 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONCORD: Concept-Informed Diffusion for Dataset Distillation
May 23, 2025Dataset distillation (DD) has witnessed significant progress in creating small datasets that encapsulate rich information from large original ones. Particularly, methods based on generative priors show promising performance, while maintaining computational efficiency and cross-architecture generalization. However, the generation process lacks explicit controllability for each sample. Previous distillation methods primarily match the real distribution from the perspective of the entire dataset, whereas overlooking concept completeness at the instance level. The missing or incorrectly represented object details cannot be efficiently compensated due to the constrained sample amount typical in DD settings. To this end, we propose incorporating the concept understanding of large language models (LLMs) to perform Concept-Informed Diffusion (CONCORD) for dataset distillation. Specifically, distinguishable and fine-grained concepts are retrieved based on category labels to inform the denoising process and refine essential object details. By integrating these concepts, the proposed method significantly enhances both the controllability and interpretability of the distilled image generation, without relying on pre-trained classifiers. We demonstrate the efficacy of CONCORD by achieving state-of-the-art performance on ImageNet-1K and its subsets. The code implementation is released in https://github.com/vimar-gu/CONCORD.
CoreInfer: Accelerating Large Language Model Inference with Semantics-Inspired Adaptive Sparse Activation
Oct 23, 2024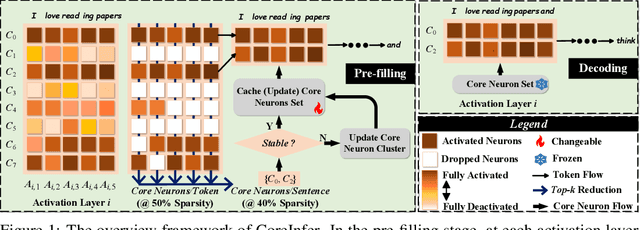

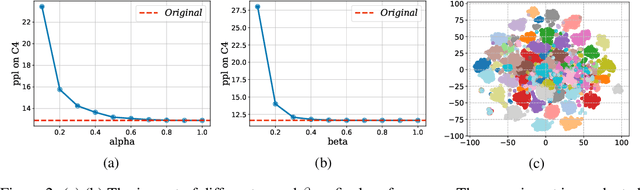

Large language models (LLMs) with billions of parameters have sparked a new wave of exciting AI applications. However, their high computational costs and memory demands during inference pose significant challenges. Adaptive sparse activation inference, which activates only a small number of neurons for each token, offers a novel way to accelerate model inference without degrading performance, showing great potential for resource-constrained hardware devices. Nevertheless, existing methods predict activated neurons based on individual tokens with additional MLP, which involve frequent changes in activation maps and resource calls, limiting the acceleration benefits of sparse activation. In this paper, we introduce CoreInfer, an MLP-free adaptive sparse activation inference method based on sentence-level prediction. Specifically, we propose the concept of sentence-wise core neurons, which refers to the subset of neurons most critical for a given sentence, and empirically demonstrate its effectiveness. To determine the core neurons, we explore the correlation between core neurons and the sentence's semantics. Remarkably, we discovered that core neurons exhibit both stability and similarity in relation to the sentence's semantics -- an insight overlooked by previous studies. Building on this finding, we further design two semantic-based methods for predicting core neurons to fit different input scenarios. In CoreInfer, the core neurons are determined during the pre-filling stage and fixed during the encoding stage, enabling zero-cost sparse inference. We evaluated the model generalization and task generalization of CoreInfer across various models and tasks. Notably, on an NVIDIA TITAN XP GPU, CoreInfer achieved a 10.33 times and 2.72 times speedup compared to the Huggingface implementation and PowerInfer, respectively.
Dataset Distillation from First Principles: Integrating Core Information Extraction and Purposeful Learning
Sep 02, 2024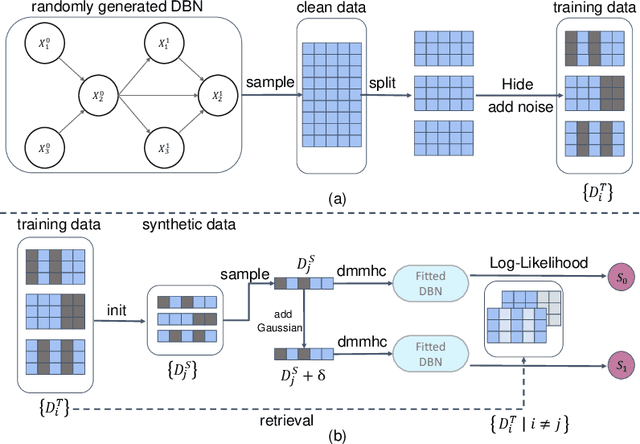
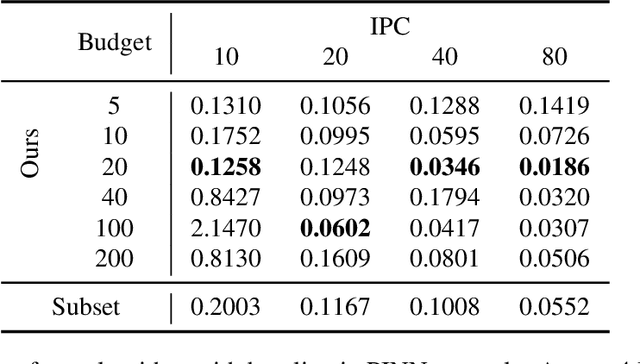
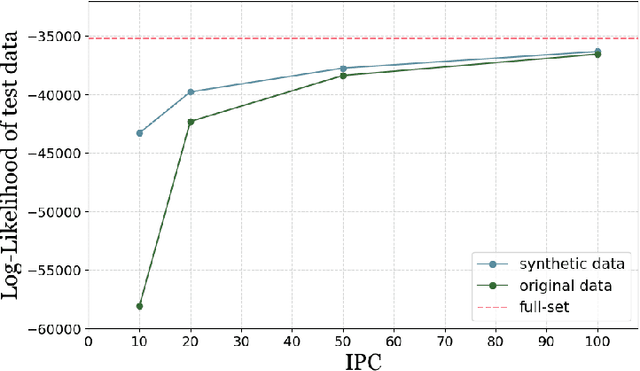
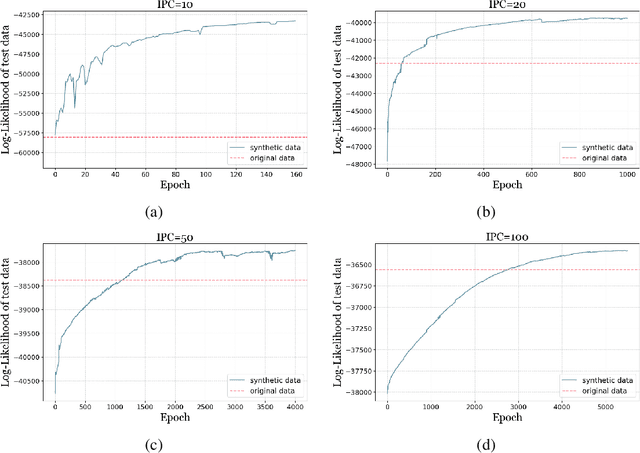
Dataset distillation (DD) is an increasingly important technique that focuses on constructing a synthetic dataset capable of capturing the core information in training data to achieve comparable performance in models trained on the latter. While DD has a wide range of applications, the theory supporting it is less well evolved. New methods of DD are compared on a common set of benchmarks, rather than oriented towards any particular learning task. In this work, we present a formal model of DD, arguing that a precise characterization of the underlying optimization problem must specify the inference task associated with the application of interest. Without this task-specific focus, the DD problem is under-specified, and the selection of a DD algorithm for a particular task is merely heuristic. Our formalization reveals novel applications of DD across different modeling environments. We analyze existing DD methods through this broader lens, highlighting their strengths and limitations in terms of accuracy and faithfulness to optimal DD operation. Finally, we present numerical results for two case studies important in contemporary settings. Firstly, we address a critical challenge in medical data analysis: merging the knowledge from different datasets composed of intersecting, but not identical, sets of features, in order to construct a larger dataset in what is usually a small sample setting. Secondly, we consider out-of-distribution error across boundary conditions for physics-informed neural networks (PINNs), showing the potential for DD to provide more physically faithful data. By establishing this general formulation of DD, we aim to establish a new research paradigm by which DD can be understood and from which new DD techniques can arise.
Exploring the Impact of Dataset Bias on Dataset Distillation
Mar 24, 2024



Dataset Distillation (DD) is a promising technique to synthesize a smaller dataset that preserves essential information from the original dataset. This synthetic dataset can serve as a substitute for the original large-scale one, and help alleviate the training workload. However, current DD methods typically operate under the assumption that the dataset is unbiased, overlooking potential bias issues within the dataset itself. To fill in this blank, we systematically investigate the influence of dataset bias on DD. To the best of our knowledge, this is the first exploration in the DD domain. Given that there are no suitable biased datasets for DD, we first construct two biased datasets, CMNIST-DD and CCIFAR10-DD, to establish a foundation for subsequent analysis. Then we utilize existing DD methods to generate synthetic datasets on CMNIST-DD and CCIFAR10-DD, and evaluate their performance following the standard process. Experiments demonstrate that biases present in the original dataset significantly impact the performance of the synthetic dataset in most cases, which highlights the necessity of identifying and mitigating biases in the original datasets during DD. Finally, we reformulate DD within the context of a biased dataset. Our code along with biased datasets are available at https://github.com/yaolu-zjut/Biased-DD.
Group Distributionally Robust Dataset Distillation with Risk Minimization
Feb 07, 2024



Dataset distillation (DD) has emerged as a widely adopted technique for crafting a synthetic dataset that captures the essential information of a training dataset, facilitating the training of accurate neural models. Its applications span various domains, including transfer learning, federated learning, and neural architecture search. The most popular methods for constructing the synthetic data rely on matching the convergence properties of training the model with the synthetic dataset and the training dataset. However, targeting the training dataset must be thought of as auxiliary in the same sense that the training set is an approximate substitute for the population distribution, and the latter is the data of interest. Yet despite its popularity, an aspect that remains unexplored is the relationship of DD to its generalization, particularly across uncommon subgroups. That is, how can we ensure that a model trained on the synthetic dataset performs well when faced with samples from regions with low population density? Here, the representativeness and coverage of the dataset become salient over the guaranteed training error at inference. Drawing inspiration from distributionally robust optimization, we introduce an algorithm that combines clustering with the minimization of a risk measure on the loss to conduct DD. We provide a theoretical rationale for our approach and demonstrate its effective generalization and robustness across subgroups through numerical experiments.
Unlocking the Potential of Federated Learning: The Symphony of Dataset Distillation via Deep Generative Latents
Dec 03, 2023



Data heterogeneity presents significant challenges for federated learning (FL). Recently, dataset distillation techniques have been introduced, and performed at the client level, to attempt to mitigate some of these challenges. In this paper, we propose a highly efficient FL dataset distillation framework on the server side, significantly reducing both the computational and communication demands on local devices while enhancing the clients' privacy. Unlike previous strategies that perform dataset distillation on local devices and upload synthetic data to the server, our technique enables the server to leverage prior knowledge from pre-trained deep generative models to synthesize essential data representations from a heterogeneous model architecture. This process allows local devices to train smaller surrogate models while enabling the training of a larger global model on the server, effectively minimizing resource utilization. We substantiate our claim with a theoretical analysis, demonstrating the asymptotic resemblance of the process to the hypothetical ideal of completely centralized training on a heterogeneous dataset. Empirical evidence from our comprehensive experiments indicates our method's superiority, delivering an accuracy enhancement of up to 40% over non-dataset-distillation techniques in highly heterogeneous FL contexts, and surpassing existing dataset-distillation methods by 18%. In addition to the high accuracy, our framework converges faster than the baselines because rather than the server trains on several sets of heterogeneous data distributions, it trains on a multi-modal distribution. Our code is available at https://github.com/FedDG23/FedDG-main.git
Efficient Dataset Distillation via Minimax Diffusion
Nov 27, 2023Dataset distillation reduces the storage and computational consumption of training a network by generating a small surrogate dataset that encapsulates rich information of the original large-scale one. However, previous distillation methods heavily rely on the sample-wise iterative optimization scheme. As the images-per-class (IPC) setting or image resolution grows larger, the necessary computation will demand overwhelming time and resources. In this work, we intend to incorporate generative diffusion techniques for computing the surrogate dataset. Observing that key factors for constructing an effective surrogate dataset are representativeness and diversity, we design additional minimax criteria in the generative training to enhance these facets for the generated images of diffusion models. We present a theoretical model of the process as hierarchical diffusion control demonstrating the flexibility of the diffusion process to target these criteria without jeopardizing the faithfulness of the sample to the desired distribution. The proposed method achieves state-of-the-art validation performance while demanding much less computational resources. Under the 100-IPC setting on ImageWoof, our method requires less than one-twentieth the distillation time of previous methods, yet yields even better performance. Source code available in https://github.com/vimar-gu/MinimaxDiffusion.
CEFHRI: A Communication Efficient Federated Learning Framework for Recognizing Industrial Human-Robot Interaction
Aug 29, 2023



Human-robot interaction (HRI) is a rapidly growing field that encompasses social and industrial applications. Machine learning plays a vital role in industrial HRI by enhancing the adaptability and autonomy of robots in complex environments. However, data privacy is a crucial concern in the interaction between humans and robots, as companies need to protect sensitive data while machine learning algorithms require access to large datasets. Federated Learning (FL) offers a solution by enabling the distributed training of models without sharing raw data. Despite extensive research on Federated learning (FL) for tasks such as natural language processing (NLP) and image classification, the question of how to use FL for HRI remains an open research problem. The traditional FL approach involves transmitting large neural network parameter matrices between the server and clients, which can lead to high communication costs and often becomes a bottleneck in FL. This paper proposes a communication-efficient FL framework for human-robot interaction (CEFHRI) to address the challenges of data heterogeneity and communication costs. The framework leverages pre-trained models and introduces a trainable spatiotemporal adapter for video understanding tasks in HRI. Experimental results on three human-robot interaction benchmark datasets: HRI30, InHARD, and COIN demonstrate the superiority of CEFHRI over full fine-tuning in terms of communication costs. The proposed methodology provides a secure and efficient approach to HRI federated learning, particularly in industrial environments with data privacy concerns and limited communication bandwidth. Our code is available at https://github.com/umarkhalidAI/CEFHRI-Efficient-Federated-Learning.
Towards Building the Federated GPT: Federated Instruction Tuning
May 09, 2023



While ``instruction-tuned" generative large language models (LLMs) have demonstrated an impressive ability to generalize to new tasks, the training phases heavily rely on large amounts of diverse and high-quality instruction data (such as ChatGPT and GPT-4). Unfortunately, acquiring high-quality data, especially when it comes to human-written data, can pose significant challenges both in terms of cost and accessibility. Moreover, concerns related to privacy can further limit access to such data, making the process of obtaining it a complex and nuanced undertaking. Consequently, this hinders the generality of the tuned models and may restrict their effectiveness in certain contexts. To tackle this issue, our study introduces a new approach called Federated Instruction Tuning (FedIT), which leverages federated learning (FL) as the learning framework for the instruction tuning of LLMs. This marks the first exploration of FL-based instruction tuning for LLMs. This is especially important since text data is predominantly generated by end users. Therefore, it is imperative to design and adapt FL approaches to effectively leverage these users' diverse instructions stored on local devices, while preserving privacy and ensuring data security. In the current paper, by conducting widely used GPT-4 auto-evaluation, we demonstrate that by exploiting the heterogeneous and diverse sets of instructions on the client's end with the proposed framework FedIT, we improved the performance of LLMs compared to centralized training with only limited local instructions. Further, in this paper, we developed a Github repository named Shepherd. This repository offers a foundational framework for exploring federated fine-tuning of LLMs using heterogeneous instructions across diverse categories.
When Do Curricula Work in Federated Learning?
Dec 24, 2022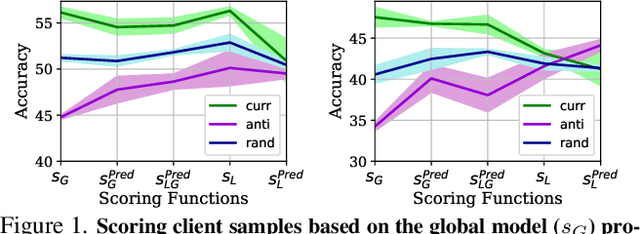

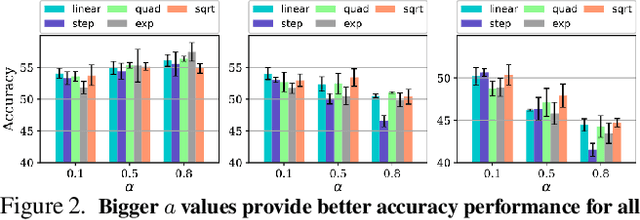
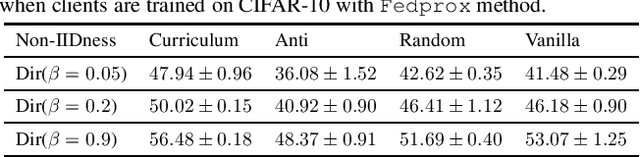
An oft-cited open problem of federated learning is the existence of data heterogeneity at the clients. One pathway to understanding the drastic accuracy drop in federated learning is by scrutinizing the behavior of the clients' deep models on data with different levels of "difficulty", which has been left unaddressed. In this paper, we investigate a different and rarely studied dimension of FL: ordered learning. Specifically, we aim to investigate how ordered learning principles can contribute to alleviating the heterogeneity effects in FL. We present theoretical analysis and conduct extensive empirical studies on the efficacy of orderings spanning three kinds of learning: curriculum, anti-curriculum, and random curriculum. We find that curriculum learning largely alleviates non-IIDness. Interestingly, the more disparate the data distributions across clients the more they benefit from ordered learning. We provide analysis explaining this phenomenon, specifically indicating how curriculum training appears to make the objective landscape progressively less convex, suggesting fast converging iterations at the beginning of the training procedure. We derive quantitative results of convergence for both convex and nonconvex objectives by modeling the curriculum training on federated devices as local SGD with locally biased stochastic gradients. Also, inspired by ordered learning, we propose a novel client selection technique that benefits from the real-world disparity in the clients. Our proposed approach to client selection has a synergic effect when applied together with ordered learning in FL.