 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDominant-Layer ZO: A Single Layer Dominates Zeroth-Order Fine-Tuning of LLMs
Jun 03, 2026Zeroth-order (ZO) optimization enables memory-efficient fine-tuning of large language models (LLMs) using only forward passes, but it remains unclear how useful adaptation is distributed across layers. In this work, we reveal a surprising phenomenon: ZO fine-tuning is sharply dominated by a single decoding layer. Across multiple LLM families and downstream tasks, fine-tuning this dominant layer alone consistently matches or even exceeds full-model ZO fine-tuning. We further show that the dominant layer is task-agnostic but model-specific, and can be identified before training through a simple inference-only analysis of activation outliers. Specifically, the dominant layer consistently aligns with the first activation-outlier layer in the pre-trained model. To explain this phenomenon, we analyze how perturbation effects propagate under ZO optimization. We find that the dominant layer combines two key properties: high perturbation sensitivity and early placement in the residual stream, allowing perturbation-induced effects to propagate and accumulate through remaining subsequent decoding layers. As a result, this layer produces disproportionately strong and stable optimization signals under forward-only updates. Extensive experiments on LLaMA2-7B and Qwen3-8B across nine benchmarks show that dominant-layer ZO fine-tuning improves average performance over full-model MeZO and LoRA-based ZO fine-tuning while achieving up to 4.52$\times$ training speedup.
PROTEA: Securing Robot Task Planning and Execution
Jan 12, 2026Robots need task planning methods to generate action sequences for complex tasks. Recent work on adversarial attacks has revealed significant vulnerabilities in existing robot task planners, especially those built on foundation models. In this paper, we aim to address these security challenges by introducing PROTEA, an LLM-as-a-Judge defense mechanism, to evaluate the security of task plans. PROTEA is developed to address the dimensionality and history challenges in plan safety assessment. We used different LLMs to implement multiple versions of PROTEA for comparison purposes. For systemic evaluations, we created a dataset containing both benign and malicious task plans, where the harmful behaviors were injected at varying levels of stealthiness. Our results provide actionable insights for robotic system practitioners seeking to enhance robustness and security of their task planning systems. Details, dataset and demos are provided: https://protea-secure.github.io/PROTEA/
EIM-TRNG: Obfuscating Deep Neural Network Weights with Encoding-in-Memory True Random Number Generator via RowHammer
Jul 03, 2025True Random Number Generators (TRNGs) play a fundamental role in hardware security, cryptographic systems, and data protection. In the context of Deep NeuralNetworks (DNNs), safeguarding model parameters, particularly weights, is critical to ensure the integrity, privacy, and intel-lectual property of AI systems. While software-based pseudo-random number generators are widely used, they lack the unpredictability and resilience offered by hardware-based TRNGs. In this work, we propose a novel and robust Encoding-in-Memory TRNG called EIM-TRNG that leverages the inherent physical randomness in DRAM cell behavior, particularly under RowHammer-induced disturbances, for the first time. We demonstrate how the unpredictable bit-flips generated through carefully controlled RowHammer operations can be harnessed as a reliable entropy source. Furthermore, we apply this TRNG framework to secure DNN weight data by encoding via a combination of fixed and unpredictable bit-flips. The encrypted data is later decrypted using a key derived from the probabilistic flip behavior, ensuring both data confidentiality and model authenticity. Our results validate the effectiveness of DRAM-based entropy extraction for robust, low-cost hardware security and offer a promising direction for protecting machine learning models at the hardware level.
Unified Alignment Protocol: Making Sense of the Unlabeled Data in New Domains
May 27, 2025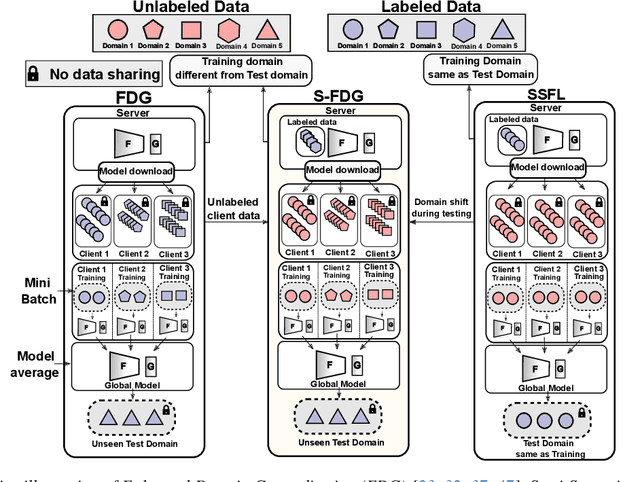

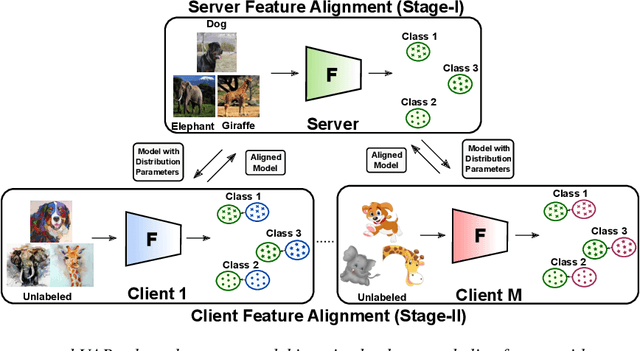
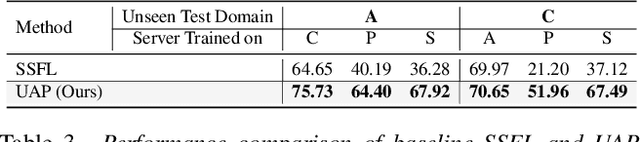
Semi-Supervised Federated Learning (SSFL) is gaining popularity over conventional Federated Learning in many real-world applications. Due to the practical limitation of limited labeled data on the client side, SSFL considers that participating clients train with unlabeled data, and only the central server has the necessary resources to access limited labeled data, making it an ideal fit for real-world applications (e.g., healthcare). However, traditional SSFL assumes that the data distributions in the training phase and testing phase are the same. In practice, however, domain shifts frequently occur, making it essential for SSFL to incorporate generalization capabilities and enhance their practicality. The core challenge is improving model generalization to new, unseen domains while the client participate in SSFL. However, the decentralized setup of SSFL and unsupervised client training necessitates innovation to achieve improved generalization across domains. To achieve this, we propose a novel framework called the Unified Alignment Protocol (UAP), which consists of an alternating two-stage training process. The first stage involves training the server model to learn and align the features with a parametric distribution, which is subsequently communicated to clients without additional communication overhead. The second stage proposes a novel training algorithm that utilizes the server feature distribution to align client features accordingly. Our extensive experiments on standard domain generalization benchmark datasets across multiple model architectures reveal that proposed UAP successfully achieves SOTA generalization performance in SSFL setting.
Robo-Troj: Attacking LLM-based Task Planners
Apr 23, 2025Robots need task planning methods to achieve goals that require more than individual actions. Recently, large language models (LLMs) have demonstrated impressive performance in task planning. LLMs can generate a step-by-step solution using a description of actions and the goal. Despite the successes in LLM-based task planning, there is limited research studying the security aspects of those systems. In this paper, we develop Robo-Troj, the first multi-trigger backdoor attack for LLM-based task planners, which is the main contribution of this work. As a multi-trigger attack, Robo-Troj is trained to accommodate the diversity of robot application domains. For instance, one can use unique trigger words, e.g., "herical", to activate a specific malicious behavior, e.g., cutting hand on a kitchen robot. In addition, we develop an optimization method for selecting the trigger words that are most effective. Through demonstrating the vulnerability of LLM-based planners, we aim to promote the development of secured robot systems.
Fisher Information guided Purification against Backdoor Attacks
Sep 01, 2024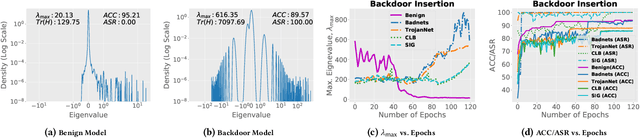
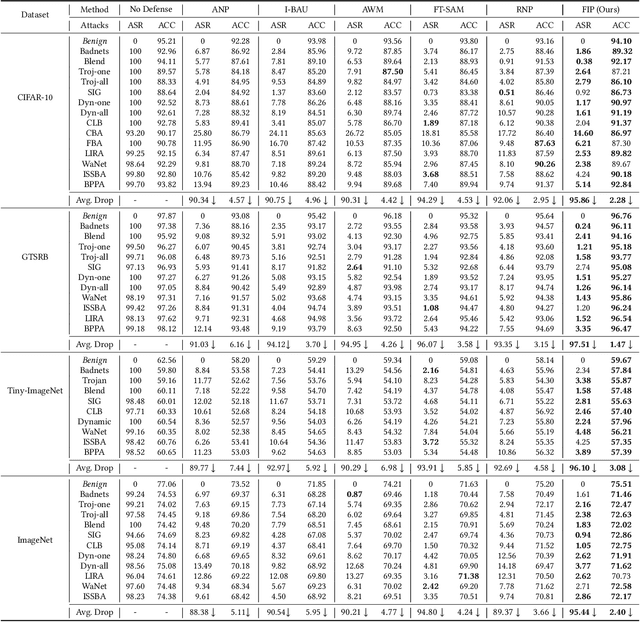
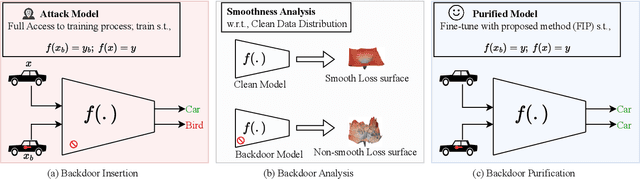

Studies on backdoor attacks in recent years suggest that an adversary can compromise the integrity of a deep neural network (DNN) by manipulating a small set of training samples. Our analysis shows that such manipulation can make the backdoor model converge to a bad local minima, i.e., sharper minima as compared to a benign model. Intuitively, the backdoor can be purified by re-optimizing the model to smoother minima. However, a na\"ive adoption of any optimization targeting smoother minima can lead to sub-optimal purification techniques hampering the clean test accuracy. Hence, to effectively obtain such re-optimization, inspired by our novel perspective establishing the connection between backdoor removal and loss smoothness, we propose Fisher Information guided Purification (FIP), a novel backdoor purification framework. Proposed FIP consists of a couple of novel regularizers that aid the model in suppressing the backdoor effects and retaining the acquired knowledge of clean data distribution throughout the backdoor removal procedure through exploiting the knowledge of Fisher Information Matrix (FIM). In addition, we introduce an efficient variant of FIP, dubbed as Fast FIP, which reduces the number of tunable parameters significantly and obtains an impressive runtime gain of almost $5\times$. Extensive experiments show that the proposed method achieves state-of-the-art (SOTA) performance on a wide range of backdoor defense benchmarks: 5 different tasks -- Image Recognition, Object Detection, Video Action Recognition, 3D point Cloud, Language Generation; 11 different datasets including ImageNet, PASCAL VOC, UCF101; diverse model architectures spanning both CNN and vision transformer; 14 different backdoor attacks, e.g., Dynamic, WaNet, LIRA, ISSBA, etc.
DNN-Defender: An in-DRAM Deep Neural Network Defense Mechanism for Adversarial Weight Attack
May 14, 2023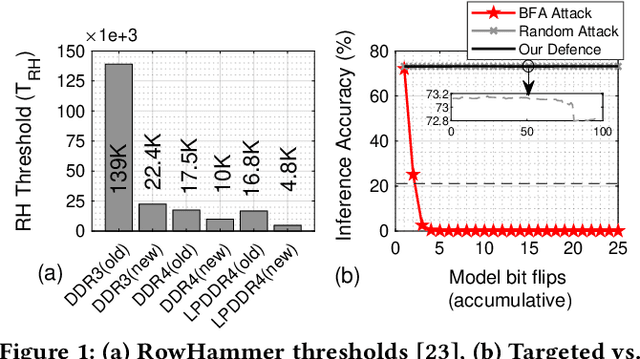



With deep learning deployed in many security-sensitive areas, machine learning security is becoming progressively important. Recent studies demonstrate attackers can exploit system-level techniques exploiting the RowHammer vulnerability of DRAM to deterministically and precisely flip bits in Deep Neural Networks (DNN) model weights to affect inference accuracy. The existing defense mechanisms are software-based, such as weight reconstruction requiring expensive training overhead or performance degradation. On the other hand, generic hardware-based victim-/aggressor-focused mechanisms impose expensive hardware overheads and preserve the spatial connection between victim and aggressor rows. In this paper, we present the first DRAM-based victim-focused defense mechanism tailored for quantized DNNs, named DNN-Defender that leverages the potential of in-DRAM swapping to withstand the targeted bit-flip attacks. Our results indicate that DNN-Defender can deliver a high level of protection downgrading the performance of targeted RowHammer attacks to a random attack level. In addition, the proposed defense has no accuracy drop on CIFAR-10 and ImageNet datasets without requiring any software training or incurring additional hardware overhead.
Model Extraction Attacks on Split Federated Learning
Mar 13, 2023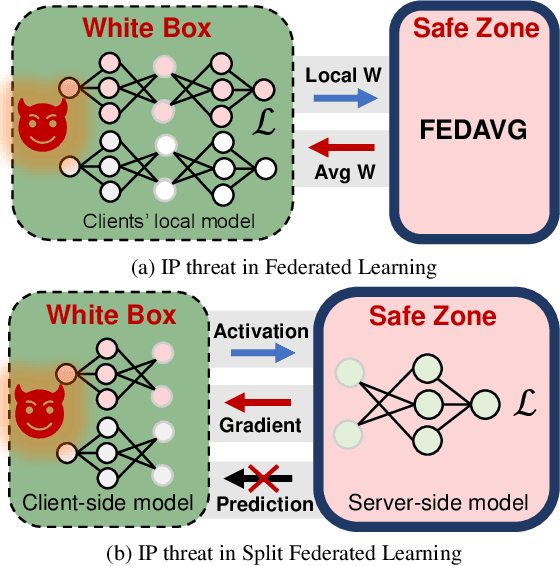

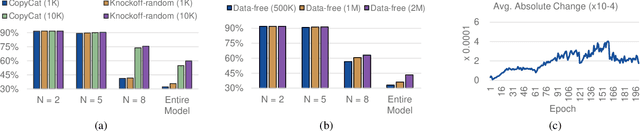

Federated Learning (FL) is a popular collaborative learning scheme involving multiple clients and a server. FL focuses on protecting clients' data but turns out to be highly vulnerable to Intellectual Property (IP) threats. Since FL periodically collects and distributes the model parameters, a free-rider can download the latest model and thus steal model IP. Split Federated Learning (SFL), a recent variant of FL that supports training with resource-constrained clients, splits the model into two, giving one part of the model to clients (client-side model), and the remaining part to the server (server-side model). Thus SFL prevents model leakage by design. Moreover, by blocking prediction queries, it can be made resistant to advanced IP threats such as traditional Model Extraction (ME) attacks. While SFL is better than FL in terms of providing IP protection, it is still vulnerable. In this paper, we expose the vulnerability of SFL and show how malicious clients can launch ME attacks by querying the gradient information from the server side. We propose five variants of ME attack which differs in the gradient usage as well as in the data assumptions. We show that under practical cases, the proposed ME attacks work exceptionally well for SFL. For instance, when the server-side model has five layers, our proposed ME attack can achieve over 90% accuracy with less than 2% accuracy degradation with VGG-11 on CIFAR-10.
ResSFL: A Resistance Transfer Framework for Defending Model Inversion Attack in Split Federated Learning
May 09, 2022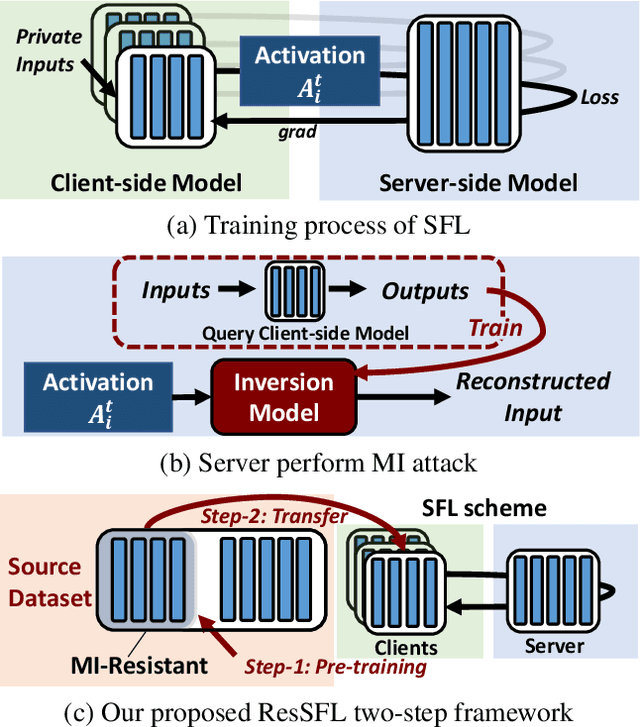
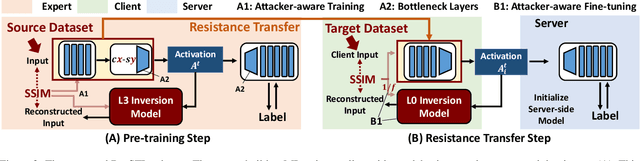
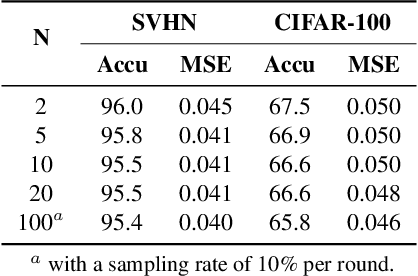
This work aims to tackle Model Inversion (MI) attack on Split Federated Learning (SFL). SFL is a recent distributed training scheme where multiple clients send intermediate activations (i.e., feature map), instead of raw data, to a central server. While such a scheme helps reduce the computational load at the client end, it opens itself to reconstruction of raw data from intermediate activation by the server. Existing works on protecting SFL only consider inference and do not handle attacks during training. So we propose ResSFL, a Split Federated Learning Framework that is designed to be MI-resistant during training. It is based on deriving a resistant feature extractor via attacker-aware training, and using this extractor to initialize the client-side model prior to standard SFL training. Such a method helps in reducing the computational complexity due to use of strong inversion model in client-side adversarial training as well as vulnerability of attacks launched in early training epochs. On CIFAR-100 dataset, our proposed framework successfully mitigates MI attack on a VGG-11 model with a high reconstruction Mean-Square-Error of 0.050 compared to 0.005 obtained by the baseline system. The framework achieves 67.5% accuracy (only 1% accuracy drop) with very low computation overhead. Code is released at: https://github.com/zlijingtao/ResSFL.
DeepSteal: Advanced Model Extractions Leveraging Efficient Weight Stealing in Memories
Nov 08, 2021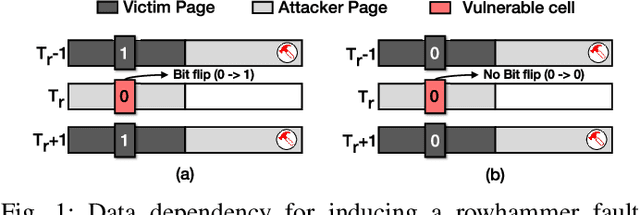
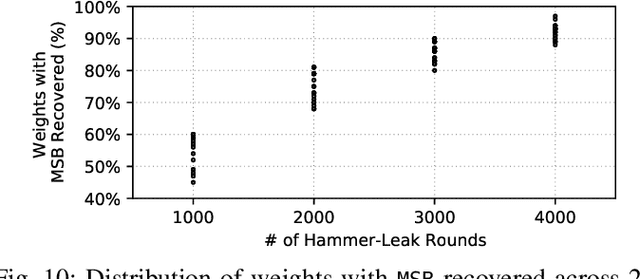
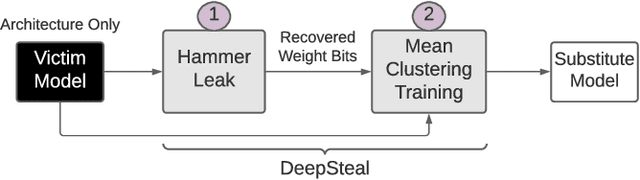
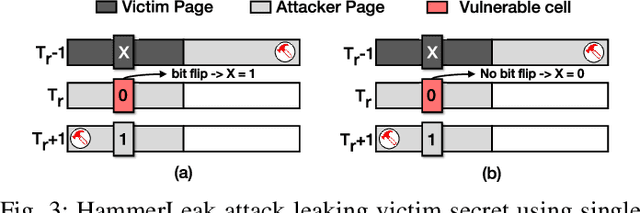
Recent advancements of Deep Neural Networks (DNNs) have seen widespread deployment in multiple security-sensitive domains. The need of resource-intensive training and use of valuable domain-specific training data have made these models a top intellectual property (IP) for model owners. One of the major threats to the DNN privacy is model extraction attacks where adversaries attempt to steal sensitive information in DNN models. Recent studies show hardware-based side channel attacks can reveal internal knowledge about DNN models (e.g., model architectures) However, to date, existing attacks cannot extract detailed model parameters (e.g., weights/biases). In this work, for the first time, we propose an advanced model extraction attack framework DeepSteal that effectively steals DNN weights with the aid of memory side-channel attack. Our proposed DeepSteal comprises two key stages. Firstly, we develop a new weight bit information extraction method, called HammerLeak, through adopting the rowhammer based hardware fault technique as the information leakage vector. HammerLeak leverages several novel system-level techniques tailed for DNN applications to enable fast and efficient weight stealing. Secondly, we propose a novel substitute model training algorithm with Mean Clustering weight penalty, which leverages the partial leaked bit information effectively and generates a substitute prototype of the target victim model. We evaluate this substitute model extraction method on three popular image datasets (e.g., CIFAR-10/100/GTSRB) and four DNN architectures (e.g., ResNet-18/34/Wide-ResNet/VGG-11). The extracted substitute model has successfully achieved more than 90 % test accuracy on deep residual networks for the CIFAR-10 dataset. Moreover, our extracted substitute model could also generate effective adversarial input samples to fool the victim model.