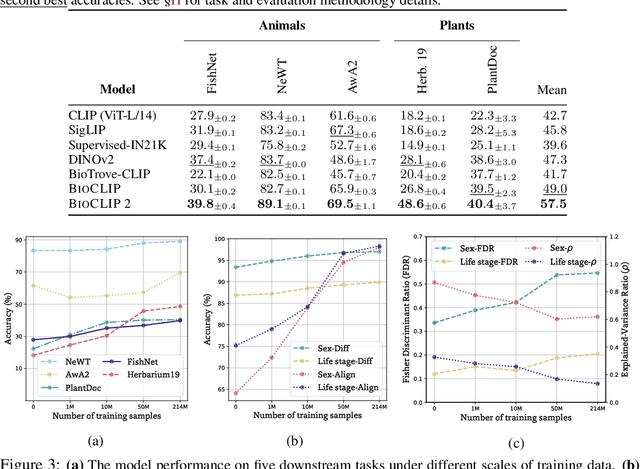
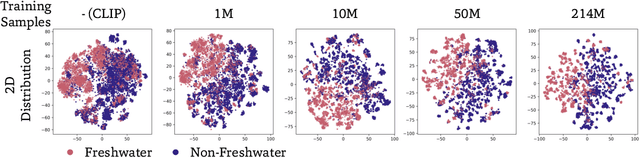
Foundation models trained at scale exhibit remarkable emergent behaviors, learning new capabilities beyond their initial training objectives. We find such emergent behaviors in biological vision models via large-scale contrastive vision-language training. To achieve this, we first curate TreeOfLife-200M, comprising 214 million images of living organisms, the largest and most diverse biological organism image dataset to date. We then train BioCLIP 2 on TreeOfLife-200M to distinguish different species. Despite the narrow training objective, BioCLIP 2 yields extraordinary accuracy when applied to various biological visual tasks such as habitat classification and trait prediction. We identify emergent properties in the learned embedding space of BioCLIP 2. At the inter-species level, the embedding distribution of different species aligns closely with functional and ecological meanings (e.g., beak sizes and habitats). At the intra-species level, instead of being diminished, the intra-species variations (e.g., life stages and sexes) are preserved and better separated in subspaces orthogonal to inter-species distinctions. We provide formal proof and analyses to explain why hierarchical supervision and contrastive objectives encourage these emergent properties. Crucially, our results reveal that these properties become increasingly significant with larger-scale training data, leading to a biologically meaningful embedding space.
Revisiting semi-supervised learning in the era of foundation models
Mar 12, 2025

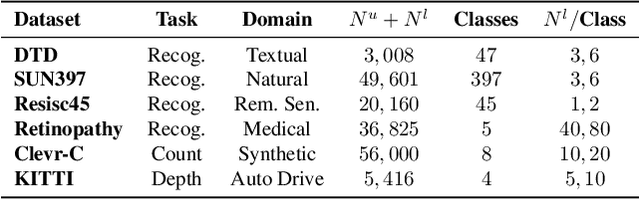
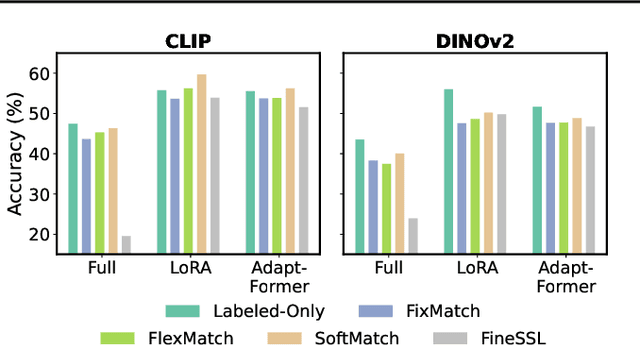
Semi-supervised learning (SSL) leverages abundant unlabeled data alongside limited labeled data to enhance learning. As vision foundation models (VFMs) increasingly serve as the backbone of vision applications, it remains unclear how SSL interacts with these pre-trained models. To address this gap, we develop new SSL benchmark datasets where frozen VFMs underperform and systematically evaluate representative SSL methods. We make a surprising observation: parameter-efficient fine-tuning (PEFT) using only labeled data often matches SSL performance, even without leveraging unlabeled data. This motivates us to revisit self-training, a conceptually simple SSL baseline, where we use the supervised PEFT model to pseudo-label unlabeled data for further training. To overcome the notorious issue of noisy pseudo-labels, we propose ensembling multiple PEFT approaches and VFM backbones to produce more robust pseudo-labels. Empirical results validate the effectiveness of this simple yet powerful approach, providing actionable insights into SSL with VFMs and paving the way for more scalable and practical semi-supervised learning in the era of foundation models.
MEDA: Dynamic KV Cache Allocation for Efficient Multimodal Long-Context Inference
Feb 24, 2025



Long-context Multimodal Large Language Models (MLLMs) that incorporate long text-image and text-video modalities, demand substantial resources as their multimodal Key-Value (KV) caches grow with increasing input lengths, challenging inference efficiency. Existing methods for KV cache compression, in both text-only and multimodal LLMs, have neglected attention density variations across layers, thus often adopting uniform or progressive reduction strategies for layer-wise cache allocation. In this work, we propose MEDA, a dynamic layer-wise KV cache allocation method for efficient multimodal long-context inference. As its core, MEDA utilizes cross-modal attention entropy to determine the KV cache size at each MLLMs layer. Given the dynamically allocated KV cache size at each layer, MEDA also employs a KV pair selection scheme to identify which KV pairs to select and a KV pair merging strategy that merges the selected and non-selected ones to preserve information from the entire context. MEDA achieves up to 72% KV cache memory reduction and 2.82 times faster decoding speed, while maintaining or enhancing performance on various multimodal tasks in long-context settings, including multi-images and long-video scenarios. Our code is released at https://github.com/AIoT-MLSys-Lab/MEDA.
Finer-CAM: Spotting the Difference Reveals Finer Details for Visual Explanation
Jan 20, 2025



Class activation map (CAM) has been widely used to highlight image regions that contribute to class predictions. Despite its simplicity and computational efficiency, CAM often struggles to identify discriminative regions that distinguish visually similar fine-grained classes. Prior efforts address this limitation by introducing more sophisticated explanation processes, but at the cost of extra complexity. In this paper, we propose Finer-CAM, a method that retains CAM's efficiency while achieving precise localization of discriminative regions. Our key insight is that the deficiency of CAM lies not in "how" it explains, but in "what" it explains}. Specifically, previous methods attempt to identify all cues contributing to the target class's logit value, which inadvertently also activates regions predictive of visually similar classes. By explicitly comparing the target class with similar classes and spotting their differences, Finer-CAM suppresses features shared with other classes and emphasizes the unique, discriminative details of the target class. Finer-CAM is easy to implement, compatible with various CAM methods, and can be extended to multi-modal models for accurate localization of specific concepts. Additionally, Finer-CAM allows adjustable comparison strength, enabling users to selectively highlight coarse object contours or fine discriminative details. Quantitatively, we show that masking out the top 5% of activated pixels by Finer-CAM results in a larger relative confidence drop compared to baselines. The source code and demo are available at https://github.com/Imageomics/Finer-CAM.
Prompt-CAM: A Simpler Interpretable Transformer for Fine-Grained Analysis
Jan 16, 2025



We present a simple usage of pre-trained Vision Transformers (ViTs) for fine-grained analysis, aiming to identify and localize the traits that distinguish visually similar categories, such as different bird species or dog breeds. Pre-trained ViTs such as DINO have shown remarkable capabilities to extract localized, informative features. However, using saliency maps like Grad-CAM can hardly point out the traits: they often locate the whole object by a blurred, coarse heatmap, not traits. We propose a novel approach Prompt Class Attention Map (Prompt-CAM) to the rescue. Prompt-CAM learns class-specific prompts to a pre-trained ViT and uses the corresponding outputs for classification. To classify an image correctly, the true-class prompt must attend to the unique image patches not seen in other classes' images, i.e., traits. As such, the true class's multi-head attention maps reveal traits and their locations. Implementation-wise, Prompt-CAM is almost a free lunch by simply modifying the prediction head of Visual Prompt Tuning (VPT). This makes Prompt-CAM fairly easy to train and apply, sharply contrasting other interpretable methods that design specific models and training processes. It is even simpler than the recently published INterpretable TRansformer (INTR), whose encoder-decoder architecture prevents it from leveraging pre-trained ViTs. Extensive empirical studies on a dozen datasets from various domains (e.g., birds, fishes, insects, fungi, flowers, food, and cars) validate Prompt-CAM superior interpretation capability.