 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantEval: A Benchmark for Financial Quantitative Tasks in Large Language Models
Jan 13, 2026Large Language Models (LLMs) have shown strong capabilities across many domains, yet their evaluation in financial quantitative tasks remains fragmented and mostly limited to knowledge-centric question answering. We introduce QuantEval, a benchmark that evaluates LLMs across three essential dimensions of quantitative finance: knowledge-based QA, quantitative mathematical reasoning, and quantitative strategy coding. Unlike prior financial benchmarks, QuantEval integrates a CTA-style backtesting framework that executes model-generated strategies and evaluates them using financial performance metrics, enabling a more realistic assessment of quantitative coding ability. We evaluate some state-of-the-art open-source and proprietary LLMs and observe substantial gaps to human experts, particularly in reasoning and strategy coding. Finally, we conduct large-scale supervised fine-tuning and reinforcement learning experiments on domain-aligned data, demonstrating consistent improvements. We hope QuantEval will facilitate research on LLMs' quantitative finance capabilities and accelerate their practical adoption in real-world trading workflows. We additionally release the full deterministic backtesting configuration (asset universe, cost model, and metric definitions) to ensure strict reproducibility.
The Multiplicative Noise in Stochastic Gradient Descent: Data-Dependent Regularization, Continuous and Discrete Approximation
Jun 18, 2019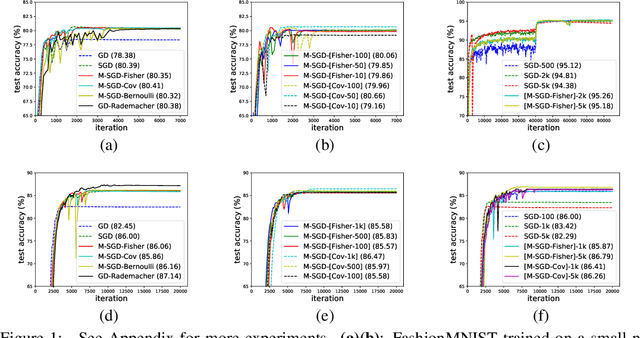
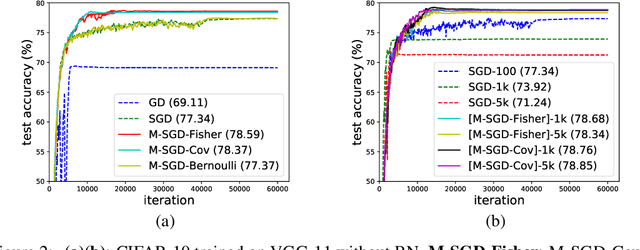

The randomness in Stochastic Gradient Descent (SGD) is considered to play a central role in the observed strong generalization capability of deep learning. In this work, we re-interpret the stochastic gradient of vanilla SGD as a matrix-vector product of the matrix of gradients and a random noise vector (namely multiplicative noise, M-Noise). Comparing to the existing theory that explains SGD using additive noise, the M-Noise helps establish a general case of SGD, namely Multiplicative SGD (M-SGD). The advantage of M-SGD is that it decouples noise from parameters, providing clear insights at the inherent randomness in SGD. Our analysis shows that 1) the M-SGD family, including the vanilla SGD, can be viewed as an minimizer with a data-dependent regularizer resemble of Rademacher complexity, which contributes to the implicit bias of M-SGD; 2) M-SGD holds a strong convergence to a continuous stochastic differential equation under the Gaussian noise assumption, ensuring the path-wise closeness of the discrete and continuous dynamics. For applications, based on M-SGD we design a fast algorithm to inject noise of different types (e.g., Gaussian and Bernoulli) into gradient descent. Based on the algorithm, we further demonstrate that M-SGD can approximate SGD with various noise types and recover the generalization performance, which reveals the potential of M-SGD to solve practical deep learning problems, e.g., large batch training with strong generalization performance. We have validated our observations on multiple practical deep learning scenarios.
Quasi-potential as an implicit regularizer for the loss function in the stochastic gradient descent
Jan 18, 2019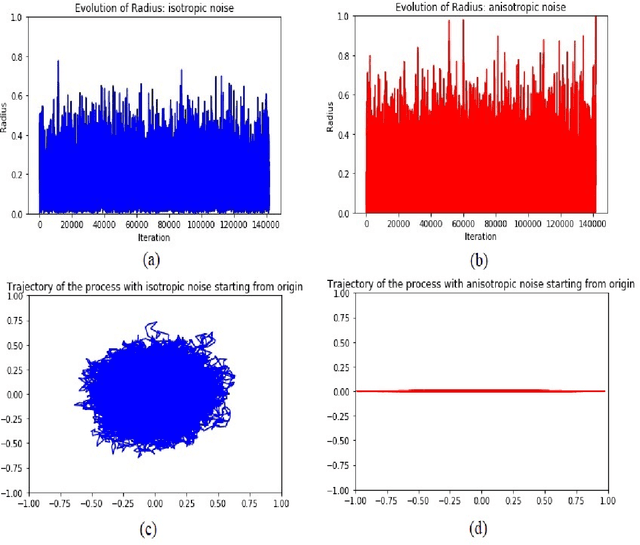
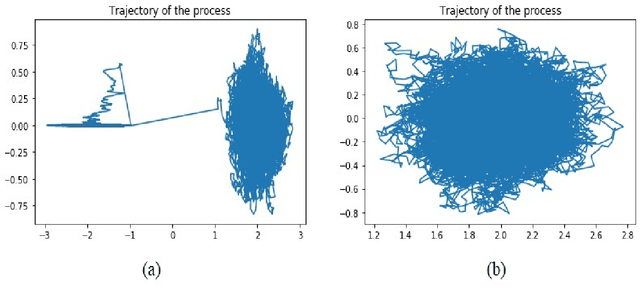
We interpret the variational inference of the Stochastic Gradient Descent (SGD) as minimizing a new potential function named the \textit{quasi-potential}. We analytically construct the quasi-potential function in the case when the loss function is convex and admits only one global minimum point. We show in this case that the quasi-potential function is related to the noise covariance structure of SGD via a partial differential equation of Hamilton-Jacobi type. This relation helps us to show that anisotropic noise leads to faster escape than isotropic noise. We then consider the dynamics of SGD in the case when the loss function is non-convex and admits several different local minima. In this case, we demonstrate an example that shows how the noise covariance structure plays a role in "implicit regularization", a phenomenon in which SGD favors some particular local minimum points. This is done through the relation between the noise covariance structure and the quasi-potential function. Our analysis is based on Large Deviations Theory (LDT), and they are validated by numerical experiments.
On the diffusion approximation of nonconvex stochastic gradient descent
Mar 03, 2018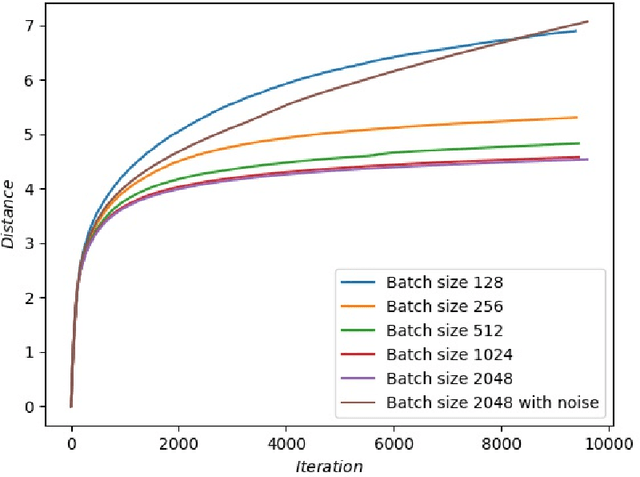
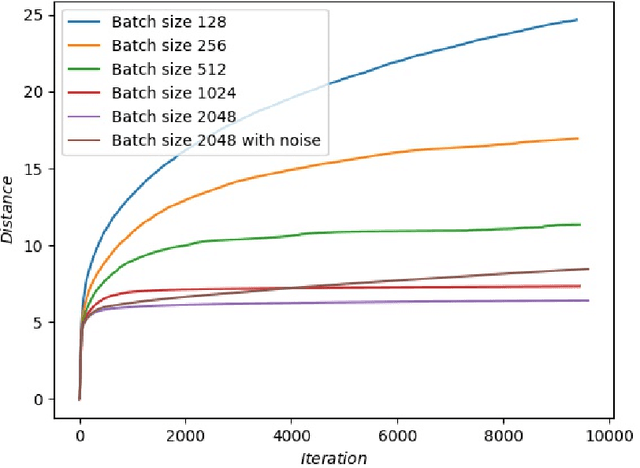
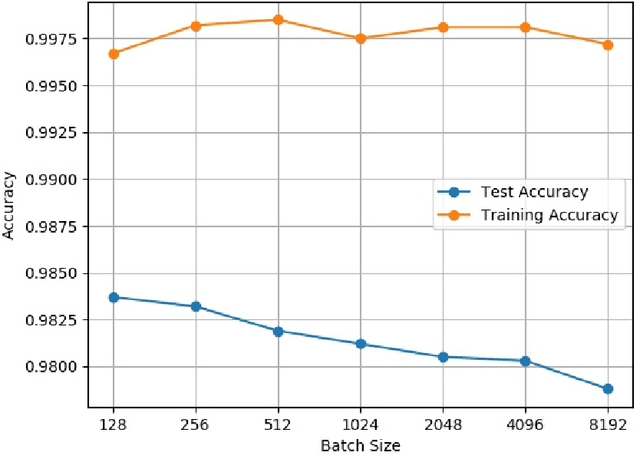

We study the Stochastic Gradient Descent (SGD) method in nonconvex optimization problems from the point of view of approximating diffusion processes. We prove rigorously that the diffusion process can approximate the SGD algorithm weakly using the weak form of master equation for probability evolution. In the small step size regime and the presence of omnidirectional noise, our weak approximating diffusion process suggests the following dynamics for the SGD iteration starting from a local minimizer (resp.~saddle point): it escapes in a number of iterations exponentially (resp.~almost linearly) dependent on the inverse stepsize. The results are obtained using the theory for random perturbations of dynamical systems (theory of large deviations for local minimizers and theory of exiting for unstable stationary points). In addition, we discuss the effects of batch size for the deep neural networks, and we find that small batch size is helpful for SGD algorithms to escape unstable stationary points and sharp minimizers. Our theory indicates that one should increase the batch size at later stage for the SGD to be trapped in flat minimizers for better generalization.
FWDA: a Fast Wishart Discriminant Analysis with its Application to Electronic Health Records Data Classification
Apr 25, 2017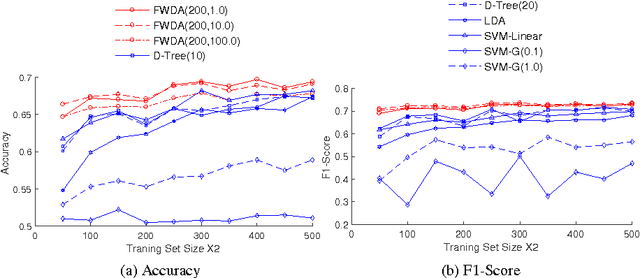
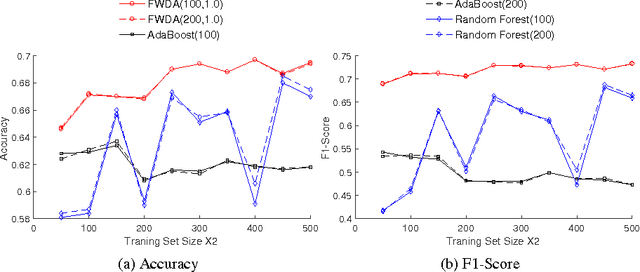

Linear Discriminant Analysis (LDA) on Electronic Health Records (EHR) data is widely-used for early detection of diseases. Classical LDA for EHR data classification, however, suffers from two handicaps: the ill-posed estimation of LDA parameters (e.g., covariance matrix), and the "linear inseparability" of EHR data. To handle these two issues, in this paper, we propose a novel classifier FWDA -- Fast Wishart Discriminant Analysis, that makes predictions in an ensemble way. Specifically, FWDA first surrogates the distribution of inverse covariance matrices using a Wishart distribution estimated from the training data, then "weighted-averages" the classification results of multiple LDA classifiers parameterized by the sampled inverse covariance matrices via a Bayesian Voting scheme. The weights for voting are optimally updated to adapt each new input data, so as to enable the nonlinear classification. Theoretical analysis indicates that FWDA possesses a fast convergence rate and a robust performance on high dimensional data. Extensive experiments on large-scale EHR dataset show that our approach outperforms state-of-the-art algorithms by a large margin.
Provably Good Early Detection of Diseases using Non-Sparse Covariance-Regularized Linear Discriminant Analysis
Oct 19, 2016
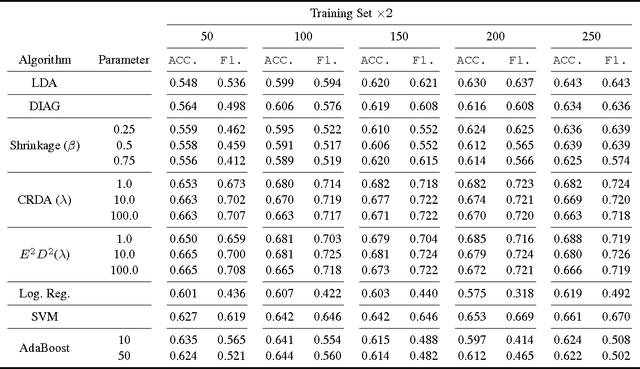


To improve the performance of Linear Discriminant Analysis (LDA) for early detection of diseases using Electronic Health Records (EHR) data, we propose \TheName{} -- a novel framework for \emph{\underline{E}HR based \underline{E}arly \underline{D}etection of \underline{D}iseases} on top of \emph{Covariance-Regularized} LDA models. Specifically, \TheName\ employs a \emph{non-sparse} inverse covariance matrix (or namely precision matrix) estimator derived from graphical lasso and incorporates the estimator into LDA classifiers to improve classification accuracy. Theoretical analysis on \TheName\ shows that it can bound the expected error rate of LDA classification, under certain assumptions. Finally, we conducted extensive experiments using a large-scale real-world EHR dataset -- CHSN. We compared our solution with other regularized LDA and downstream classifiers. The result shows \TheName\ outperforms all baselines and backups our theoretical analysis.