 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipf-Gramming: Scaling Byte N-Grams Up to Production Sized Malware Corpora
Nov 17, 2025A classifier using byte n-grams as features is the only approach we have found fast enough to meet requirements in size (sub 2 MB), speed (multiple GB/s), and latency (sub 10 ms) for deployment in numerous malware detection scenarios. However, we've consistently found that 6-8 grams achieve the best accuracy on our production deployments but have been unable to deploy regularly updated models due to the high cost of finding the top-k most frequent n-grams over terabytes of executable programs. Because the Zipfian distribution well models the distribution of n-grams, we exploit its properties to develop a new top-k n-gram extractor that is up to $35\times$ faster than the previous best alternative. Using our new Zipf-Gramming algorithm, we are able to scale up our production training set and obtain up to 30\% improvement in AUC at detecting new malware. We show theoretically and empirically that our approach will select the top-k items with little error and the interplay between theory and engineering required to achieve these results.
* Published in CIKM 2025
EMBER2024 -- A Benchmark Dataset for Holistic Evaluation of Malware Classifiers
Jun 05, 2025



A lack of accessible data has historically restricted malware analysis research, and practitioners have relied heavily on datasets provided by industry sources to advance. Existing public datasets are limited by narrow scope - most include files targeting a single platform, have labels supporting just one type of malware classification task, and make no effort to capture the evasive files that make malware detection difficult in practice. We present EMBER2024, a new dataset that enables holistic evaluation of malware classifiers. Created in collaboration with the authors of EMBER2017 and EMBER2018, the EMBER2024 dataset includes hashes, metadata, feature vectors, and labels for more than 3.2 million files from six file formats. Our dataset supports the training and evaluation of machine learning models on seven malware classification tasks, including malware detection, malware family classification, and malware behavior identification. EMBER2024 is the first to include a collection of malicious files that initially went undetected by a set of antivirus products, creating a "challenge" set to assess classifier performance against evasive malware. This work also introduces EMBER feature version 3, with added support for several new feature types. We are releasing the EMBER2024 dataset to promote reproducibility and empower researchers in the pursuit of new malware research topics.
Quick-Draw Bandits: Quickly Optimizing in Nonstationary Environments with Extremely Many Arms
May 30, 2025Canonical algorithms for multi-armed bandits typically assume a stationary reward environment where the size of the action space (number of arms) is small. More recently developed methods typically relax only one of these assumptions: existing non-stationary bandit policies are designed for a small number of arms, while Lipschitz, linear, and Gaussian process bandit policies are designed to handle a large (or infinite) number of arms in stationary reward environments under constraints on the reward function. In this manuscript, we propose a novel policy to learn reward environments over a continuous space using Gaussian interpolation. We show that our method efficiently learns continuous Lipschitz reward functions with $\mathcal{O}^*(\sqrt{T})$ cumulative regret. Furthermore, our method naturally extends to non-stationary problems with a simple modification. We finally demonstrate that our method is computationally favorable (100-10000x faster) and experimentally outperforms sliding Gaussian process policies on datasets with non-stationarity and an extremely large number of arms.
Graph-Based Re-ranking: Emerging Techniques, Limitations, and Opportunities
Mar 19, 2025Knowledge graphs have emerged to be promising datastore candidates for context augmentation during Retrieval Augmented Generation (RAG). As a result, techniques in graph representation learning have been simultaneously explored alongside principal neural information retrieval approaches, such as two-phased retrieval, also known as re-ranking. While Graph Neural Networks (GNNs) have been proposed to demonstrate proficiency in graph learning for re-ranking, there are ongoing limitations in modeling and evaluating input graph structures for training and evaluation for passage and document ranking tasks. In this survey, we review emerging GNN-based ranking model architectures along with their corresponding graph representation construction methodologies. We conclude by providing recommendations on future research based on community-wide challenges and opportunities.
Living off the Analyst: Harvesting Features from Yara Rules for Malware Detection
Nov 27, 2024
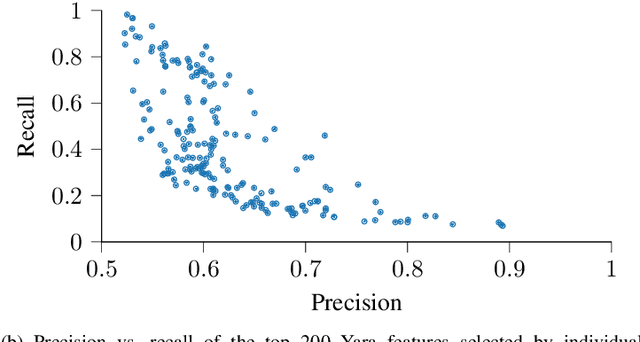
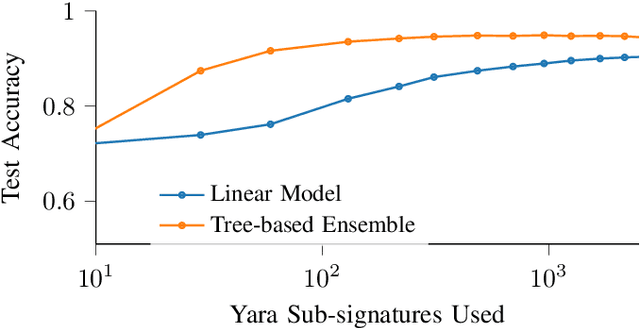
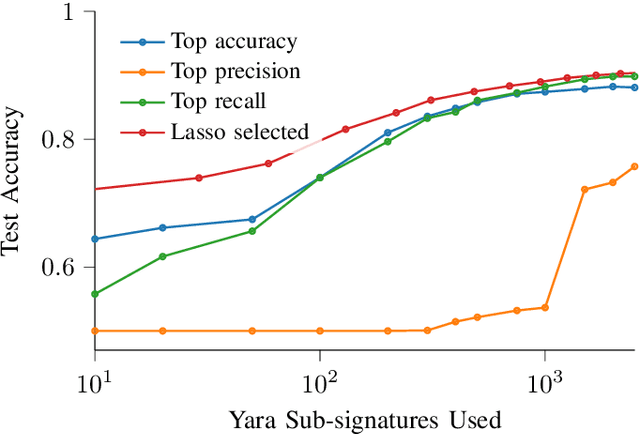
A strategy used by malicious actors is to "live off the land," where benign systems and tools already available on a victim's systems are used and repurposed for the malicious actor's intent. In this work, we ask if there is a way for anti-virus developers to similarly re-purpose existing work to improve their malware detection capability. We show that this is plausible via YARA rules, which use human-written signatures to detect specific malware families, functionalities, or other markers of interest. By extracting sub-signatures from publicly available YARA rules, we assembled a set of features that can more effectively discriminate malicious samples from benign ones. Our experiments demonstrate that these features add value beyond traditional features on the EMBER 2018 dataset. Manual analysis of the added sub-signatures shows a power-law behavior in a combination of features that are specific and unique, as well as features that occur often. A prior expectation may be that the features would be limited in being overly specific to unique malware families. This behavior is observed, and is apparently useful in practice. In addition, we also find sub-signatures that are dual-purpose (e.g., detecting virtual machine environments) or broadly generic (e.g., DLL imports).
Stabilizing Linear Passive-Aggressive Online Learning with Weighted Reservoir Sampling
Oct 31, 2024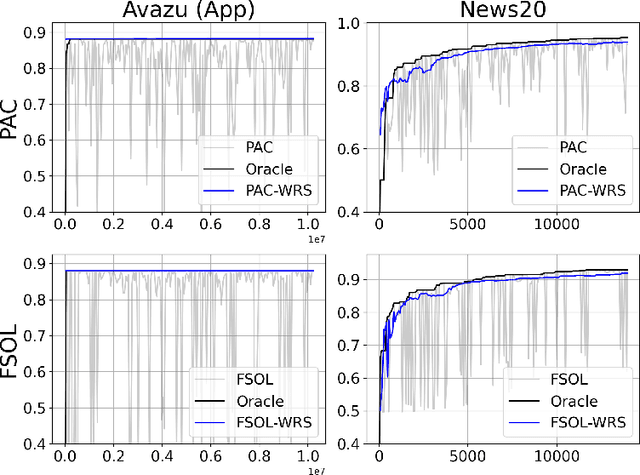
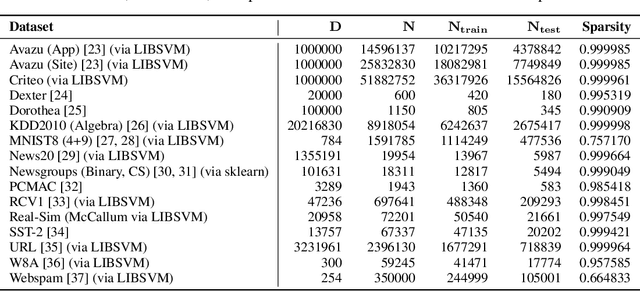
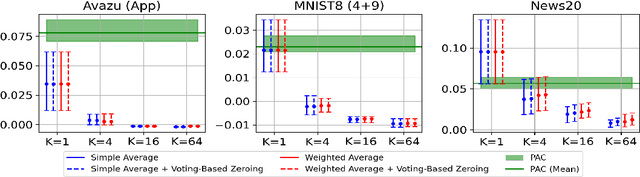
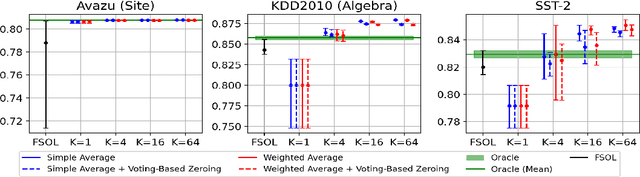
Online learning methods, like the seminal Passive-Aggressive (PA) classifier, are still highly effective for high-dimensional streaming data, out-of-core processing, and other throughput-sensitive applications. Many such algorithms rely on fast adaptation to individual errors as a key to their convergence. While such algorithms enjoy low theoretical regret, in real-world deployment they can be sensitive to individual outliers that cause the algorithm to over-correct. When such outliers occur at the end of the data stream, this can cause the final solution to have unexpectedly low accuracy. We design a weighted reservoir sampling (WRS) approach to obtain a stable ensemble model from the sequence of solutions without requiring additional passes over the data, hold-out sets, or a growing amount of memory. Our key insight is that good solutions tend to be error-free for more iterations than bad solutions, and thus, the number of passive rounds provides an estimate of a solution's relative quality. Our reservoir thus contains $K$ previous intermediate weight vectors with high survival times. We demonstrate our WRS approach on the Passive-Aggressive Classifier (PAC) and First-Order Sparse Online Learning (FSOL), where our method consistently and significantly outperforms the unmodified approach. We show that the risk of the ensemble classifier is bounded with respect to the regret of the underlying online learning method.
Is Function Similarity Over-Engineered? Building a Benchmark
Oct 30, 2024Binary analysis is a core component of many critical security tasks, including reverse engineering, malware analysis, and vulnerability detection. Manual analysis is often time-consuming, but identifying commonly-used or previously-seen functions can reduce the time it takes to understand a new file. However, given the complexity of assembly, and the NP-hard nature of determining function equivalence, this task is extremely difficult. Common approaches often use sophisticated disassembly and decompilation tools, graph analysis, and other expensive pre-processing steps to perform function similarity searches over some corpus. In this work, we identify a number of discrepancies between the current research environment and the underlying application need. To remedy this, we build a new benchmark, REFuSE-Bench, for binary function similarity detection consisting of high-quality datasets and tests that better reflect real-world use cases. In doing so, we address issues like data duplication and accurate labeling, experiment with real malware, and perform the first serious evaluation of ML binary function similarity models on Windows data. Our benchmark reveals that a new, simple basline, one which looks at only the raw bytes of a function, and requires no disassembly or other pre-processing, is able to achieve state-of-the-art performance in multiple settings. Our findings challenge conventional assumptions that complex models with highly-engineered features are being used to their full potential, and demonstrate that simpler approaches can provide significant value.
A Walsh Hadamard Derived Linear Vector Symbolic Architecture
Oct 30, 2024
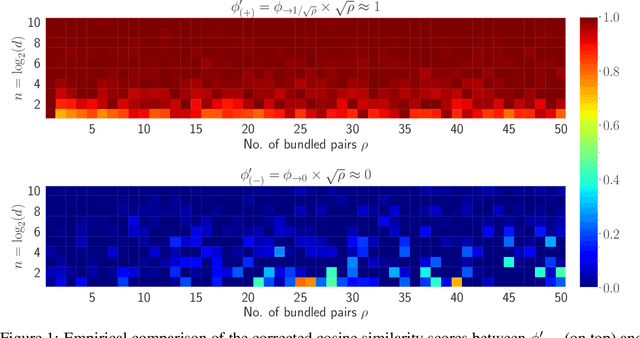


Vector Symbolic Architectures (VSAs) are one approach to developing Neuro-symbolic AI, where two vectors in $\mathbb{R}^d$ are `bound' together to produce a new vector in the same space. VSAs support the commutativity and associativity of this binding operation, along with an inverse operation, allowing one to construct symbolic-style manipulations over real-valued vectors. Most VSAs were developed before deep learning and automatic differentiation became popular and instead focused on efficacy in hand-designed systems. In this work, we introduce the Hadamard-derived linear Binding (HLB), which is designed to have favorable computational efficiency, and efficacy in classic VSA tasks, and perform well in differentiable systems. Code is available at https://github.com/FutureComputing4AI/Hadamard-derived-Linear-Binding
High-Dimensional Distributed Sparse Classification with Scalable Communication-Efficient Global Updates
Jul 08, 2024



As the size of datasets used in statistical learning continues to grow, distributed training of models has attracted increasing attention. These methods partition the data and exploit parallelism to reduce memory and runtime, but suffer increasingly from communication costs as the data size or the number of iterations grows. Recent work on linear models has shown that a surrogate likelihood can be optimized locally to iteratively improve on an initial solution in a communication-efficient manner. However, existing versions of these methods experience multiple shortcomings as the data size becomes massive, including diverging updates and efficiently handling sparsity. In this work we develop solutions to these problems which enable us to learn a communication-efficient distributed logistic regression model even beyond millions of features. In our experiments we demonstrate a large improvement in accuracy over distributed algorithms with only a few distributed update steps needed, and similar or faster runtimes. Our code is available at \url{https://github.com/FutureComputing4AI/ProxCSL}.
Optimizing the Optimal Weighted Average: Efficient Distributed Sparse Classification
Jun 03, 2024While distributed training is often viewed as a solution to optimizing linear models on increasingly large datasets, inter-machine communication costs of popular distributed approaches can dominate as data dimensionality increases. Recent work on non-interactive algorithms shows that approximate solutions for linear models can be obtained efficiently with only a single round of communication among machines. However, this approximation often degenerates as the number of machines increases. In this paper, building on the recent optimal weighted average method, we introduce a new technique, ACOWA, that allows an extra round of communication to achieve noticeably better approximation quality with minor runtime increases. Results show that for sparse distributed logistic regression, ACOWA obtains solutions that are more faithful to the empirical risk minimizer and attain substantially higher accuracy than other distributed algorithms.