 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost at the End: Primacy Bias in Multimodal Retrieval-Augmented Question Answering
Jun 15, 2026Knowledge-based visual question answering (KB-VQA) lets vision-language systems answer questions that exceed their parametric knowledge by conditioning a reader on passages retrieved from a Wikipedia-scale knowledge base. In pure-text long-context LLMs, retrieved-context use follows the U-shaped "lost-in-the-middle" effect of Liu et al. (2024): information at the start and end of context is used, the middle is lost. Whether this transfers to deployed multimodal KB-VQA is open. To close this gap, we design the first controlled probe of reader-side position dependence in multimodal KB-VQA: a gold-position protocol in which only the gold passage's prompt slot varies within question. We run it on three open-source 7B/8B VLM readers and two KB-VQA benchmarks at k up to 20. The shape flips from U to primacy: gold-at-first beats gold-at-last by 16 to 26 points on every reader-by-benchmark cell, an effect we call "Lost at the End". Three targeted ablations narrow the cause: a text-only control shows the multimodal setting amplifies an already-present text-mode primacy 2.2 to 4.5 times, and image-position and distractor-shuffle ablations together pin the locus to prompt slot 0 of the instruction-tuned reader. On a frozen reader, three retrieval-side fixes (MMR, oracle reranking, rank-based reordering) all leave the gap intact (no separable improvement). Our findings indicate that recall@k is the wrong metric for deployed KB-VQA and that closing the gap requires reader-side intervention; we release our protocol as a controlled instrument for evaluating such interventions.
Better with Experience: Self-Evolving LLM Agents for Evidence-Grounded Health Community Notes
Jun 01, 2026Large Language Model (LLM)-augmented Community Notes offer a scalable path for timely, evidence-grounded correction of health misinformation on social platforms. However, they still reset at every post, leaving useful correction experience from prior cases unused. We introduce EvoNote, an agentic framework that enables health Community Notes generation to self-evolve through an evolving experience memory of prior misinformation correction episodes. Its core is fine-grained credit assignment: EvoNote grounds trajectory-level feedback in health-specific note qualities and distills it into action-level memory for claim analysis, evidence acquisition, and note writing. We evaluate EvoNote on MM-HealthCN, a 1.2K-instance multimodal benchmark of user-flagged health posts with human-written Community Notes and crowd-derived helpfulness labels. Under a human-validated hierarchical utility judge, EvoNote-generated notes are preferred over corresponding human-written notes in 89.6% of cases; on a separate set of Needs More Ratings posts without a crowd helpfulness verdict, EvoNote produces helpful notes for 82.0% of cases. It also reduces the median time needed to produce a candidate correction from over 13 hours in the human-note pipeline to under 2 minutes. Analyses link these gains to stronger evidence use and reusable correction strategies, positioning self-evolving note generation as a promising paradigm for health misinformation governance.
Leveraging Latent Visual Reasoning in Silence
May 18, 2026Latent visual reasoning involves visual evidence more directly in multimodal reasoning by inserting continuous latent tokens before textual generation. However, the necessity of these latent tokens at inference remains ambiguous. We show that replacing latent tokens with random noise or removing them completely causes little performance degradation across spatial reasoning benchmarks. Reinforcement learning further diminishes the latent generation behavior after post-training. These observations raise a central question: Is latent visual reasoning still meaningful? We argue that its value should be measured by how effectively latent tokens guide learning, rather than whether they persist as an inference-time format. Our analysis shows that latent reasoning is unevenly favorable across question types, yet hard task-level routing for applying latent generation is brittle. Motivated by these findings, we propose an attention-based reward that encourages generated latent tokens to interact with later text tokens during RL. This reward promotes latent utilization when the latent mode is activated while preserving the flexibility to use pure-text reasoning. Experiments show that our method improves performance across perception and visual reasoning benchmarks, even when latent tokens are rarely generated after post-training. Our results highlight that, without explicit expression at inference, latent visual reasoning can shape better visual grounding and more accurate textual reasoning in silence. Our code and trained models are publicly available at \href{https://github.com/ddydyd32/silent-lvr/tree/master}{GitHub} and \href{https://huggingface.co/collections/cornuHGF/silent-lvr}{Hugging Face}.
TaxaAdapter: Vision Taxonomy Models are Key to Fine-grained Image Generation over the Tree of Life
Mar 27, 2026Accurately generating images across the Tree of Life is difficult: there are over 10M distinct species on Earth, many of which differ only by subtle visual traits. Despite the remarkable progress in text-to-image synthesis, existing models often fail to capture the fine-grained visual cues that define species identity, even when their outputs appear photo-realistic. To this end, we propose TaxaAdapter, a simple and lightweight approach that incorporates Vision Taxonomy Models (VTMs) such as BioCLIP to guide fine-grained species generation. Our method injects VTM embeddings into a frozen text-to-image diffusion model, improving species-level fidelity while preserving flexible text control over attributes such as pose, style, and background. Extensive experiments demonstrate that TaxaAdapter consistently improves morphology fidelity and species-identity accuracy over strong baselines, with a cleaner architecture and training recipe. To better evaluate these improvements, we also introduce a multimodal Large Language Model-based metric that summarizes trait-level descriptions from generated and real images, providing a more interpretable measure of morphological consistency. Beyond this, we observe that TaxaAdapter exhibits strong generalization capabilities, enabling species synthesis in challenging regimes such as few-shot species with only a handful of training images and even species unseen during training. Overall, our results highlight that VTMs are a key ingredient for scalable, fine-grained species generation.
Lessons and Open Questions from a Unified Study of Camera-Trap Species Recognition Over Time
Mar 20, 2026Camera traps are vital for large-scale biodiversity monitoring, yet accurate automated analysis remains challenging due to diverse deployment environments. While the computer vision community has mostly framed this challenge as cross-domain generalization, this perspective overlooks a primary challenge faced by ecological practitioners: maintaining reliable recognition at the fixed site over time, where the dynamic nature of ecosystems introduces profound temporal shifts in both background and animal distributions. To bridge this gap, we present the first unified study of camera-trap species recognition over time. We introduce a realistic benchmark comprising 546 camera traps with a streaming protocol that evaluates models over chronologically ordered intervals. Our end-user-centric study yields four key findings. (1) Biological foundation models (e.g., BioCLIP 2) underperform at numerous sites even in initial intervals, underscoring the necessity of site-specific adaptation. (2) Adaptation is challenging under realistic evaluation: when models are updated using past data and evaluated on future intervals (mirrors real deployment lifecycles), naive adaptation can even degrade below zero-shot performance. (3) We identify two drivers of this difficulty: severe class imbalance and pronounced temporal shift in both species distribution and backgrounds between consecutive intervals. (4) We find that effective integration of model-update and post-processing techniques can largely improve accuracy, though a gap from the upper bounds remains. Finally, we highlight critical open questions, such as predicting when zero-shot models will succeed at a new site and determining whether/when model updates are necessary. Our benchmark and analysis provide actionable deployment guidelines for ecological practitioners while establishing new directions for future research in vision and machine learning.
AVION: Aerial Vision-Language Instruction from Offline Teacher to Prompt-Tuned Network
Mar 13, 2026Adapting vision-language models to remote sensing imagery remains challenging due to two key factors: limited semantic coverage in textual representations and insufficient adaptability of visual features. These issues are particularly significant in aerial scenes, which involve various visual appearances and fine-grained object distinctions. We propose AVION, a knowledge distillation framework tailored for remote sensing adaptation of vision-language models. The teacher module constructs semantically rich textual prototypes by collecting descriptions from a large language model and verifying validity using remote sensing image features. The student module integrates lightweight and learnable prompts into both vision and language encoders, guided by the teacher to align embeddings and their cross-modal relationships. Once trained, the student operates independently during inference. Experiments on six optical remote sensing benchmarks show that AVION improves few-shot classification and base-class accuracy without degrading generalization to novel categories. It also enhances mean recall for cross-modal retrieval, with minimal additional trainable parameters.
Finer-Personalization Rank: Fine-Grained Retrieval Examines Identity Preservation for Personalized Generation
Dec 22, 2025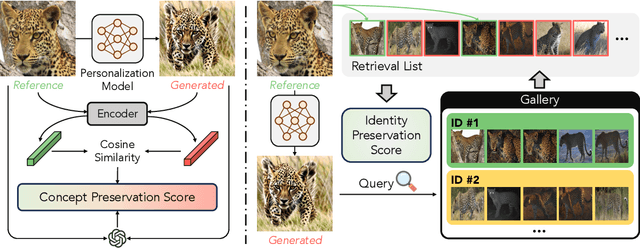
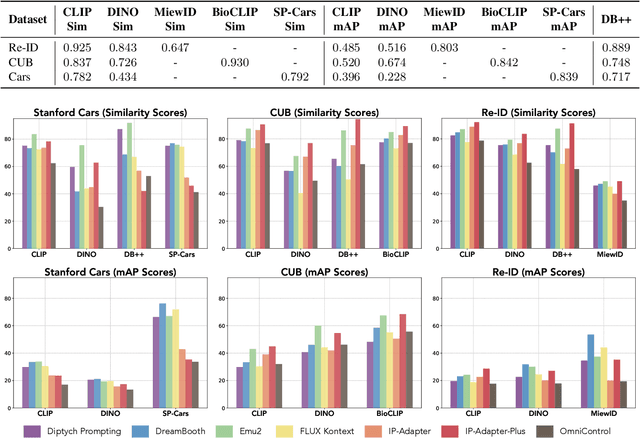

The rise of personalized generative models raises a central question: how should we evaluate identity preservation? Given a reference image (e.g., one's pet), we expect the generated image to retain precise details attached to the subject's identity. However, current generative evaluation metrics emphasize the overall semantic similarity between the reference and the output, and overlook these fine-grained discriminative details. We introduce Finer-Personalization Rank, an evaluation protocol tailored to identity preservation. Instead of pairwise similarity, Finer-Personalization Rank adopts a ranking view: it treats each generated image as a query against an identity-labeled gallery consisting of visually similar real images. Retrieval metrics (e.g., mean average precision) measure performance, where higher scores indicate that identity-specific details (e.g., a distinctive head spot) are preserved. We assess identity at multiple granularities -- from fine-grained categories (e.g., bird species, car models) to individual instances (e.g., re-identification). Across CUB, Stanford Cars, and animal Re-ID benchmarks, Finer-Personalization Rank more faithfully reflects identity retention than semantic-only metrics and reveals substantial identity drift in several popular personalization methods. These results position the gallery-based protocol as a principled and practical evaluation for personalized generation.
BioCLIP 2: Emergent Properties from Scaling Hierarchical Contrastive Learning
May 29, 2025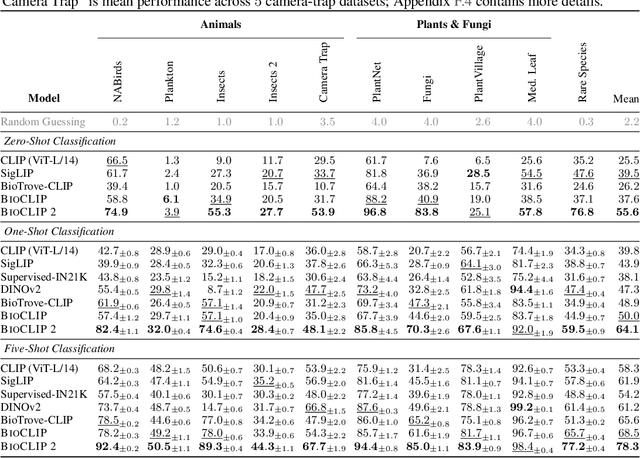
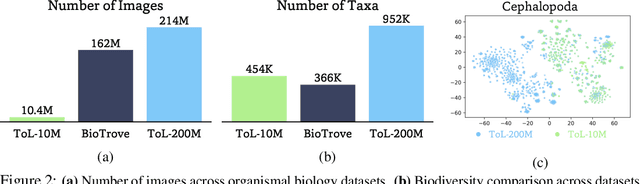
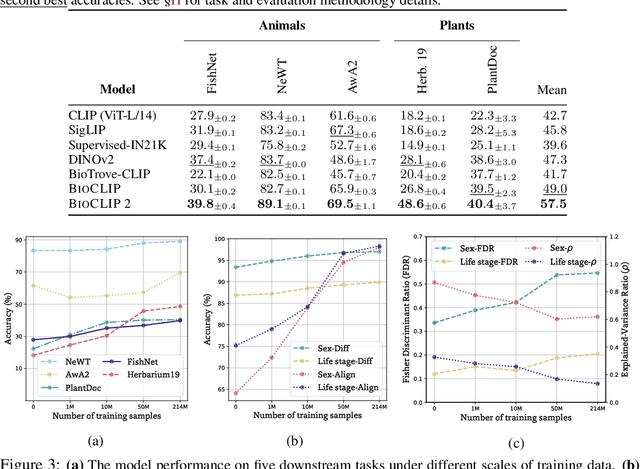
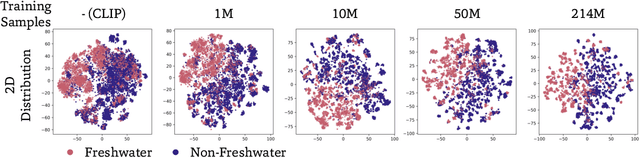
Foundation models trained at scale exhibit remarkable emergent behaviors, learning new capabilities beyond their initial training objectives. We find such emergent behaviors in biological vision models via large-scale contrastive vision-language training. To achieve this, we first curate TreeOfLife-200M, comprising 214 million images of living organisms, the largest and most diverse biological organism image dataset to date. We then train BioCLIP 2 on TreeOfLife-200M to distinguish different species. Despite the narrow training objective, BioCLIP 2 yields extraordinary accuracy when applied to various biological visual tasks such as habitat classification and trait prediction. We identify emergent properties in the learned embedding space of BioCLIP 2. At the inter-species level, the embedding distribution of different species aligns closely with functional and ecological meanings (e.g., beak sizes and habitats). At the intra-species level, instead of being diminished, the intra-species variations (e.g., life stages and sexes) are preserved and better separated in subspaces orthogonal to inter-species distinctions. We provide formal proof and analyses to explain why hierarchical supervision and contrastive objectives encourage these emergent properties. Crucially, our results reveal that these properties become increasingly significant with larger-scale training data, leading to a biologically meaningful embedding space.
Taming Diffusion for Dataset Distillation with High Representativeness
May 23, 2025Recent deep learning models demand larger datasets, driving the need for dataset distillation to create compact, cost-efficient datasets while maintaining performance. Due to the powerful image generation capability of diffusion, it has been introduced to this field for generating distilled images. In this paper, we systematically investigate issues present in current diffusion-based dataset distillation methods, including inaccurate distribution matching, distribution deviation with random noise, and separate sampling. Building on this, we propose D^3HR, a novel diffusion-based framework to generate distilled datasets with high representativeness. Specifically, we adopt DDIM inversion to map the latents of the full dataset from a low-normality latent domain to a high-normality Gaussian domain, preserving information and ensuring structural consistency to generate representative latents for the distilled dataset. Furthermore, we propose an efficient sampling scheme to better align the representative latents with the high-normality Gaussian distribution. Our comprehensive experiments demonstrate that D^3HR can achieve higher accuracy across different model architectures compared with state-of-the-art baselines in dataset distillation. Source code: https://github.com/lin-zhao-resoLve/D3HR.
CONCORD: Concept-Informed Diffusion for Dataset Distillation
May 23, 2025Dataset distillation (DD) has witnessed significant progress in creating small datasets that encapsulate rich information from large original ones. Particularly, methods based on generative priors show promising performance, while maintaining computational efficiency and cross-architecture generalization. However, the generation process lacks explicit controllability for each sample. Previous distillation methods primarily match the real distribution from the perspective of the entire dataset, whereas overlooking concept completeness at the instance level. The missing or incorrectly represented object details cannot be efficiently compensated due to the constrained sample amount typical in DD settings. To this end, we propose incorporating the concept understanding of large language models (LLMs) to perform Concept-Informed Diffusion (CONCORD) for dataset distillation. Specifically, distinguishable and fine-grained concepts are retrieved based on category labels to inform the denoising process and refine essential object details. By integrating these concepts, the proposed method significantly enhances both the controllability and interpretability of the distilled image generation, without relying on pre-trained classifiers. We demonstrate the efficacy of CONCORD by achieving state-of-the-art performance on ImageNet-1K and its subsets. The code implementation is released in https://github.com/vimar-gu/CONCORD.