 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-CAM: A Simpler Interpretable Transformer for Fine-Grained Analysis
Jan 16, 2025



We present a simple usage of pre-trained Vision Transformers (ViTs) for fine-grained analysis, aiming to identify and localize the traits that distinguish visually similar categories, such as different bird species or dog breeds. Pre-trained ViTs such as DINO have shown remarkable capabilities to extract localized, informative features. However, using saliency maps like Grad-CAM can hardly point out the traits: they often locate the whole object by a blurred, coarse heatmap, not traits. We propose a novel approach Prompt Class Attention Map (Prompt-CAM) to the rescue. Prompt-CAM learns class-specific prompts to a pre-trained ViT and uses the corresponding outputs for classification. To classify an image correctly, the true-class prompt must attend to the unique image patches not seen in other classes' images, i.e., traits. As such, the true class's multi-head attention maps reveal traits and their locations. Implementation-wise, Prompt-CAM is almost a free lunch by simply modifying the prediction head of Visual Prompt Tuning (VPT). This makes Prompt-CAM fairly easy to train and apply, sharply contrasting other interpretable methods that design specific models and training processes. It is even simpler than the recently published INterpretable TRansformer (INTR), whose encoder-decoder architecture prevents it from leveraging pre-trained ViTs. Extensive empirical studies on a dozen datasets from various domains (e.g., birds, fishes, insects, fungi, flowers, food, and cars) validate Prompt-CAM superior interpretation capability.
A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis
Nov 07, 2023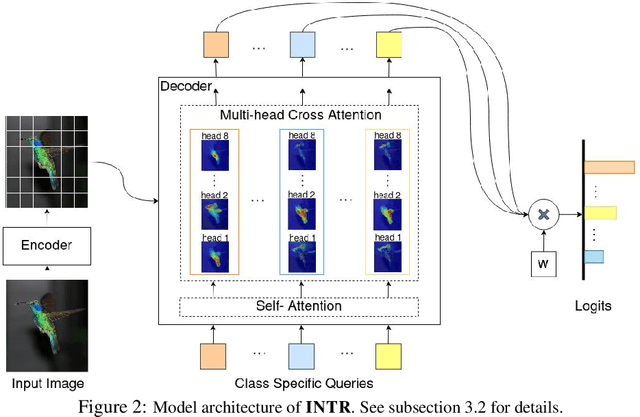

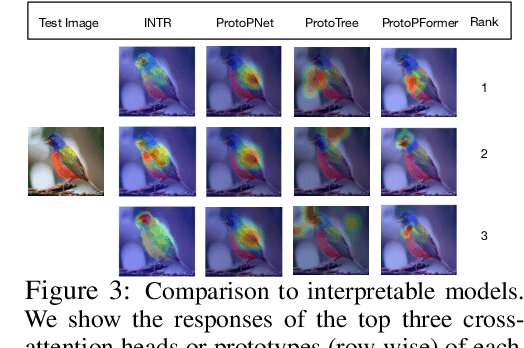

We present a novel usage of Transformers to make image classification interpretable. Unlike mainstream classifiers that wait until the last fully-connected layer to incorporate class information to make predictions, we investigate a proactive approach, asking each class to search for itself in an image. We realize this idea via a Transformer encoder-decoder inspired by DEtection TRansformer (DETR). We learn ``class-specific'' queries (one for each class) as input to the decoder, enabling each class to localize its patterns in an image via cross-attention. We name our approach INterpretable TRansformer (INTR), which is fairly easy to implement and exhibits several compelling properties. We show that INTR intrinsically encourages each class to attend distinctively; the cross-attention weights thus provide a faithful interpretation of the prediction. Interestingly, via ``multi-head'' cross-attention, INTR could identify different ``attributes'' of a class, making it particularly suitable for fine-grained classification and analysis, which we demonstrate on eight datasets. Our code and pre-trained model are publicly accessible at https://github.com/Imageomics/INTR.