 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Image-Level Morphological Trait Annotation for Organismal Images
Apr 02, 2026Morphological traits are physical characteristics of biological organisms that provide vital clues on how organisms interact with their environment. Yet extracting these traits remains a slow, expert-driven process, limiting their use in large-scale ecological studies. A major bottleneck is the absence of high-quality datasets linking biological images to trait-level annotations. In this work, we demonstrate that sparse autoencoders trained on foundation-model features yield monosemantic, spatially grounded neurons that consistently activate on meaningful morphological parts. Leveraging this property, we introduce a trait annotation pipeline that localizes salient regions and uses vision-language prompting to generate interpretable trait descriptions. Using this approach, we construct Bioscan-Traits, a dataset of 80K trait annotations spanning 19K insect images from BIOSCAN-5M. Human evaluation confirms the biological plausibility of the generated morphological descriptions. We assess design sensitivity through a comprehensive ablation study, systematically varying key design choices and measuring their impact on the quality of the resulting trait descriptions. By annotating traits with a modular pipeline rather than prohibitively expensive manual efforts, we offer a scalable way to inject biologically meaningful supervision into foundation models, enable large-scale morphological analyses, and bridge the gap between ecological relevance and machine-learning practicality.
* ICLR 2026
A continental-scale dataset of ground beetles with high-resolution images and validated morphological trait measurements
Jan 14, 2026Despite the ecological significance of invertebrates, global trait databases remain heavily biased toward vertebrates and plants, limiting comprehensive ecological analyses of high-diversity groups like ground beetles. Ground beetles (Coleoptera: Carabidae) serve as critical bioindicators of ecosystem health, providing valuable insights into biodiversity shifts driven by environmental changes. While the National Ecological Observatory Network (NEON) maintains an extensive collection of carabid specimens from across the United States, these primarily exist as physical collections, restricting widespread research access and large-scale analysis. To address these gaps, we present a multimodal dataset digitizing over 13,200 NEON carabids from 30 sites spanning the continental US and Hawaii through high-resolution imaging, enabling broader access and computational analysis. The dataset includes digitally measured elytra length and width of each specimen, establishing a foundation for automated trait extraction using AI. Validated against manual measurements, our digital trait extraction achieves sub-millimeter precision, ensuring reliability for ecological and computational studies. By addressing invertebrate under-representation in trait databases, this work supports AI-driven tools for automated species identification and trait-based research, fostering advancements in biodiversity monitoring and conservation.
kabr-tools: Automated Framework for Multi-Species Behavioral Monitoring
Oct 02, 2025A comprehensive understanding of animal behavior ecology depends on scalable approaches to quantify and interpret complex, multidimensional behavioral patterns. Traditional field observations are often limited in scope, time-consuming, and labor-intensive, hindering the assessment of behavioral responses across landscapes. To address this, we present kabr-tools (Kenyan Animal Behavior Recognition Tools), an open-source package for automated multi-species behavioral monitoring. This framework integrates drone-based video with machine learning systems to extract behavioral, social, and spatial metrics from wildlife footage. Our pipeline leverages object detection, tracking, and behavioral classification systems to generate key metrics, including time budgets, behavioral transitions, social interactions, habitat associations, and group composition dynamics. Compared to ground-based methods, drone-based observations significantly improved behavioral granularity, reducing visibility loss by 15% and capturing more transitions with higher accuracy and continuity. We validate kabr-tools through three case studies, analyzing 969 behavioral sequences, surpassing the capacity of traditional methods for data capture and annotation. We found that, like Plains zebras, vigilance in Grevy's zebras decreases with herd size, but, unlike Plains zebras, habitat has a negligible impact. Plains and Grevy's zebras exhibit strong behavioral inertia, with rare transitions to alert behaviors and observed spatial segregation between Grevy's zebras, Plains zebras, and giraffes in mixed-species herds. By enabling automated behavioral monitoring at scale, kabr-tools offers a powerful tool for ecosystem-wide studies, advancing conservation, biodiversity research, and ecological monitoring.
BioCLIP 2: Emergent Properties from Scaling Hierarchical Contrastive Learning
May 29, 2025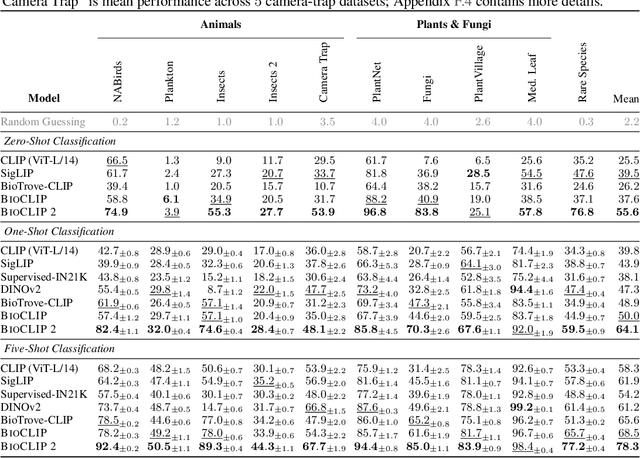
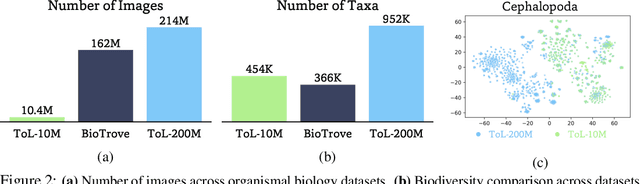
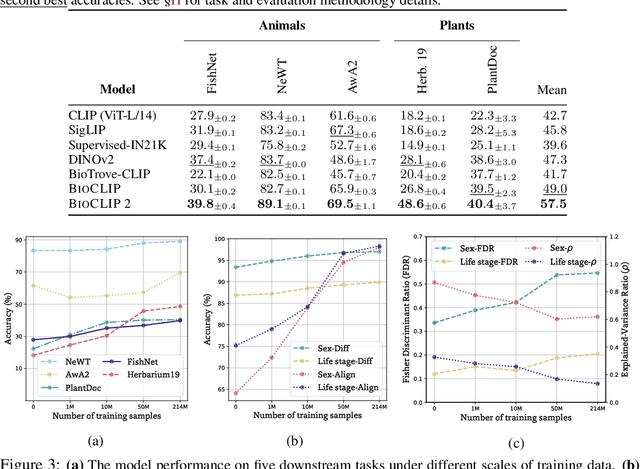
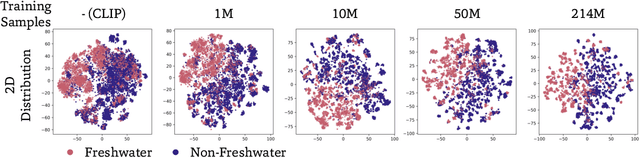
Foundation models trained at scale exhibit remarkable emergent behaviors, learning new capabilities beyond their initial training objectives. We find such emergent behaviors in biological vision models via large-scale contrastive vision-language training. To achieve this, we first curate TreeOfLife-200M, comprising 214 million images of living organisms, the largest and most diverse biological organism image dataset to date. We then train BioCLIP 2 on TreeOfLife-200M to distinguish different species. Despite the narrow training objective, BioCLIP 2 yields extraordinary accuracy when applied to various biological visual tasks such as habitat classification and trait prediction. We identify emergent properties in the learned embedding space of BioCLIP 2. At the inter-species level, the embedding distribution of different species aligns closely with functional and ecological meanings (e.g., beak sizes and habitats). At the intra-species level, instead of being diminished, the intra-species variations (e.g., life stages and sexes) are preserved and better separated in subspaces orthogonal to inter-species distinctions. We provide formal proof and analyses to explain why hierarchical supervision and contrastive objectives encourage these emergent properties. Crucially, our results reveal that these properties become increasingly significant with larger-scale training data, leading to a biologically meaningful embedding space.
Optimizing Image Capture for Computer Vision-Powered Taxonomic Identification and Trait Recognition of Biodiversity Specimens
May 22, 2025Biological collections house millions of specimens documenting Earth's biodiversity, with digital images increasingly available through open-access platforms. Most imaging protocols were developed for human visual interpretation without considering computational analysis requirements. This paper aims to bridge the gap between current imaging practices and the potential for automated analysis by presenting key considerations for creating biological specimen images optimized for computer vision applications. We provide conceptual computer vision topics for context, addressing fundamental concerns including model generalization, data leakage, and comprehensive metadata documentation, and outline practical guidance on specimen imagine, and data storage. These recommendations were synthesized through interdisciplinary collaboration between taxonomists, collection managers, ecologists, and computer scientists. Through this synthesis, we have identified ten interconnected considerations that form a framework for successfully integrating biological specimen images into computer vision pipelines. The key elements include: (1) comprehensive metadata documentation, (2) standardized specimen positioning, (3) consistent size and color calibration, (4) protocols for handling multiple specimens in one image, (5) uniform background selection, (6) controlled lighting, (7) appropriate resolution and magnification, (8) optimal file formats, (9) robust data archiving strategies, and (10) accessible data sharing practices. By implementing these recommendations, collection managers, taxonomists, and biodiversity informaticians can generate images that support automated trait extraction, species identification, and novel ecological and evolutionary analyses at unprecedented scales. Successful implementation lies in thorough documentation of methodological choices.
BeetleVerse: A study on taxonomic classification of ground beetles
Apr 18, 2025
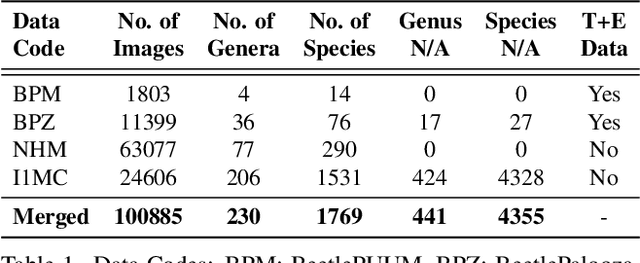
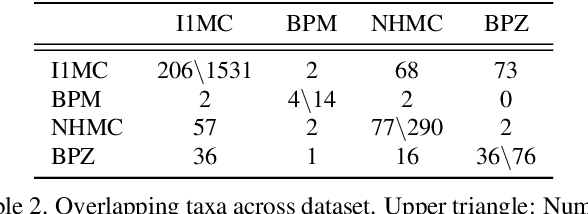
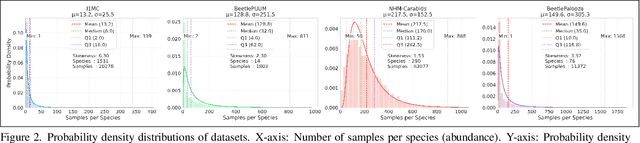
Ground beetles are a highly sensitive and speciose biological indicator, making them vital for monitoring biodiversity. However, they are currently an underutilized resource due to the manual effort required by taxonomic experts to perform challenging species differentiations based on subtle morphological differences, precluding widespread applications. In this paper, we evaluate 12 vision models on taxonomic classification across four diverse, long-tailed datasets spanning over 230 genera and 1769 species, with images ranging from controlled laboratory settings to challenging field-collected (in-situ) photographs. We further explore taxonomic classification in two important real-world contexts: sample efficiency and domain adaptation. Our results show that the Vision and Language Transformer combined with an MLP head is the best performing model, with 97\% accuracy at genus and 94\% at species level. Sample efficiency analysis shows that we can reduce train data requirements by up to 50\% with minimal compromise in performance. The domain adaptation experiments reveal significant challenges when transferring models from lab to in-situ images, highlighting a critical domain gap. Overall, our study lays a foundation for large-scale automated taxonomic classification of beetles, and beyond that, advances sample-efficient learning and cross-domain adaptation for diverse long-tailed ecological datasets.
MMLA: Multi-Environment, Multi-Species, Low-Altitude Aerial Footage Dataset
Apr 10, 2025Real-time wildlife detection in drone imagery is critical for numerous applications, including animal ecology, conservation, and biodiversity monitoring. Low-altitude drone missions are effective for collecting fine-grained animal movement and behavior data, particularly if missions are automated for increased speed and consistency. However, little work exists on evaluating computer vision models on low-altitude aerial imagery and generalizability across different species and settings. To fill this gap, we present a novel multi-environment, multi-species, low-altitude aerial footage (MMLA) dataset. MMLA consists of drone footage collected across three diverse environments: Ol Pejeta Conservancy and Mpala Research Centre in Kenya, and The Wilds Conservation Center in Ohio, which includes five species: Plains zebras, Grevy's zebras, giraffes, onagers, and African Painted Dogs. We comprehensively evaluate three YOLO models (YOLOv5m, YOLOv8m, and YOLOv11m) for detecting animals. Results demonstrate significant performance disparities across locations and species-specific detection variations. Our work highlights the importance of evaluating detection algorithms across different environments for robust wildlife monitoring applications using drones.
Mind the Gap: Evaluating Vision Systems in Small Data Applications
Apr 08, 2025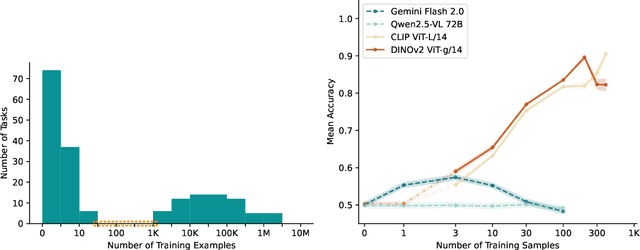
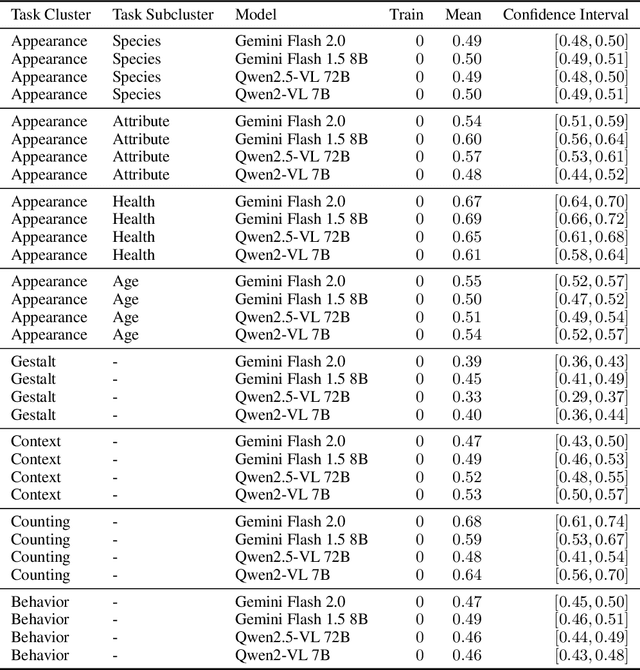
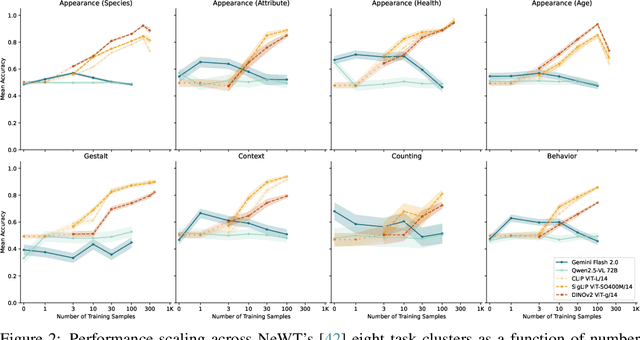
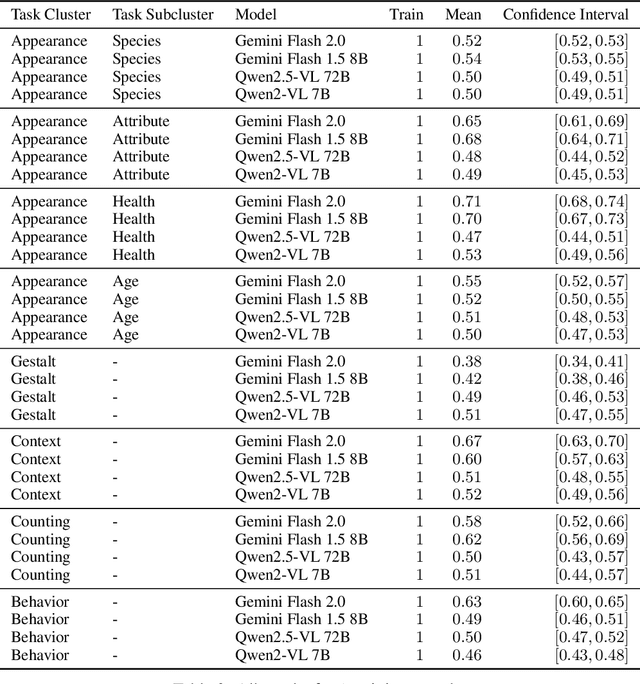
The practical application of AI tools for specific computer vision tasks relies on the "small-data regime" of hundreds to thousands of labeled samples. This small-data regime is vital for applications requiring expensive expert annotations, such as ecological monitoring, medical diagnostics or industrial quality control. We find, however, that computer vision research has ignored the small data regime as evaluations increasingly focus on zero- and few-shot learning. We use the Natural World Tasks (NeWT) benchmark to compare multi-modal large language models (MLLMs) and vision-only methods across varying training set sizes. MLLMs exhibit early performance plateaus, while vision-only methods improve throughout the small-data regime, with performance gaps widening beyond 10 training examples. We provide the first comprehensive comparison between these approaches in small-data contexts and advocate for explicit small-data evaluations in AI research to better bridge theoretical advances with practical deployments.
Sparse Autoencoders for Scientifically Rigorous Interpretation of Vision Models
Feb 10, 2025

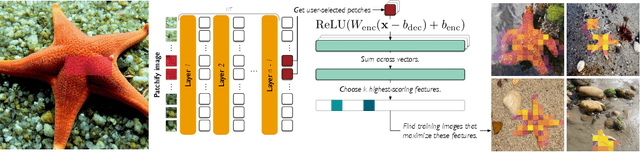

To truly understand vision models, we must not only interpret their learned features but also validate these interpretations through controlled experiments. Current approaches either provide interpretable features without the ability to test their causal influence, or enable model editing without interpretable controls. We present a unified framework using sparse autoencoders (SAEs) that bridges this gap, allowing us to discover human-interpretable visual features and precisely manipulate them to test hypotheses about model behavior. By applying our method to state-of-the-art vision models, we reveal key differences in the semantic abstractions learned by models with different pre-training objectives. We then demonstrate the practical usage of our framework through controlled interventions across multiple vision tasks. We show that SAEs can reliably identify and manipulate interpretable visual features without model re-training, providing a powerful tool for understanding and controlling vision model behavior. We provide code, demos and models on our project website: https://osu-nlp-group.github.io/SAE-V.
Salsa Fresca: Angular Embeddings and Pre-Training for ML Attacks on Learning With Errors
Feb 02, 2024



Learning with Errors (LWE) is a hard math problem underlying recently standardized post-quantum cryptography (PQC) systems for key exchange and digital signatures. Prior work proposed new machine learning (ML)-based attacks on LWE problems with small, sparse secrets, but these attacks require millions of LWE samples to train on and take days to recover secrets. We propose three key methods -- better preprocessing, angular embeddings and model pre-training -- to improve these attacks, speeding up preprocessing by $25\times$ and improving model sample efficiency by $10\times$. We demonstrate for the first time that pre-training improves and reduces the cost of ML attacks on LWE. Our architecture improvements enable scaling to larger-dimension LWE problems: this work is the first instance of ML attacks recovering sparse binary secrets in dimension $n=1024$, the smallest dimension used in practice for homomorphic encryption applications of LWE where sparse binary secrets are proposed.