 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Image Capture for Computer Vision-Powered Taxonomic Identification and Trait Recognition of Biodiversity Specimens
May 22, 2025Biological collections house millions of specimens documenting Earth's biodiversity, with digital images increasingly available through open-access platforms. Most imaging protocols were developed for human visual interpretation without considering computational analysis requirements. This paper aims to bridge the gap between current imaging practices and the potential for automated analysis by presenting key considerations for creating biological specimen images optimized for computer vision applications. We provide conceptual computer vision topics for context, addressing fundamental concerns including model generalization, data leakage, and comprehensive metadata documentation, and outline practical guidance on specimen imagine, and data storage. These recommendations were synthesized through interdisciplinary collaboration between taxonomists, collection managers, ecologists, and computer scientists. Through this synthesis, we have identified ten interconnected considerations that form a framework for successfully integrating biological specimen images into computer vision pipelines. The key elements include: (1) comprehensive metadata documentation, (2) standardized specimen positioning, (3) consistent size and color calibration, (4) protocols for handling multiple specimens in one image, (5) uniform background selection, (6) controlled lighting, (7) appropriate resolution and magnification, (8) optimal file formats, (9) robust data archiving strategies, and (10) accessible data sharing practices. By implementing these recommendations, collection managers, taxonomists, and biodiversity informaticians can generate images that support automated trait extraction, species identification, and novel ecological and evolutionary analyses at unprecedented scales. Successful implementation lies in thorough documentation of methodological choices.
Label-free Monitoring of Self-Supervised Learning Progress
Sep 10, 2024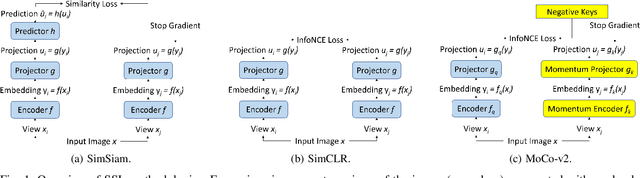
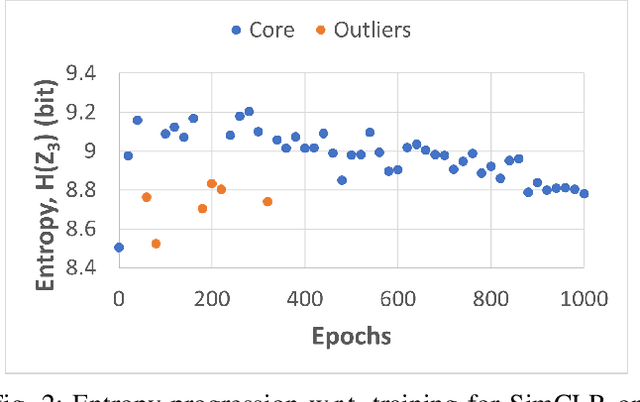
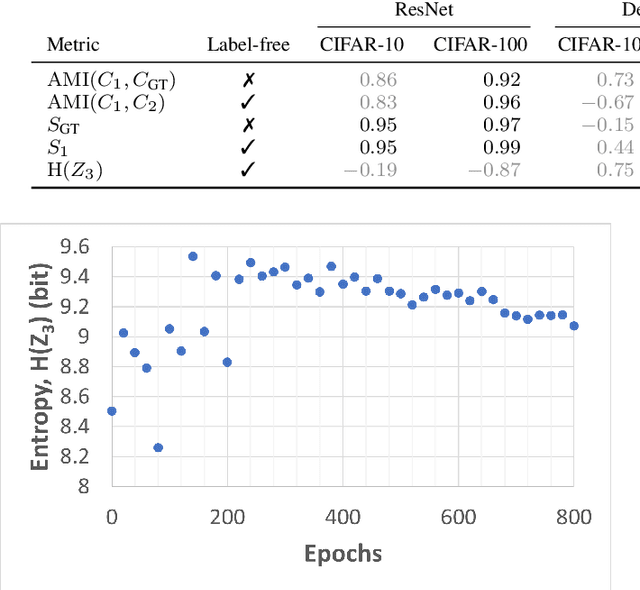
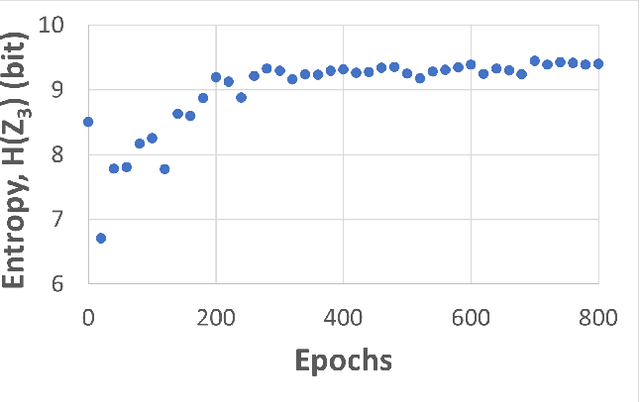
Self-supervised learning (SSL) is an effective method for exploiting unlabelled data to learn a high-level embedding space that can be used for various downstream tasks. However, existing methods to monitor the quality of the encoder -- either during training for one model or to compare several trained models -- still rely on access to annotated data. When SSL methodologies are applied to new data domains, a sufficiently large labelled dataset may not always be available. In this study, we propose several evaluation metrics which can be applied on the embeddings of unlabelled data and investigate their viability by comparing them to linear probe accuracy (a common metric which utilizes an annotated dataset). In particular, we apply $k$-means clustering and measure the clustering quality with the silhouette score and clustering agreement. We also measure the entropy of the embedding distribution. We find that while the clusters did correspond better to the ground truth annotations as training of the network progressed, label-free clustering metrics correlated with the linear probe accuracy only when training with SSL methods SimCLR and MoCo-v2, but not with SimSiam. Additionally, although entropy did not always have strong correlations with LP accuracy, this appears to be due to instability arising from early training, with the metric stabilizing and becoming more reliable at later stages of learning. Furthermore, while entropy generally decreases as learning progresses, this trend reverses for SimSiam. More research is required to establish the cause for this unexpected behaviour. Lastly, we find that while clustering based approaches are likely only viable for same-architecture comparisons, entropy may be architecture-independent.