 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Learning Approach for Hand Gesture Recognition and Fingertip Detection
Jan 06, 2021
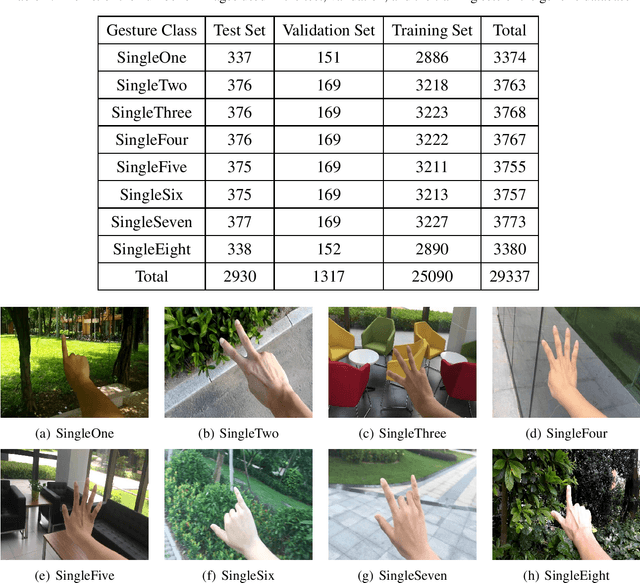
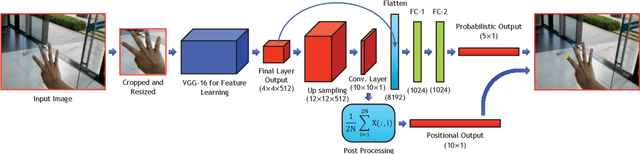
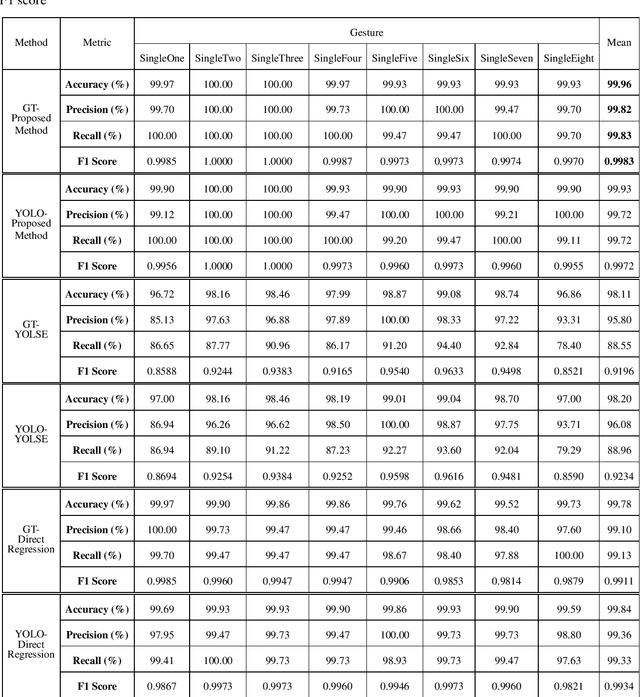
In human-computer interaction or sign language interpretation, recognizing hand gestures and detecting fingertips become ubiquitous in computer vision research. In this paper, a unified approach of convolutional neural network for both hand gesture recognition and fingertip detection is introduced. The proposed algorithm uses a single network to predict the probabilities of finger class and positions of fingertips in one forward propagation of the network. Instead of directly regressing the positions of fingertips from the fully connected layer, the ensemble of the position of fingertips is regressed from the fully convolutional network. Subsequently, the ensemble average is taken to regress the final position of fingertips. Since the whole pipeline uses a single network, it is significantly fast in computation. The proposed method results in remarkably less pixel error as compared to that in the direct regression approach and it outperforms the existing fingertip detection approaches including the Heatmap-based framework.
CNN-Based Prediction of Frame-Level Shot Importance for Video Summarization
Aug 23, 2017
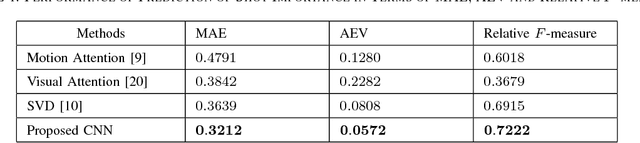
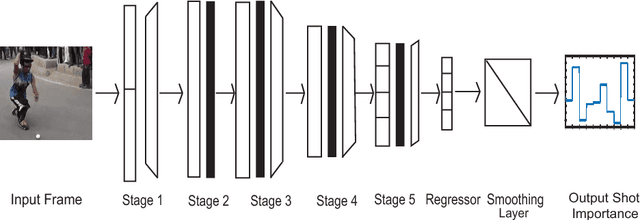
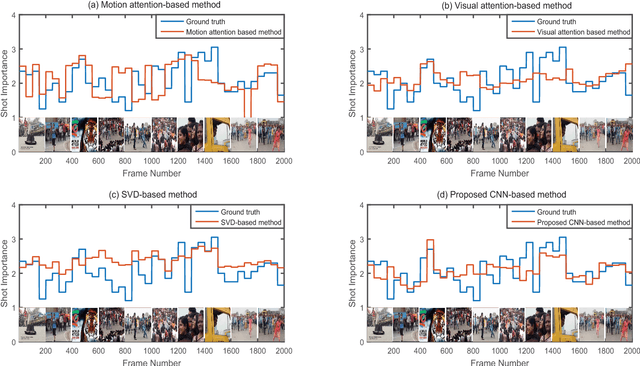
In the Internet, ubiquitous presence of redundant, unedited, raw videos has made video summarization an important problem. Traditional methods of video summarization employ a heuristic set of hand-crafted features, which in many cases fail to capture subtle abstraction of a scene. This paper presents a deep learning method that maps the context of a video to the importance of a scene similar to that is perceived by humans. In particular, a convolutional neural network (CNN)-based architecture is proposed to mimic the frame-level shot importance for user-oriented video summarization. The weights and biases of the CNN are trained extensively through off-line processing, so that it can provide the importance of a frame of an unseen video almost instantaneously. Experiments on estimating the shot importance is carried out using the publicly available database TVSum50. It is shown that the performance of the proposed network is substantially better than that of commonly referred feature-based methods for estimating the shot importance in terms of mean absolute error, absolute error variance, and relative F-measure.
Statistical Selection of CNN-Based Audiovisual Features for Instantaneous Estimation of Human Emotional States
Aug 23, 2017
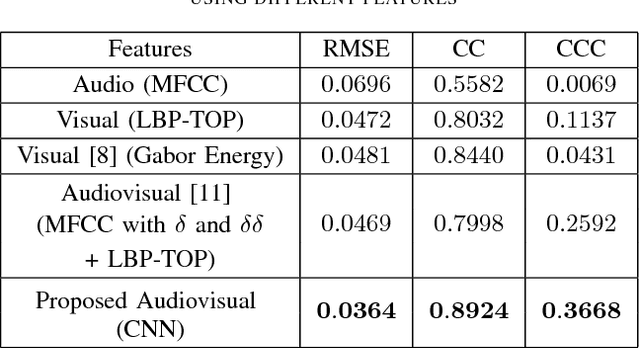
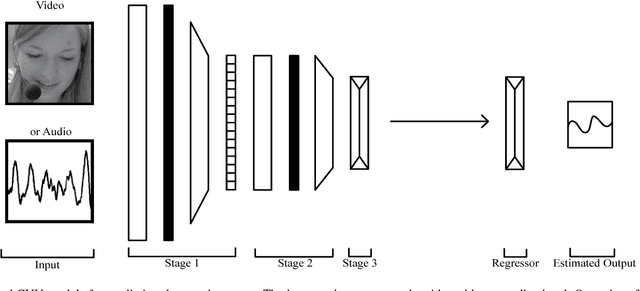
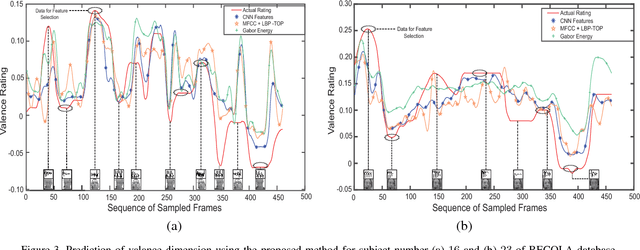
Automatic prediction of continuous-level emotional state requires selection of suitable affective features to develop a regression system based on supervised machine learning. This paper investigates the performance of features statistically learned using convolutional neural networks for instantaneously predicting the continuous dimensions of emotional states. Features with minimum redundancy and maximum relevancy are chosen by using the mutual information-based selection process. The performance of frame-by-frame prediction of emotional state using the moderate length features as proposed in this paper is evaluated on spontaneous and naturalistic human-human conversation of RECOLA database. Experimental results show that the proposed model can be used for instantaneous prediction of emotional state with an accuracy higher than traditional audio or video features that are used for affective computation.