 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSF-4D: A Progressive Sampling Framework for View Consistent 4D Editing
Mar 14, 2025Instruction-guided generative models, especially those using text-to-image (T2I) and text-to-video (T2V) diffusion frameworks, have advanced the field of content editing in recent years. To extend these capabilities to 4D scene, we introduce a progressive sampling framework for 4D editing (PSF-4D) that ensures temporal and multi-view consistency by intuitively controlling the noise initialization during forward diffusion. For temporal coherence, we design a correlated Gaussian noise structure that links frames over time, allowing each frame to depend meaningfully on prior frames. Additionally, to ensure spatial consistency across views, we implement a cross-view noise model, which uses shared and independent noise components to balance commonalities and distinct details among different views. To further enhance spatial coherence, PSF-4D incorporates view-consistent iterative refinement, embedding view-aware information into the denoising process to ensure aligned edits across frames and views. Our approach enables high-quality 4D editing without relying on external models, addressing key challenges in previous methods. Through extensive evaluation on multiple benchmarks and multiple editing aspects (e.g., style transfer, multi-attribute editing, object removal, local editing, etc.), we show the effectiveness of our proposed method. Experimental results demonstrate that our proposed method outperforms state-of-the-art 4D editing methods in diverse benchmarks.
EVLM: Self-Reflective Multimodal Reasoning for Cross-Dimensional Visual Editing
Dec 13, 2024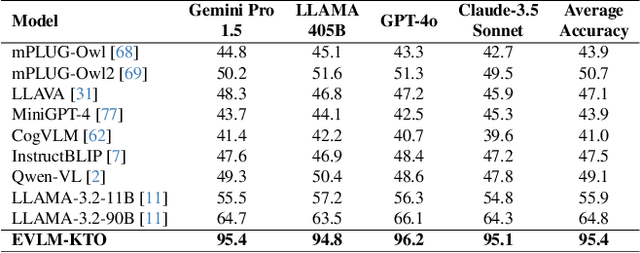



Editing complex visual content based on ambiguous instructions remains a challenging problem in vision-language modeling. While existing models can contextualize content, they often struggle to grasp the underlying intent within a reference image or scene, leading to misaligned edits. We introduce the Editing Vision-Language Model (EVLM), a system designed to interpret such instructions in conjunction with reference visuals, producing precise and context-aware editing prompts. Leveraging Chain-of-Thought (CoT) reasoning and KL-Divergence Target Optimization (KTO) alignment technique, EVLM captures subjective editing preferences without requiring binary labels. Fine-tuned on a dataset of 30,000 CoT examples, with rationale paths rated by human evaluators, EVLM demonstrates substantial improvements in alignment with human intentions. Experiments across image, video, 3D, and 4D editing tasks show that EVLM generates coherent, high-quality instructions, supporting a scalable framework for complex vision-language applications.
The Role of Language Models in Modern Healthcare: A Comprehensive Review
Sep 25, 2024The application of large language models (LLMs) in healthcare has gained significant attention due to their ability to process complex medical data and provide insights for clinical decision-making. These models have demonstrated substantial capabilities in understanding and generating natural language, which is crucial for medical documentation, diagnostics, and patient interaction. This review examines the trajectory of language models from their early stages to the current state-of-the-art LLMs, highlighting their strengths in healthcare applications and discussing challenges such as data privacy, bias, and ethical considerations. The potential of LLMs to enhance healthcare delivery is explored, alongside the necessary steps to ensure their ethical and effective integration into medical practice.
3DEgo: 3D Editing on the Go!
Jul 14, 2024We introduce 3DEgo to address a novel problem of directly synthesizing photorealistic 3D scenes from monocular videos guided by textual prompts. Conventional methods construct a text-conditioned 3D scene through a three-stage process, involving pose estimation using Structure-from-Motion (SfM) libraries like COLMAP, initializing the 3D model with unedited images, and iteratively updating the dataset with edited images to achieve a 3D scene with text fidelity. Our framework streamlines the conventional multi-stage 3D editing process into a single-stage workflow by overcoming the reliance on COLMAP and eliminating the cost of model initialization. We apply a diffusion model to edit video frames prior to 3D scene creation by incorporating our designed noise blender module for enhancing multi-view editing consistency, a step that does not require additional training or fine-tuning of T2I diffusion models. 3DEgo utilizes 3D Gaussian Splatting to create 3D scenes from the multi-view consistent edited frames, capitalizing on the inherent temporal continuity and explicit point cloud data. 3DEgo demonstrates remarkable editing precision, speed, and adaptability across a variety of video sources, as validated by extensive evaluations on six datasets, including our own prepared GS25 dataset. Project Page: https://3dego.github.io/
Augmented Neural Fine-Tuning for Efficient Backdoor Purification
Jul 14, 2024



Recent studies have revealed the vulnerability of deep neural networks (DNNs) to various backdoor attacks, where the behavior of DNNs can be compromised by utilizing certain types of triggers or poisoning mechanisms. State-of-the-art (SOTA) defenses employ too-sophisticated mechanisms that require either a computationally expensive adversarial search module for reverse-engineering the trigger distribution or an over-sensitive hyper-parameter selection module. Moreover, they offer sub-par performance in challenging scenarios, e.g., limited validation data and strong attacks. In this paper, we propose Neural mask Fine-Tuning (NFT) with an aim to optimally re-organize the neuron activities in a way that the effect of the backdoor is removed. Utilizing a simple data augmentation like MixUp, NFT relaxes the trigger synthesis process and eliminates the requirement of the adversarial search module. Our study further reveals that direct weight fine-tuning under limited validation data results in poor post-purification clean test accuracy, primarily due to overfitting issue. To overcome this, we propose to fine-tune neural masks instead of model weights. In addition, a mask regularizer has been devised to further mitigate the model drift during the purification process. The distinct characteristics of NFT render it highly efficient in both runtime and sample usage, as it can remove the backdoor even when a single sample is available from each class. We validate the effectiveness of NFT through extensive experiments covering the tasks of image classification, object detection, video action recognition, 3D point cloud, and natural language processing. We evaluate our method against 14 different attacks (LIRA, WaNet, etc.) on 11 benchmark data sets such as ImageNet, UCF101, Pascal VOC, ModelNet, OpenSubtitles2012, etc.
Free-Editor: Zero-shot Text-driven 3D Scene Editing
Dec 21, 2023



Text-to-Image (T2I) diffusion models have gained popularity recently due to their multipurpose and easy-to-use nature, e.g. image and video generation as well as editing. However, training a diffusion model specifically for 3D scene editing is not straightforward due to the lack of large-scale datasets. To date, editing 3D scenes requires either re-training the model to adapt to various 3D edited scenes or design-specific methods for each special editing type. Furthermore, state-of-the-art (SOTA) methods require multiple synchronized edited images from the same scene to facilitate the scene editing. Due to the current limitations of T2I models, it is very challenging to apply consistent editing effects to multiple images, i.e. multi-view inconsistency in editing. This in turn compromises the desired 3D scene editing performance if these images are used. In our work, we propose a novel training-free 3D scene editing technique, Free-Editor, which allows users to edit 3D scenes without further re-training the model during test time. Our proposed method successfully avoids the multi-view style inconsistency issue in SOTA methods with the help of a "single-view editing" scheme. Specifically, we show that editing a particular 3D scene can be performed by only modifying a single view. To this end, we introduce an Edit Transformer that enforces intra-view consistency and inter-view style transfer by utilizing self- and cross-attention, respectively. Since it is no longer required to re-train the model and edit every view in a scene, the editing time, as well as memory resources, are reduced significantly, e.g., the runtime being $\sim \textbf{20} \times$ faster than SOTA. We have conducted extensive experiments on a wide range of benchmark datasets and achieve diverse editing capabilities with our proposed technique.
LatentEditor: Text Driven Local Editing of 3D Scenes
Dec 18, 2023While neural fields have made significant strides in view synthesis and scene reconstruction, editing them poses a formidable challenge due to their implicit encoding of geometry and texture information from multi-view inputs. In this paper, we introduce \textsc{LatentEditor}, an innovative framework designed to empower users with the ability to perform precise and locally controlled editing of neural fields using text prompts. Leveraging denoising diffusion models, we successfully embed real-world scenes into the latent space, resulting in a faster and more adaptable NeRF backbone for editing compared to traditional methods. To enhance editing precision, we introduce a delta score to calculate the 2D mask in the latent space that serves as a guide for local modifications while preserving irrelevant regions. Our novel pixel-level scoring approach harnesses the power of InstructPix2Pix (IP2P) to discern the disparity between IP2P conditional and unconditional noise predictions in the latent space. The edited latents conditioned on the 2D masks are then iteratively updated in the training set to achieve 3D local editing. Our approach achieves faster editing speeds and superior output quality compared to existing 3D editing models, bridging the gap between textual instructions and high-quality 3D scene editing in latent space. We show the superiority of our approach on four benchmark 3D datasets, LLFF, IN2N, NeRFStudio and NeRF-Art.
CEFHRI: A Communication Efficient Federated Learning Framework for Recognizing Industrial Human-Robot Interaction
Aug 29, 2023



Human-robot interaction (HRI) is a rapidly growing field that encompasses social and industrial applications. Machine learning plays a vital role in industrial HRI by enhancing the adaptability and autonomy of robots in complex environments. However, data privacy is a crucial concern in the interaction between humans and robots, as companies need to protect sensitive data while machine learning algorithms require access to large datasets. Federated Learning (FL) offers a solution by enabling the distributed training of models without sharing raw data. Despite extensive research on Federated learning (FL) for tasks such as natural language processing (NLP) and image classification, the question of how to use FL for HRI remains an open research problem. The traditional FL approach involves transmitting large neural network parameter matrices between the server and clients, which can lead to high communication costs and often becomes a bottleneck in FL. This paper proposes a communication-efficient FL framework for human-robot interaction (CEFHRI) to address the challenges of data heterogeneity and communication costs. The framework leverages pre-trained models and introduces a trainable spatiotemporal adapter for video understanding tasks in HRI. Experimental results on three human-robot interaction benchmark datasets: HRI30, InHARD, and COIN demonstrate the superiority of CEFHRI over full fine-tuning in terms of communication costs. The proposed methodology provides a secure and efficient approach to HRI federated learning, particularly in industrial environments with data privacy concerns and limited communication bandwidth. Our code is available at https://github.com/umarkhalidAI/CEFHRI-Efficient-Federated-Learning.
Efficient Backdoor Removal Through Natural Gradient Fine-tuning
Jun 30, 2023



The success of a deep neural network (DNN) heavily relies on the details of the training scheme; e.g., training data, architectures, hyper-parameters, etc. Recent backdoor attacks suggest that an adversary can take advantage of such training details and compromise the integrity of a DNN. Our studies show that a backdoor model is usually optimized to a bad local minima, i.e. sharper minima as compared to a benign model. Intuitively, a backdoor model can be purified by reoptimizing the model to a smoother minima through fine-tuning with a few clean validation data. However, fine-tuning all DNN parameters often requires huge computational costs and often results in sub-par clean test performance. To address this concern, we propose a novel backdoor purification technique, Natural Gradient Fine-tuning (NGF), which focuses on removing the backdoor by fine-tuning only one layer. Specifically, NGF utilizes a loss surface geometry-aware optimizer that can successfully overcome the challenge of reaching a smooth minima under a one-layer optimization scenario. To enhance the generalization performance of our proposed method, we introduce a clean data distribution-aware regularizer based on the knowledge of loss surface curvature matrix, i.e., Fisher Information Matrix. Extensive experiments show that the proposed method achieves state-of-the-art performance on a wide range of backdoor defense benchmarks: four different datasets- CIFAR10, GTSRB, Tiny-ImageNet, and ImageNet; 13 recent backdoor attacks, e.g. Blend, Dynamic, WaNet, ISSBA, etc.
Unsupervised Anomaly Detection in Medical Images Using Masked Diffusion Model
May 31, 2023


It can be challenging to identify brain MRI anomalies using supervised deep-learning techniques due to anatomical heterogeneity and the requirement for pixel-level labeling. Unsupervised anomaly detection approaches provide an alternative solution by relying only on sample-level labels of healthy brains to generate a desired representation to identify abnormalities at the pixel level. Although, generative models are crucial for generating such anatomically consistent representations of healthy brains, accurately generating the intricate anatomy of the human brain remains a challenge. In this study, we present a method called masked-DDPM (mDPPM), which introduces masking-based regularization to reframe the generation task of diffusion models. Specifically, we introduce Masked Image Modeling (MIM) and Masked Frequency Modeling (MFM) in our self-supervised approach that enables models to learn visual representations from unlabeled data. To the best of our knowledge, this is the first attempt to apply MFM in DPPM models for medical applications. We evaluate our approach on datasets containing tumors and numerous sclerosis lesions and exhibit the superior performance of our unsupervised method as compared to the existing fully/weakly supervised baselines. Code is available at https://github.com/hasan1292/mDDPM.