 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxaAdapter: Vision Taxonomy Models are Key to Fine-grained Image Generation over the Tree of Life
Mar 27, 2026Accurately generating images across the Tree of Life is difficult: there are over 10M distinct species on Earth, many of which differ only by subtle visual traits. Despite the remarkable progress in text-to-image synthesis, existing models often fail to capture the fine-grained visual cues that define species identity, even when their outputs appear photo-realistic. To this end, we propose TaxaAdapter, a simple and lightweight approach that incorporates Vision Taxonomy Models (VTMs) such as BioCLIP to guide fine-grained species generation. Our method injects VTM embeddings into a frozen text-to-image diffusion model, improving species-level fidelity while preserving flexible text control over attributes such as pose, style, and background. Extensive experiments demonstrate that TaxaAdapter consistently improves morphology fidelity and species-identity accuracy over strong baselines, with a cleaner architecture and training recipe. To better evaluate these improvements, we also introduce a multimodal Large Language Model-based metric that summarizes trait-level descriptions from generated and real images, providing a more interpretable measure of morphological consistency. Beyond this, we observe that TaxaAdapter exhibits strong generalization capabilities, enabling species synthesis in challenging regimes such as few-shot species with only a handful of training images and even species unseen during training. Overall, our results highlight that VTMs are a key ingredient for scalable, fine-grained species generation.
Finer-Personalization Rank: Fine-Grained Retrieval Examines Identity Preservation for Personalized Generation
Dec 22, 2025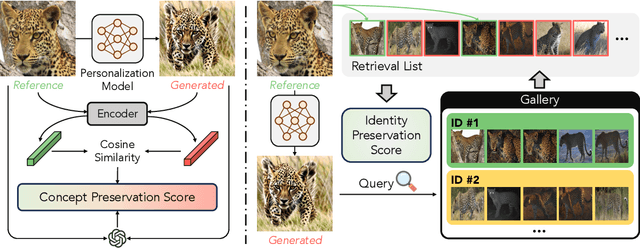
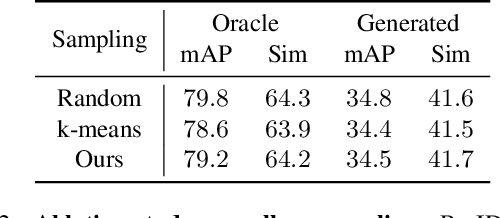
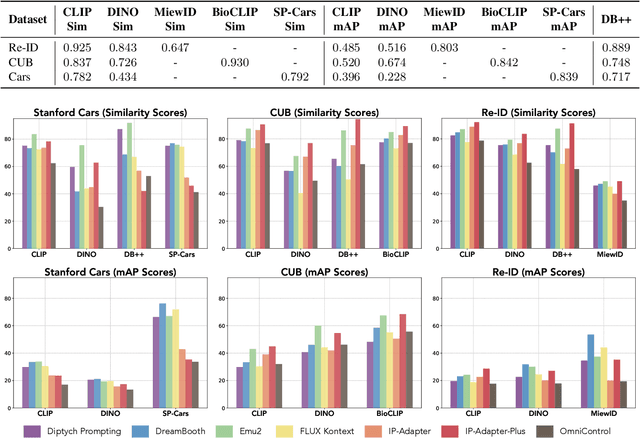

The rise of personalized generative models raises a central question: how should we evaluate identity preservation? Given a reference image (e.g., one's pet), we expect the generated image to retain precise details attached to the subject's identity. However, current generative evaluation metrics emphasize the overall semantic similarity between the reference and the output, and overlook these fine-grained discriminative details. We introduce Finer-Personalization Rank, an evaluation protocol tailored to identity preservation. Instead of pairwise similarity, Finer-Personalization Rank adopts a ranking view: it treats each generated image as a query against an identity-labeled gallery consisting of visually similar real images. Retrieval metrics (e.g., mean average precision) measure performance, where higher scores indicate that identity-specific details (e.g., a distinctive head spot) are preserved. We assess identity at multiple granularities -- from fine-grained categories (e.g., bird species, car models) to individual instances (e.g., re-identification). Across CUB, Stanford Cars, and animal Re-ID benchmarks, Finer-Personalization Rank more faithfully reflects identity retention than semantic-only metrics and reveals substantial identity drift in several popular personalization methods. These results position the gallery-based protocol as a principled and practical evaluation for personalized generation.
Finer-CAM: Spotting the Difference Reveals Finer Details for Visual Explanation
Jan 20, 2025



Class activation map (CAM) has been widely used to highlight image regions that contribute to class predictions. Despite its simplicity and computational efficiency, CAM often struggles to identify discriminative regions that distinguish visually similar fine-grained classes. Prior efforts address this limitation by introducing more sophisticated explanation processes, but at the cost of extra complexity. In this paper, we propose Finer-CAM, a method that retains CAM's efficiency while achieving precise localization of discriminative regions. Our key insight is that the deficiency of CAM lies not in "how" it explains, but in "what" it explains}. Specifically, previous methods attempt to identify all cues contributing to the target class's logit value, which inadvertently also activates regions predictive of visually similar classes. By explicitly comparing the target class with similar classes and spotting their differences, Finer-CAM suppresses features shared with other classes and emphasizes the unique, discriminative details of the target class. Finer-CAM is easy to implement, compatible with various CAM methods, and can be extended to multi-modal models for accurate localization of specific concepts. Additionally, Finer-CAM allows adjustable comparison strength, enabling users to selectively highlight coarse object contours or fine discriminative details. Quantitatively, we show that masking out the top 5% of activated pixels by Finer-CAM results in a larger relative confidence drop compared to baselines. The source code and demo are available at https://github.com/Imageomics/Finer-CAM.
A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis
Nov 07, 2023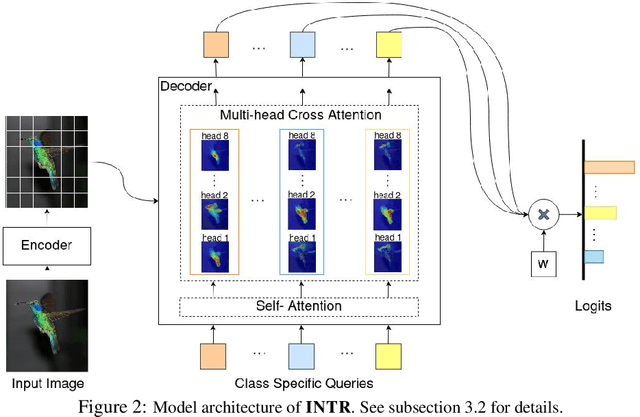

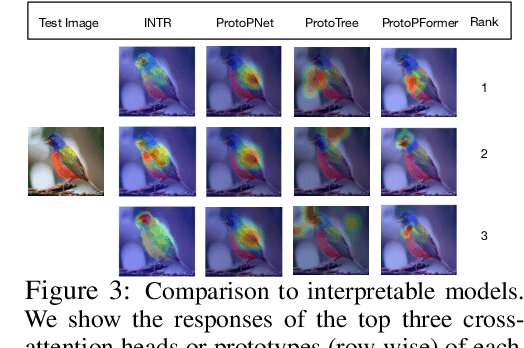

We present a novel usage of Transformers to make image classification interpretable. Unlike mainstream classifiers that wait until the last fully-connected layer to incorporate class information to make predictions, we investigate a proactive approach, asking each class to search for itself in an image. We realize this idea via a Transformer encoder-decoder inspired by DEtection TRansformer (DETR). We learn ``class-specific'' queries (one for each class) as input to the decoder, enabling each class to localize its patterns in an image via cross-attention. We name our approach INterpretable TRansformer (INTR), which is fairly easy to implement and exhibits several compelling properties. We show that INTR intrinsically encourages each class to attend distinctively; the cross-attention weights thus provide a faithful interpretation of the prediction. Interestingly, via ``multi-head'' cross-attention, INTR could identify different ``attributes'' of a class, making it particularly suitable for fine-grained classification and analysis, which we demonstrate on eight datasets. Our code and pre-trained model are publicly accessible at https://github.com/Imageomics/INTR.
Discovering Novel Biological Traits From Images Using Phylogeny-Guided Neural Networks
Jun 05, 2023



Discovering evolutionary traits that are heritable across species on the tree of life (also referred to as a phylogenetic tree) is of great interest to biologists to understand how organisms diversify and evolve. However, the measurement of traits is often a subjective and labor-intensive process, making trait discovery a highly label-scarce problem. We present a novel approach for discovering evolutionary traits directly from images without relying on trait labels. Our proposed approach, Phylo-NN, encodes the image of an organism into a sequence of quantized feature vectors -- or codes -- where different segments of the sequence capture evolutionary signals at varying ancestry levels in the phylogeny. We demonstrate the effectiveness of our approach in producing biologically meaningful results in a number of downstream tasks including species image generation and species-to-species image translation, using fish species as a target example.
Learning Fractals by Gradient Descent
Mar 14, 2023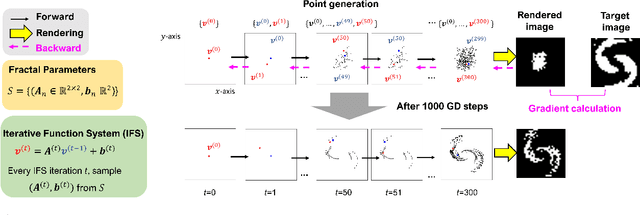
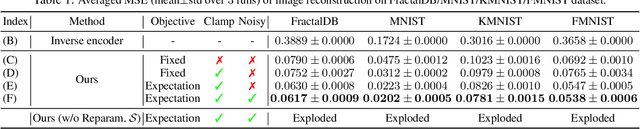
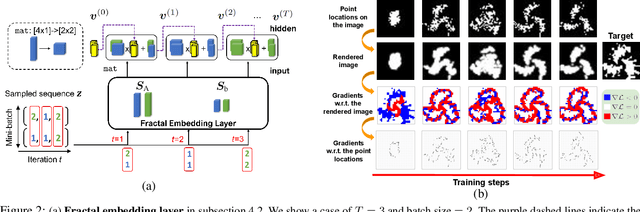

Fractals are geometric shapes that can display complex and self-similar patterns found in nature (e.g., clouds and plants). Recent works in visual recognition have leveraged this property to create random fractal images for model pre-training. In this paper, we study the inverse problem -- given a target image (not necessarily a fractal), we aim to generate a fractal image that looks like it. We propose a novel approach that learns the parameters underlying a fractal image via gradient descent. We show that our approach can find fractal parameters of high visual quality and be compatible with different loss functions, opening up several potentials, e.g., learning fractals for downstream tasks, scientific understanding, etc.