 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Walsh Hadamard Derived Linear Vector Symbolic Architecture
Oct 30, 2024
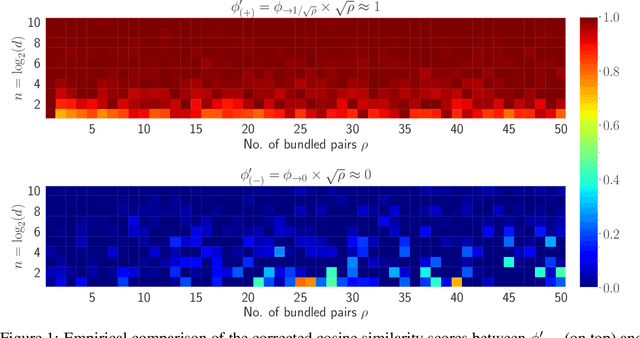


Vector Symbolic Architectures (VSAs) are one approach to developing Neuro-symbolic AI, where two vectors in $\mathbb{R}^d$ are `bound' together to produce a new vector in the same space. VSAs support the commutativity and associativity of this binding operation, along with an inverse operation, allowing one to construct symbolic-style manipulations over real-valued vectors. Most VSAs were developed before deep learning and automatic differentiation became popular and instead focused on efficacy in hand-designed systems. In this work, we introduce the Hadamard-derived linear Binding (HLB), which is designed to have favorable computational efficiency, and efficacy in classic VSA tasks, and perform well in differentiable systems. Code is available at https://github.com/FutureComputing4AI/Hadamard-derived-Linear-Binding
Automated Virtual Product Placement and Assessment in Images using Diffusion Models
May 02, 2024In Virtual Product Placement (VPP) applications, the discrete integration of specific brand products into images or videos has emerged as a challenging yet important task. This paper introduces a novel three-stage fully automated VPP system. In the first stage, a language-guided image segmentation model identifies optimal regions within images for product inpainting. In the second stage, Stable Diffusion (SD), fine-tuned with a few example product images, is used to inpaint the product into the previously identified candidate regions. The final stage introduces an "Alignment Module", which is designed to effectively sieve out low-quality images. Comprehensive experiments demonstrate that the Alignment Module ensures the presence of the intended product in every generated image and enhances the average quality of images by 35%. The results presented in this paper demonstrate the effectiveness of the proposed VPP system, which holds significant potential for transforming the landscape of virtual advertising and marketing strategies.
Holographic Global Convolutional Networks for Long-Range Prediction Tasks in Malware Detection
Mar 23, 2024



Malware detection is an interesting and valuable domain to work in because it has significant real-world impact and unique machine-learning challenges. We investigate existing long-range techniques and benchmarks and find that they're not very suitable in this problem area. In this paper, we introduce Holographic Global Convolutional Networks (HGConv) that utilize the properties of Holographic Reduced Representations (HRR) to encode and decode features from sequence elements. Unlike other global convolutional methods, our method does not require any intricate kernel computation or crafted kernel design. HGConv kernels are defined as simple parameters learned through backpropagation. The proposed method has achieved new SOTA results on Microsoft Malware Classification Challenge, Drebin, and EMBER malware benchmarks. With log-linear complexity in sequence length, the empirical results demonstrate substantially faster run-time by HGConv compared to other methods achieving far more efficient scaling even with sequence length $\geq 100,000$.
Towards Generalization in Subitizing with Neuro-Symbolic Loss using Holographic Reduced Representations
Dec 23, 2023



While deep learning has enjoyed significant success in computer vision tasks over the past decade, many shortcomings still exist from a Cognitive Science (CogSci) perspective. In particular, the ability to subitize, i.e., quickly and accurately identify the small (less than 6) count of items, is not well learned by current Convolutional Neural Networks (CNNs) or Vision Transformers (ViTs) when using a standard cross-entropy (CE) loss. In this paper, we demonstrate that adapting tools used in CogSci research can improve the subitizing generalization of CNNs and ViTs by developing an alternative loss function using Holographic Reduced Representations (HRRs). We investigate how this neuro-symbolic approach to learning affects the subitizing capability of CNNs and ViTs, and so we focus on specially crafted problems that isolate generalization to specific aspects of subitizing. Via saliency maps and out-of-distribution performance, we are able to empirically observe that the proposed HRR loss improves subitizing generalization though it does not completely solve the problem. In addition, we find that ViTs perform considerably worse compared to CNNs in most respects on subitizing, except on one axis where an HRR-based loss provides improvement.
DDxT: Deep Generative Transformer Models for Differential Diagnosis
Dec 02, 2023



Differential Diagnosis (DDx) is the process of identifying the most likely medical condition among the possible pathologies through the process of elimination based on evidence. An automated process that narrows a large set of pathologies down to the most likely pathologies will be of great importance. The primary prior works have relied on the Reinforcement Learning (RL) paradigm under the intuition that it aligns better with how physicians perform DDx. In this paper, we show that a generative approach trained with simpler supervised and self-supervised learning signals can achieve superior results on the current benchmark. The proposed Transformer-based generative network, named DDxT, autoregressively produces a set of possible pathologies, i.e., DDx, and predicts the actual pathology using a neural network. Experiments are performed using the DDXPlus dataset. In the case of DDx, the proposed network has achieved a mean accuracy of 99.82% and a mean F1 score of 0.9472. Additionally, mean accuracy reaches 99.98% with a mean F1 score of 0.9949 while predicting ground truth pathology. The proposed DDxT outperformed the previous RL-based approaches by a big margin. Overall, the automated Transformer-based DDx generative model has the potential to become a useful tool for a physician in times of urgency.
Recasting Self-Attention with Holographic Reduced Representations
May 31, 2023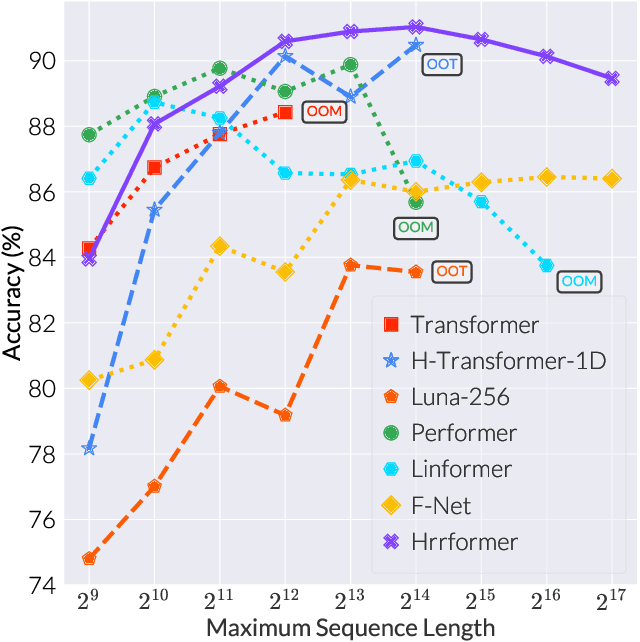
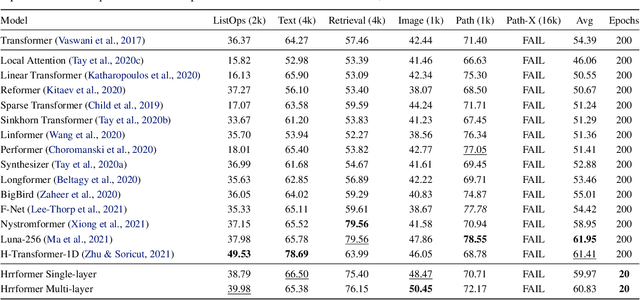
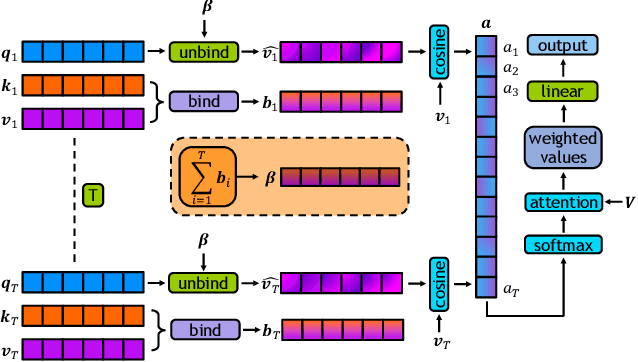
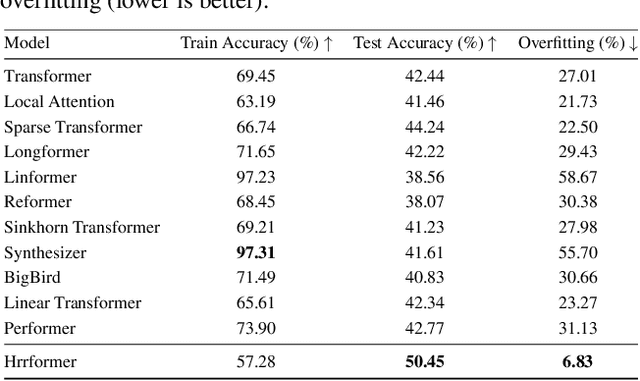
In recent years, self-attention has become the dominant paradigm for sequence modeling in a variety of domains. However, in domains with very long sequence lengths the $\mathcal{O}(T^2)$ memory and $\mathcal{O}(T^2 H)$ compute costs can make using transformers infeasible. Motivated by problems in malware detection, where sequence lengths of $T \geq 100,000$ are a roadblock to deep learning, we re-cast self-attention using the neuro-symbolic approach of Holographic Reduced Representations (HRR). In doing so we perform the same high-level strategy of the standard self-attention: a set of queries matching against a set of keys, and returning a weighted response of the values for each key. Implemented as a ``Hrrformer'' we obtain several benefits including $\mathcal{O}(T H \log H)$ time complexity, $\mathcal{O}(T H)$ space complexity, and convergence in $10\times$ fewer epochs. Nevertheless, the Hrrformer achieves near state-of-the-art accuracy on LRA benchmarks and we are able to learn with just a single layer. Combined, these benefits make our Hrrformer the first viable Transformer for such long malware classification sequences and up to $280\times$ faster to train on the Long Range Arena benchmark. Code is available at \url{https://github.com/NeuromorphicComputationResearchProgram/Hrrformer}
Lempel-Ziv Networks
Nov 23, 2022Sequence processing has long been a central area of machine learning research. Recurrent neural nets have been successful in processing sequences for a number of tasks; however, they are known to be both ineffective and computationally expensive when applied to very long sequences. Compression-based methods have demonstrated more robustness when processing such sequences -- in particular, an approach pairing the Lempel-Ziv Jaccard Distance (LZJD) with the k-Nearest Neighbor algorithm has shown promise on long sequence problems (up to $T=200,000,000$ steps) involving malware classification. Unfortunately, use of LZJD is limited to discrete domains. To extend the benefits of LZJD to a continuous domain, we investigate the effectiveness of a deep-learning analog of the algorithm, the Lempel-Ziv Network. While we achieve successful proof of concept, we are unable to improve meaningfully on the performance of a standard LSTM across a variety of datasets and sequence processing tasks. In addition to presenting this negative result, our work highlights the problem of sub-par baseline tuning in newer research areas.
Deploying Convolutional Networks on Untrusted Platforms Using 2D Holographic Reduced Representations
Jun 13, 2022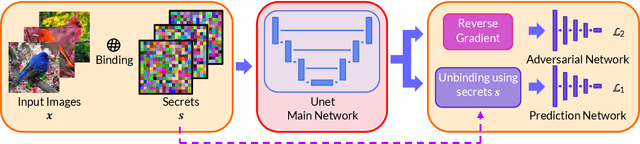
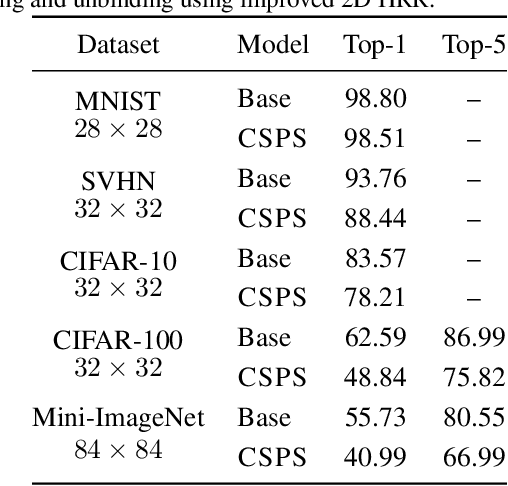
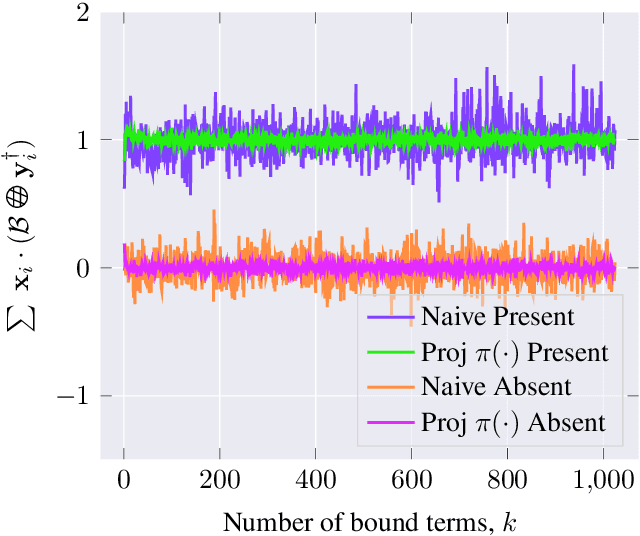

Due to the computational cost of running inference for a neural network, the need to deploy the inferential steps on a third party's compute environment or hardware is common. If the third party is not fully trusted, it is desirable to obfuscate the nature of the inputs and outputs, so that the third party can not easily determine what specific task is being performed. Provably secure protocols for leveraging an untrusted party exist but are too computational demanding to run in practice. We instead explore a different strategy of fast, heuristic security that we call Connectionist Symbolic Pseudo Secrets. By leveraging Holographic Reduced Representations (HRR), we create a neural network with a pseudo-encryption style defense that empirically shows robustness to attack, even under threat models that unrealistically favor the adversary.
A Unified Learning Approach for Hand Gesture Recognition and Fingertip Detection
Jan 06, 2021
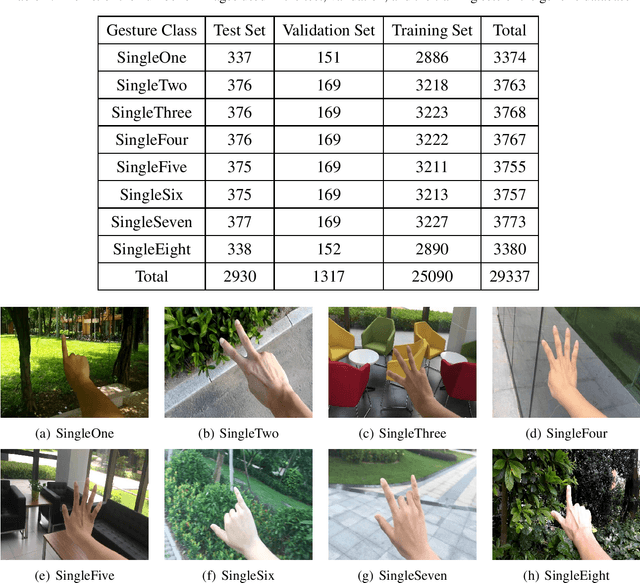
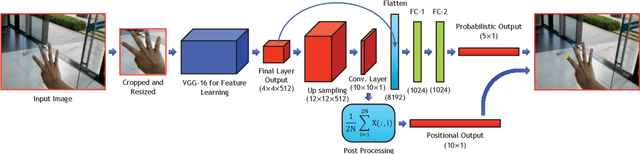
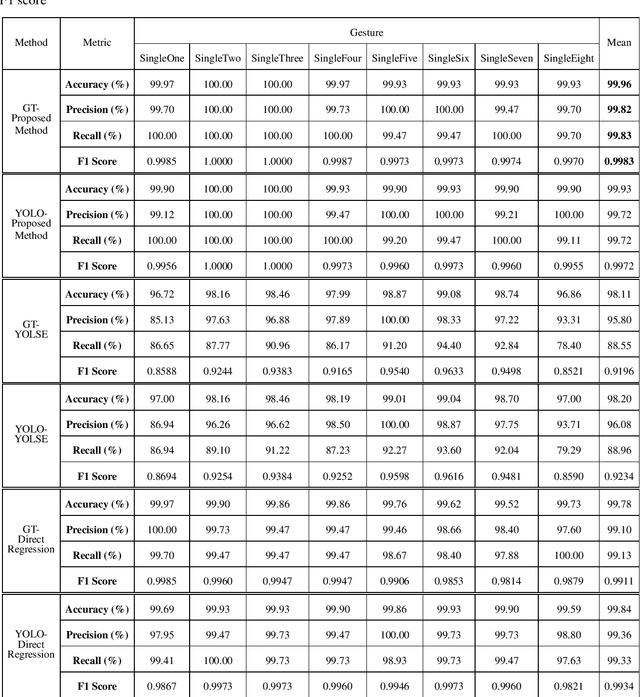
In human-computer interaction or sign language interpretation, recognizing hand gestures and detecting fingertips become ubiquitous in computer vision research. In this paper, a unified approach of convolutional neural network for both hand gesture recognition and fingertip detection is introduced. The proposed algorithm uses a single network to predict the probabilities of finger class and positions of fingertips in one forward propagation of the network. Instead of directly regressing the positions of fingertips from the fully connected layer, the ensemble of the position of fingertips is regressed from the fully convolutional network. Subsequently, the ensemble average is taken to regress the final position of fingertips. Since the whole pipeline uses a single network, it is significantly fast in computation. The proposed method results in remarkably less pixel error as compared to that in the direct regression approach and it outperforms the existing fingertip detection approaches including the Heatmap-based framework.