 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA continental-scale dataset of ground beetles with high-resolution images and validated morphological trait measurements
Jan 14, 2026Despite the ecological significance of invertebrates, global trait databases remain heavily biased toward vertebrates and plants, limiting comprehensive ecological analyses of high-diversity groups like ground beetles. Ground beetles (Coleoptera: Carabidae) serve as critical bioindicators of ecosystem health, providing valuable insights into biodiversity shifts driven by environmental changes. While the National Ecological Observatory Network (NEON) maintains an extensive collection of carabid specimens from across the United States, these primarily exist as physical collections, restricting widespread research access and large-scale analysis. To address these gaps, we present a multimodal dataset digitizing over 13,200 NEON carabids from 30 sites spanning the continental US and Hawaii through high-resolution imaging, enabling broader access and computational analysis. The dataset includes digitally measured elytra length and width of each specimen, establishing a foundation for automated trait extraction using AI. Validated against manual measurements, our digital trait extraction achieves sub-millimeter precision, ensuring reliability for ecological and computational studies. By addressing invertebrate under-representation in trait databases, this work supports AI-driven tools for automated species identification and trait-based research, fostering advancements in biodiversity monitoring and conservation.
Optimizing Image Capture for Computer Vision-Powered Taxonomic Identification and Trait Recognition of Biodiversity Specimens
May 22, 2025Biological collections house millions of specimens documenting Earth's biodiversity, with digital images increasingly available through open-access platforms. Most imaging protocols were developed for human visual interpretation without considering computational analysis requirements. This paper aims to bridge the gap between current imaging practices and the potential for automated analysis by presenting key considerations for creating biological specimen images optimized for computer vision applications. We provide conceptual computer vision topics for context, addressing fundamental concerns including model generalization, data leakage, and comprehensive metadata documentation, and outline practical guidance on specimen imagine, and data storage. These recommendations were synthesized through interdisciplinary collaboration between taxonomists, collection managers, ecologists, and computer scientists. Through this synthesis, we have identified ten interconnected considerations that form a framework for successfully integrating biological specimen images into computer vision pipelines. The key elements include: (1) comprehensive metadata documentation, (2) standardized specimen positioning, (3) consistent size and color calibration, (4) protocols for handling multiple specimens in one image, (5) uniform background selection, (6) controlled lighting, (7) appropriate resolution and magnification, (8) optimal file formats, (9) robust data archiving strategies, and (10) accessible data sharing practices. By implementing these recommendations, collection managers, taxonomists, and biodiversity informaticians can generate images that support automated trait extraction, species identification, and novel ecological and evolutionary analyses at unprecedented scales. Successful implementation lies in thorough documentation of methodological choices.
BeetleVerse: A study on taxonomic classification of ground beetles
Apr 18, 2025
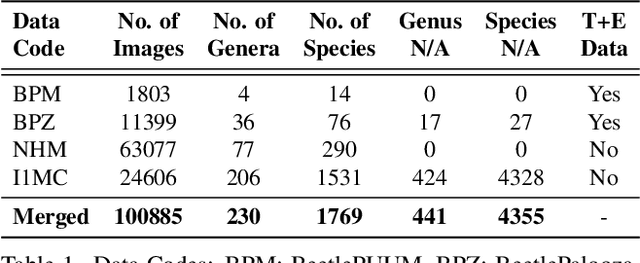
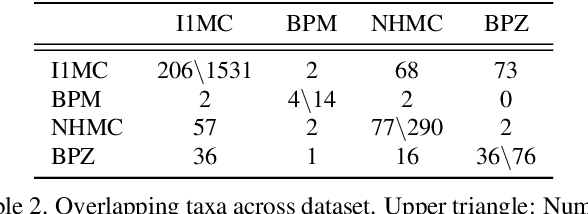
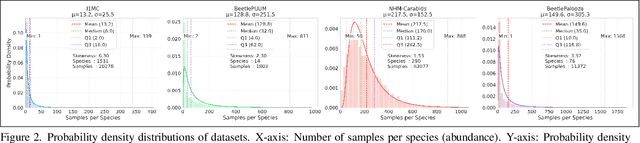
Ground beetles are a highly sensitive and speciose biological indicator, making them vital for monitoring biodiversity. However, they are currently an underutilized resource due to the manual effort required by taxonomic experts to perform challenging species differentiations based on subtle morphological differences, precluding widespread applications. In this paper, we evaluate 12 vision models on taxonomic classification across four diverse, long-tailed datasets spanning over 230 genera and 1769 species, with images ranging from controlled laboratory settings to challenging field-collected (in-situ) photographs. We further explore taxonomic classification in two important real-world contexts: sample efficiency and domain adaptation. Our results show that the Vision and Language Transformer combined with an MLP head is the best performing model, with 97\% accuracy at genus and 94\% at species level. Sample efficiency analysis shows that we can reduce train data requirements by up to 50\% with minimal compromise in performance. The domain adaptation experiments reveal significant challenges when transferring models from lab to in-situ images, highlighting a critical domain gap. Overall, our study lays a foundation for large-scale automated taxonomic classification of beetles, and beyond that, advances sample-efficient learning and cross-domain adaptation for diverse long-tailed ecological datasets.
Mind the Gap: Evaluating Vision Systems in Small Data Applications
Apr 08, 2025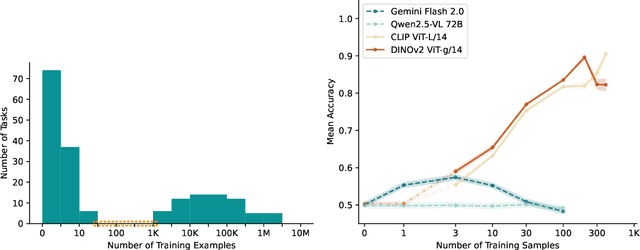
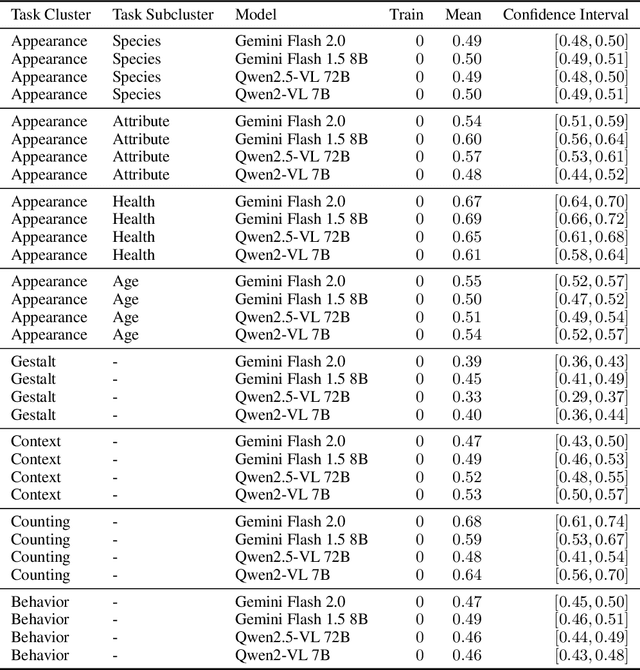
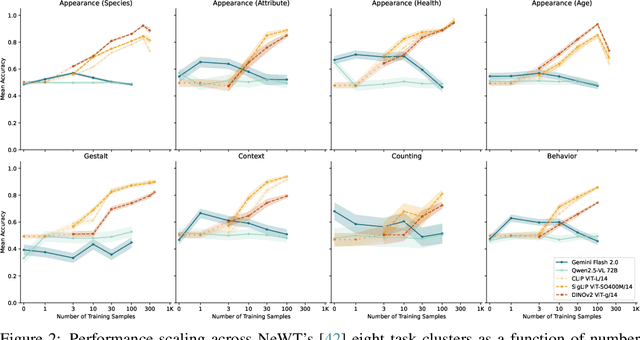
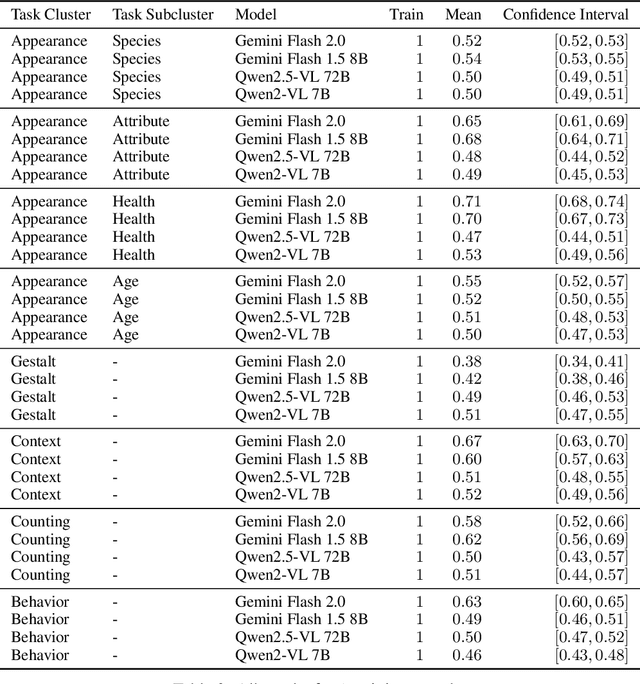
The practical application of AI tools for specific computer vision tasks relies on the "small-data regime" of hundreds to thousands of labeled samples. This small-data regime is vital for applications requiring expensive expert annotations, such as ecological monitoring, medical diagnostics or industrial quality control. We find, however, that computer vision research has ignored the small data regime as evaluations increasingly focus on zero- and few-shot learning. We use the Natural World Tasks (NeWT) benchmark to compare multi-modal large language models (MLLMs) and vision-only methods across varying training set sizes. MLLMs exhibit early performance plateaus, while vision-only methods improve throughout the small-data regime, with performance gaps widening beyond 10 training examples. We provide the first comprehensive comparison between these approaches in small-data contexts and advocate for explicit small-data evaluations in AI research to better bridge theoretical advances with practical deployments.