 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROTEA: Securing Robot Task Planning and Execution
Jan 12, 2026Robots need task planning methods to generate action sequences for complex tasks. Recent work on adversarial attacks has revealed significant vulnerabilities in existing robot task planners, especially those built on foundation models. In this paper, we aim to address these security challenges by introducing PROTEA, an LLM-as-a-Judge defense mechanism, to evaluate the security of task plans. PROTEA is developed to address the dimensionality and history challenges in plan safety assessment. We used different LLMs to implement multiple versions of PROTEA for comparison purposes. For systemic evaluations, we created a dataset containing both benign and malicious task plans, where the harmful behaviors were injected at varying levels of stealthiness. Our results provide actionable insights for robotic system practitioners seeking to enhance robustness and security of their task planning systems. Details, dataset and demos are provided: https://protea-secure.github.io/PROTEA/
Unified Alignment Protocol: Making Sense of the Unlabeled Data in New Domains
May 27, 2025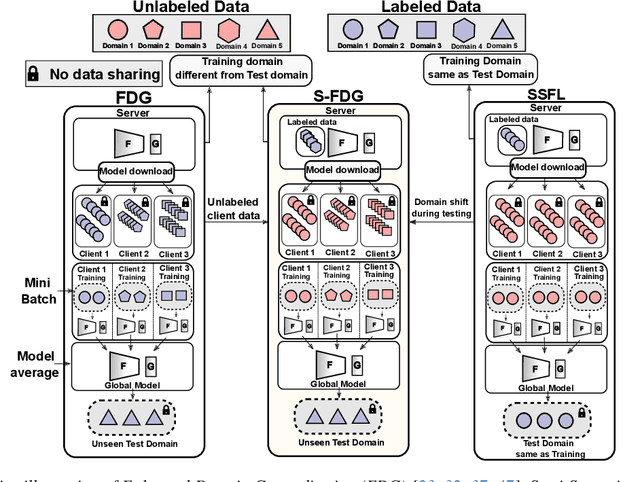

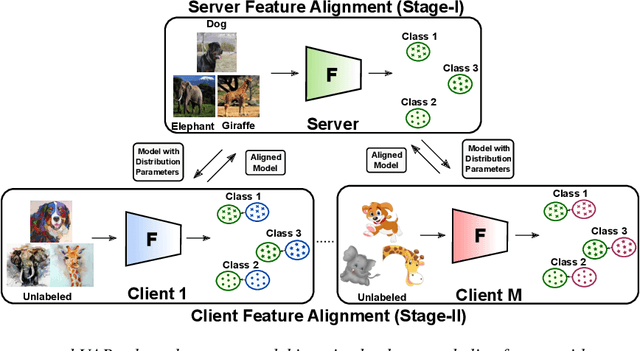
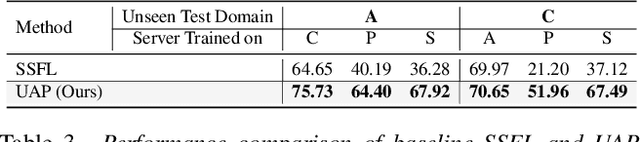
Semi-Supervised Federated Learning (SSFL) is gaining popularity over conventional Federated Learning in many real-world applications. Due to the practical limitation of limited labeled data on the client side, SSFL considers that participating clients train with unlabeled data, and only the central server has the necessary resources to access limited labeled data, making it an ideal fit for real-world applications (e.g., healthcare). However, traditional SSFL assumes that the data distributions in the training phase and testing phase are the same. In practice, however, domain shifts frequently occur, making it essential for SSFL to incorporate generalization capabilities and enhance their practicality. The core challenge is improving model generalization to new, unseen domains while the client participate in SSFL. However, the decentralized setup of SSFL and unsupervised client training necessitates innovation to achieve improved generalization across domains. To achieve this, we propose a novel framework called the Unified Alignment Protocol (UAP), which consists of an alternating two-stage training process. The first stage involves training the server model to learn and align the features with a parametric distribution, which is subsequently communicated to clients without additional communication overhead. The second stage proposes a novel training algorithm that utilizes the server feature distribution to align client features accordingly. Our extensive experiments on standard domain generalization benchmark datasets across multiple model architectures reveal that proposed UAP successfully achieves SOTA generalization performance in SSFL setting.
Robo-Troj: Attacking LLM-based Task Planners
Apr 23, 2025Robots need task planning methods to achieve goals that require more than individual actions. Recently, large language models (LLMs) have demonstrated impressive performance in task planning. LLMs can generate a step-by-step solution using a description of actions and the goal. Despite the successes in LLM-based task planning, there is limited research studying the security aspects of those systems. In this paper, we develop Robo-Troj, the first multi-trigger backdoor attack for LLM-based task planners, which is the main contribution of this work. As a multi-trigger attack, Robo-Troj is trained to accommodate the diversity of robot application domains. For instance, one can use unique trigger words, e.g., "herical", to activate a specific malicious behavior, e.g., cutting hand on a kitchen robot. In addition, we develop an optimization method for selecting the trigger words that are most effective. Through demonstrating the vulnerability of LLM-based planners, we aim to promote the development of secured robot systems.
CNN-Based Prediction of Frame-Level Shot Importance for Video Summarization
Aug 23, 2017
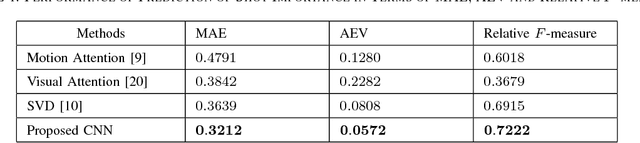
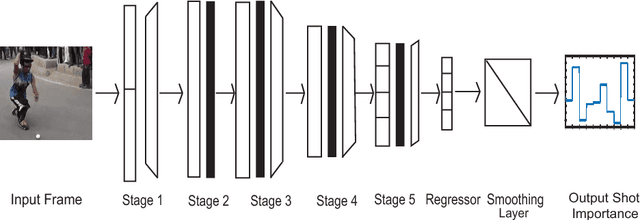
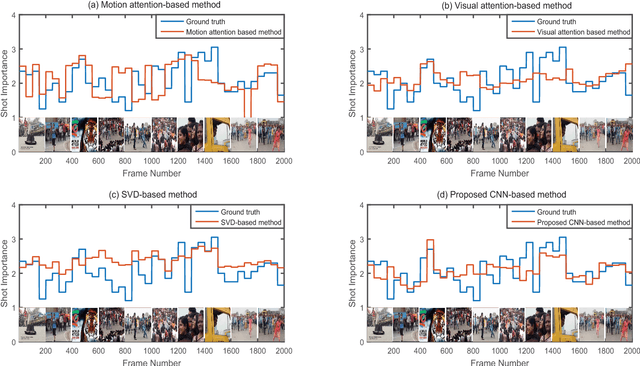
In the Internet, ubiquitous presence of redundant, unedited, raw videos has made video summarization an important problem. Traditional methods of video summarization employ a heuristic set of hand-crafted features, which in many cases fail to capture subtle abstraction of a scene. This paper presents a deep learning method that maps the context of a video to the importance of a scene similar to that is perceived by humans. In particular, a convolutional neural network (CNN)-based architecture is proposed to mimic the frame-level shot importance for user-oriented video summarization. The weights and biases of the CNN are trained extensively through off-line processing, so that it can provide the importance of a frame of an unseen video almost instantaneously. Experiments on estimating the shot importance is carried out using the publicly available database TVSum50. It is shown that the performance of the proposed network is substantially better than that of commonly referred feature-based methods for estimating the shot importance in terms of mean absolute error, absolute error variance, and relative F-measure.