 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertMask: Certifiable Defense Against Adversarial Patches via Theoretically Optimal Mask Coverage
Nov 13, 2025Adversarial patch attacks inject localized perturbations into images to mislead deep vision models. These attacks can be physically deployed, posing serious risks to real-world applications. In this paper, we propose CertMask, a certifiably robust defense that constructs a provably sufficient set of binary masks to neutralize patch effects with strong theoretical guarantees. While the state-of-the-art approach (PatchCleanser) requires two rounds of masking and incurs $O(n^2)$ inference cost, CertMask performs only a single round of masking with $O(n)$ time complexity, where $n$ is the cardinality of the mask set to cover an input image. Our proposed mask set is computed using a mathematically rigorous coverage strategy that ensures each possible patch location is covered at least $k$ times, providing both efficiency and robustness. We offer a theoretical analysis of the coverage condition and prove its sufficiency for certification. Experiments on ImageNet, ImageNette, and CIFAR-10 show that CertMask improves certified robust accuracy by up to +13.4\% over PatchCleanser, while maintaining clean accuracy nearly identical to the vanilla model.
Fisher Information guided Purification against Backdoor Attacks
Sep 01, 2024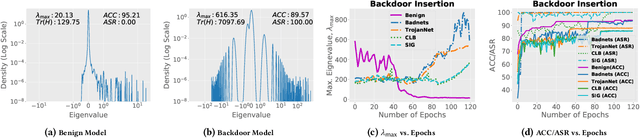
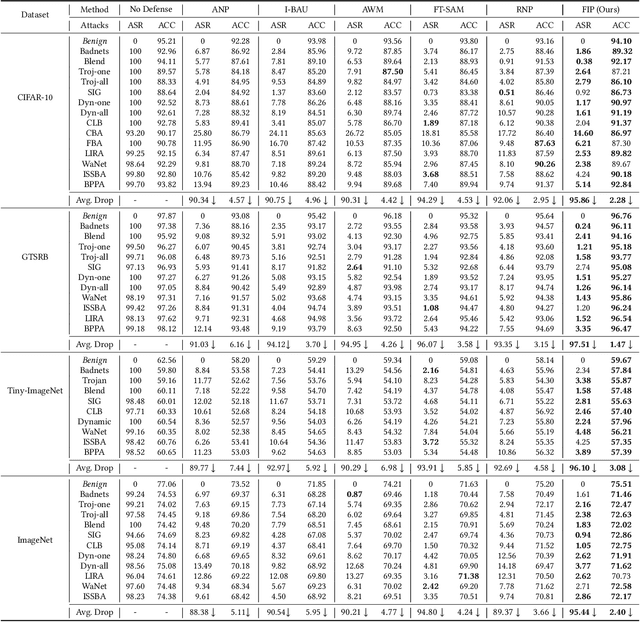
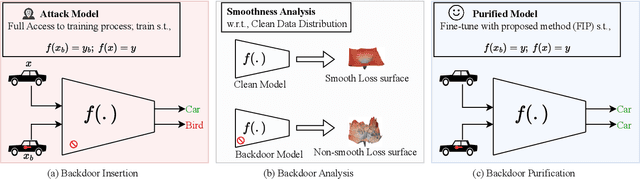

Studies on backdoor attacks in recent years suggest that an adversary can compromise the integrity of a deep neural network (DNN) by manipulating a small set of training samples. Our analysis shows that such manipulation can make the backdoor model converge to a bad local minima, i.e., sharper minima as compared to a benign model. Intuitively, the backdoor can be purified by re-optimizing the model to smoother minima. However, a na\"ive adoption of any optimization targeting smoother minima can lead to sub-optimal purification techniques hampering the clean test accuracy. Hence, to effectively obtain such re-optimization, inspired by our novel perspective establishing the connection between backdoor removal and loss smoothness, we propose Fisher Information guided Purification (FIP), a novel backdoor purification framework. Proposed FIP consists of a couple of novel regularizers that aid the model in suppressing the backdoor effects and retaining the acquired knowledge of clean data distribution throughout the backdoor removal procedure through exploiting the knowledge of Fisher Information Matrix (FIM). In addition, we introduce an efficient variant of FIP, dubbed as Fast FIP, which reduces the number of tunable parameters significantly and obtains an impressive runtime gain of almost $5\times$. Extensive experiments show that the proposed method achieves state-of-the-art (SOTA) performance on a wide range of backdoor defense benchmarks: 5 different tasks -- Image Recognition, Object Detection, Video Action Recognition, 3D point Cloud, Language Generation; 11 different datasets including ImageNet, PASCAL VOC, UCF101; diverse model architectures spanning both CNN and vision transformer; 14 different backdoor attacks, e.g., Dynamic, WaNet, LIRA, ISSBA, etc.
Augmented Neural Fine-Tuning for Efficient Backdoor Purification
Jul 14, 2024



Recent studies have revealed the vulnerability of deep neural networks (DNNs) to various backdoor attacks, where the behavior of DNNs can be compromised by utilizing certain types of triggers or poisoning mechanisms. State-of-the-art (SOTA) defenses employ too-sophisticated mechanisms that require either a computationally expensive adversarial search module for reverse-engineering the trigger distribution or an over-sensitive hyper-parameter selection module. Moreover, they offer sub-par performance in challenging scenarios, e.g., limited validation data and strong attacks. In this paper, we propose Neural mask Fine-Tuning (NFT) with an aim to optimally re-organize the neuron activities in a way that the effect of the backdoor is removed. Utilizing a simple data augmentation like MixUp, NFT relaxes the trigger synthesis process and eliminates the requirement of the adversarial search module. Our study further reveals that direct weight fine-tuning under limited validation data results in poor post-purification clean test accuracy, primarily due to overfitting issue. To overcome this, we propose to fine-tune neural masks instead of model weights. In addition, a mask regularizer has been devised to further mitigate the model drift during the purification process. The distinct characteristics of NFT render it highly efficient in both runtime and sample usage, as it can remove the backdoor even when a single sample is available from each class. We validate the effectiveness of NFT through extensive experiments covering the tasks of image classification, object detection, video action recognition, 3D point cloud, and natural language processing. We evaluate our method against 14 different attacks (LIRA, WaNet, etc.) on 11 benchmark data sets such as ImageNet, UCF101, Pascal VOC, ModelNet, OpenSubtitles2012, etc.
Efficient Backdoor Removal Through Natural Gradient Fine-tuning
Jun 30, 2023



The success of a deep neural network (DNN) heavily relies on the details of the training scheme; e.g., training data, architectures, hyper-parameters, etc. Recent backdoor attacks suggest that an adversary can take advantage of such training details and compromise the integrity of a DNN. Our studies show that a backdoor model is usually optimized to a bad local minima, i.e. sharper minima as compared to a benign model. Intuitively, a backdoor model can be purified by reoptimizing the model to a smoother minima through fine-tuning with a few clean validation data. However, fine-tuning all DNN parameters often requires huge computational costs and often results in sub-par clean test performance. To address this concern, we propose a novel backdoor purification technique, Natural Gradient Fine-tuning (NGF), which focuses on removing the backdoor by fine-tuning only one layer. Specifically, NGF utilizes a loss surface geometry-aware optimizer that can successfully overcome the challenge of reaching a smooth minima under a one-layer optimization scenario. To enhance the generalization performance of our proposed method, we introduce a clean data distribution-aware regularizer based on the knowledge of loss surface curvature matrix, i.e., Fisher Information Matrix. Extensive experiments show that the proposed method achieves state-of-the-art performance on a wide range of backdoor defense benchmarks: four different datasets- CIFAR10, GTSRB, Tiny-ImageNet, and ImageNet; 13 recent backdoor attacks, e.g. Blend, Dynamic, WaNet, ISSBA, etc.
Optimizing Real-Time Performances for Timed-Loop Racing under F1TENTH
Dec 08, 2022



Motion planning and control in autonomous car racing are one of the most challenging and safety-critical tasks due to high speed and dynamism. The lower-level control nodes are expected to be highly optimized due to resource constraints of onboard embedded processing units, although there are strict latency requirements. Some of these guarantees can be provided at the application level, such as using ROS2's Real-Time executors. However, the performance can be far from satisfactory as many modern control algorithms (such as Model Predictive Control) rely on solving complicated online optimization problems at each iteration. In this paper, we present a simple yet effective multi-threading technique to optimize the throughput of online-control algorithms for resource-constrained autonomous racing platforms. We achieve this by maintaining a systematic pool of worker threads solving the optimization problem in parallel which can improve the system performance by reducing latency between control input commands. We further demonstrate the effectiveness of our method using the Model Predictive Contouring Control (MPCC) algorithm running on Nvidia's Xavier AGX platform.
GLARE: A Dataset for Traffic Sign Detection in Sun Glare
Sep 19, 2022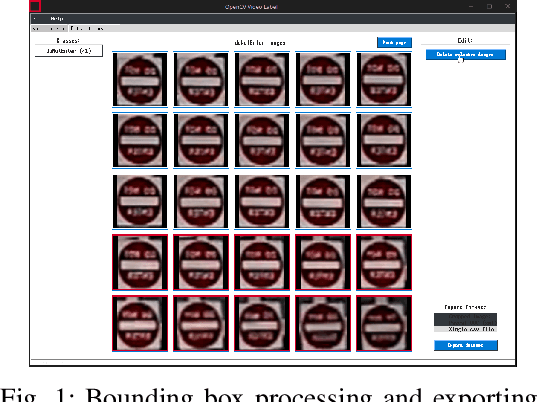
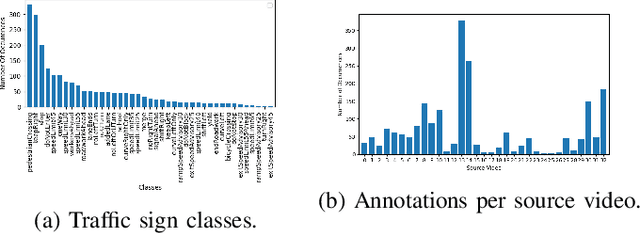

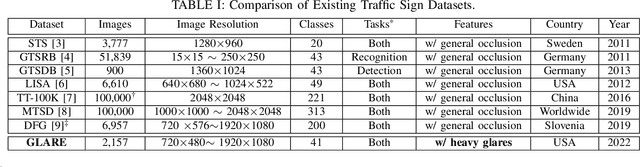
Real-time machine learning detection algorithms are often found within autonomous vehicle technology and depend on quality datasets. It is essential that these algorithms work correctly in everyday conditions as well as under strong sun glare. Reports indicate glare is one of the two most prominent environment-related reasons for crashes. However, existing datasets, such as LISA and the German Traffic Sign Recognition Benchmark, do not reflect the existence of sun glare at all. This paper presents the GLARE traffic sign dataset: a collection of images with U.S based traffic signs under heavy visual interference by sunlight. GLARE contains 2,157 images of traffic signs with sun glare, pulled from 33 videos of dashcam footage of roads in the United States. It provides an essential enrichment to the widely used LISA Traffic Sign dataset. Our experimental study shows that although several state-of-the-art baseline methods demonstrate superior performance when trained and tested against traffic sign datasets without sun glare, they greatly suffer when tested against GLARE (e.g., ranging from 9% to 21% mean mAP, which is significantly lower than the performances on LISA dataset). We also notice that current architectures have better detection accuracy (e.g., on average 42% mean mAP gain for mainstream algorithms) when trained on images of traffic signs in sun glare.
AA-Forecast: Anomaly-Aware Forecast for Extreme Events
Aug 21, 2022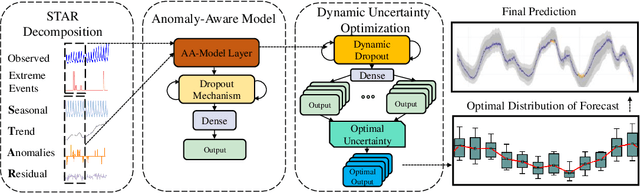
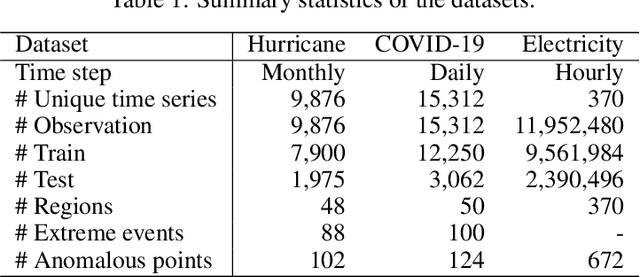
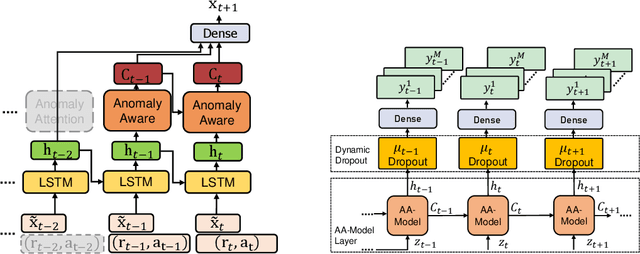

Time series models often deal with extreme events and anomalies, both prevalent in real-world datasets. Such models often need to provide careful probabilistic forecasting, which is vital in risk management for extreme events such as hurricanes and pandemics. However, it is challenging to automatically detect and learn to use extreme events and anomalies for large-scale datasets, which often require manual effort. Hence, we propose an anomaly-aware forecast framework that leverages the previously seen effects of anomalies to improve its prediction accuracy during and after the presence of extreme events. Specifically, the framework automatically extracts anomalies and incorporates them through an attention mechanism to increase its accuracy for future extreme events. Moreover, the framework employs a dynamic uncertainty optimization algorithm that reduces the uncertainty of forecasts in an online manner. The proposed framework demonstrated consistent superior accuracy with less uncertainty on three datasets with different varieties of anomalies over the current prediction models.
Protoformer: Embedding Prototypes for Transformers
Jun 25, 2022Transformers have been widely applied in text classification. Unfortunately, real-world data contain anomalies and noisy labels that cause challenges for state-of-art Transformers. This paper proposes Protoformer, a novel self-learning framework for Transformers that can leverage problematic samples for text classification. Protoformer features a selection mechanism for embedding samples that allows us to efficiently extract and utilize anomalies prototypes and difficult class prototypes. We demonstrated such capabilities on datasets with diverse textual structures (e.g., Twitter, IMDB, ArXiv). We also applied the framework to several models. The results indicate that Protoformer can improve current Transformers in various empirical settings.
* Advances in Knowledge Discovery and Data Mining (PAKDD 2022)
A Novel Deep Learning Model for Hotel Demand and Revenue Prediction amid COVID-19
Mar 08, 2022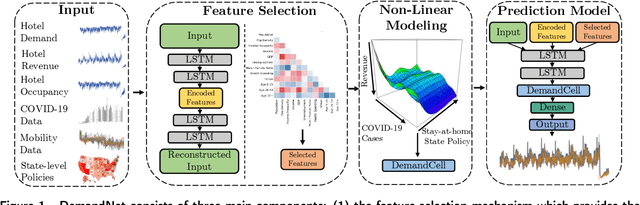
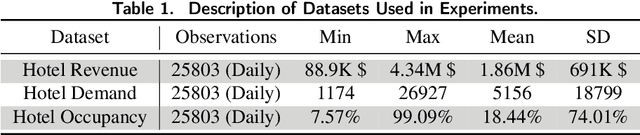
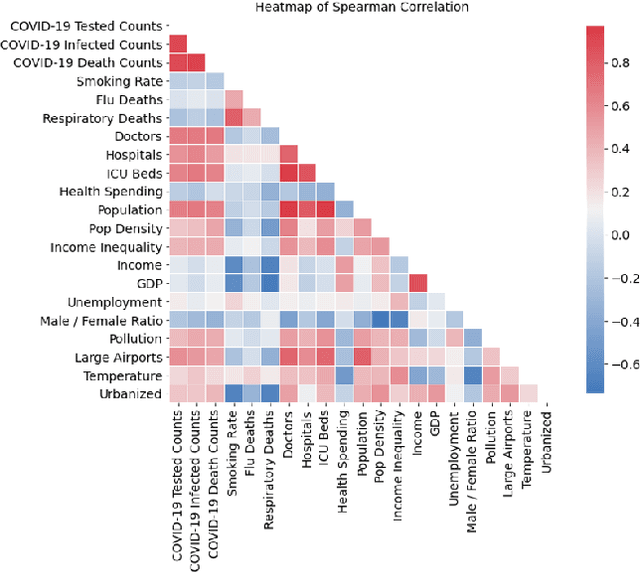
The COVID-19 pandemic has significantly impacted the tourism and hospitality sector. Public policies such as travel restrictions and stay-at-home orders had significantly affected tourist activities and service businesses' operations and profitability. To this end, it is essential to develop an interpretable forecast model that supports managerial and organizational decision-making. We developed DemandNet, a novel deep learning framework for predicting time series data under the influence of the COVID-19 pandemic. The framework starts by selecting the top static and dynamic features embedded in the time series data. Then, it includes a nonlinear model which can provide interpretable insight into the previously seen data. Lastly, a prediction model is developed to leverage the above characteristics to make robust long-term forecasts. We evaluated the framework using daily hotel demand and revenue data from eight cities in the US. Our findings reveal that DemandNet outperforms the state-of-art models and can accurately predict the impact of the COVID-19 pandemic on hotel demand and revenues.
* 55th Hawaii International Conference on System Sciences (HICSS) 2022
FWDA: a Fast Wishart Discriminant Analysis with its Application to Electronic Health Records Data Classification
Apr 25, 2017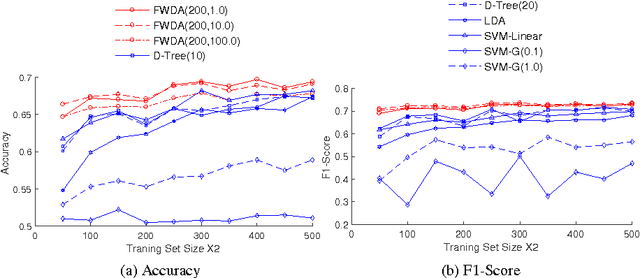
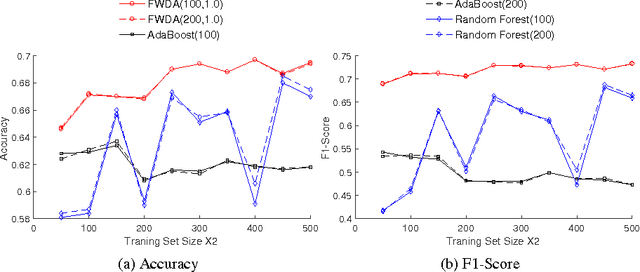

Linear Discriminant Analysis (LDA) on Electronic Health Records (EHR) data is widely-used for early detection of diseases. Classical LDA for EHR data classification, however, suffers from two handicaps: the ill-posed estimation of LDA parameters (e.g., covariance matrix), and the "linear inseparability" of EHR data. To handle these two issues, in this paper, we propose a novel classifier FWDA -- Fast Wishart Discriminant Analysis, that makes predictions in an ensemble way. Specifically, FWDA first surrogates the distribution of inverse covariance matrices using a Wishart distribution estimated from the training data, then "weighted-averages" the classification results of multiple LDA classifiers parameterized by the sampled inverse covariance matrices via a Bayesian Voting scheme. The weights for voting are optimally updated to adapt each new input data, so as to enable the nonlinear classification. Theoretical analysis indicates that FWDA possesses a fast convergence rate and a robust performance on high dimensional data. Extensive experiments on large-scale EHR dataset show that our approach outperforms state-of-the-art algorithms by a large margin.