 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASSEMBLAGE-DEEPHISTORY: A Cross-Build Binary Dataset with Temporal Coverage
May 20, 2026Existing binary corpora typically capture only one or two axes of binary variation: they either provide cross-compiler builds without a temporal axis, or CVE labels for single-build binaries. None combine cross-build diversity, cross-version history, and CVE labels into a queryable structure. We present ASSEMBLAGE-DEEPHISTORY, which consolidates these dimensions into a unified framework where every binary's compilation context, source code, vulnerable functions, and package version are stored as first-class metadata. ASSEMBLAGE-DEEPHISTORY comprises 73,610 binaries spanning 248 open-source projects, compiled across GCC, Clang, and MSVC at multiple optimization levels on Linux and Windows, with multi-year historical builds. Each binary is indexed in a database that links it to its source code, functions, debug info, variant builds, historical versions, and vulnerable functions. Three analyses demonstrate this structure's value: (1) a three-stage LLM benchmark (recognition, strategy-guided detection, and cross-build transfer) to test whether LLMs reason about binary vulnerabilities or pattern-match on build-specific artifacts; (2) a comparison of MalConv embeddings, jTrans function embeddings, and TLSH fuzzy hashes quantifying how same-package versions cluster in each space; and (3) a Bayesian regression decomposing binary similarity into contributions from temporal distance, file changes, and commits.
Is Function Similarity Over-Engineered? Building a Benchmark
Oct 30, 2024



Binary analysis is a core component of many critical security tasks, including reverse engineering, malware analysis, and vulnerability detection. Manual analysis is often time-consuming, but identifying commonly-used or previously-seen functions can reduce the time it takes to understand a new file. However, given the complexity of assembly, and the NP-hard nature of determining function equivalence, this task is extremely difficult. Common approaches often use sophisticated disassembly and decompilation tools, graph analysis, and other expensive pre-processing steps to perform function similarity searches over some corpus. In this work, we identify a number of discrepancies between the current research environment and the underlying application need. To remedy this, we build a new benchmark, REFuSE-Bench, for binary function similarity detection consisting of high-quality datasets and tests that better reflect real-world use cases. In doing so, we address issues like data duplication and accurate labeling, experiment with real malware, and perform the first serious evaluation of ML binary function similarity models on Windows data. Our benchmark reveals that a new, simple basline, one which looks at only the raw bytes of a function, and requires no disassembly or other pre-processing, is able to achieve state-of-the-art performance in multiple settings. Our findings challenge conventional assumptions that complex models with highly-engineered features are being used to their full potential, and demonstrate that simpler approaches can provide significant value.
Assemblage: Automatic Binary Dataset Construction for Machine Learning
May 07, 2024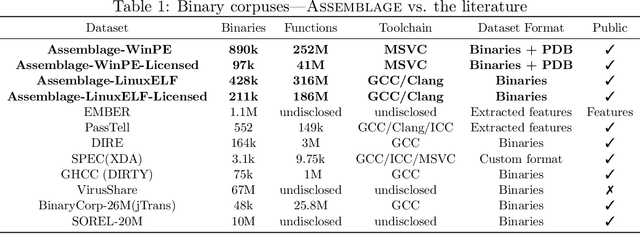
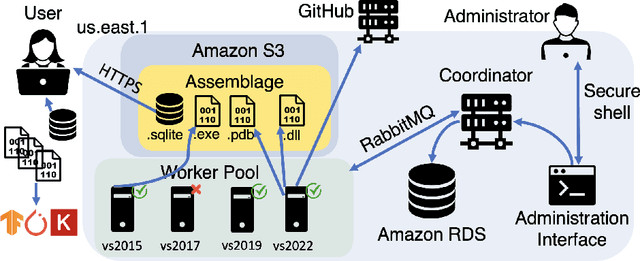

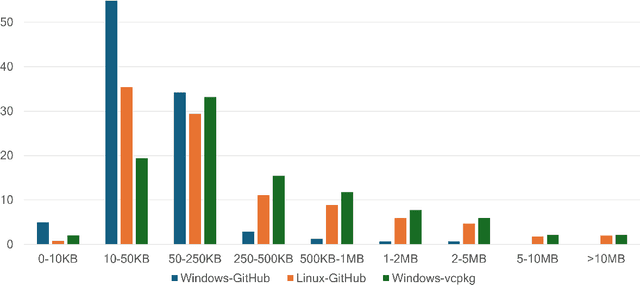
Binary code is pervasive, and binary analysis is a key task in reverse engineering, malware classification, and vulnerability discovery. Unfortunately, while there exist large corpuses of malicious binaries, obtaining high-quality corpuses of benign binaries for modern systems has proven challenging (e.g., due to licensing issues). Consequently, machine learning based pipelines for binary analysis utilize either costly commercial corpuses (e.g., VirusTotal) or open-source binaries (e.g., coreutils) available in limited quantities. To address these issues, we present Assemblage: an extensible cloud-based distributed system that crawls, configures, and builds Windows PE binaries to obtain high-quality binary corpuses suitable for training state-of-the-art models in binary analysis. We have run Assemblage on AWS over the past year, producing 890k Windows PE and 428k Linux ELF binaries across 29 configurations. Assemblage is designed to be both reproducible and extensible, enabling users to publish "recipes" for their datasets, and facilitating the extraction of a wide array of features. We evaluated Assemblage by using its data to train modern learning-based pipelines for compiler provenance and binary function similarity. Our results illustrate the practical need for robust corpuses of high-quality Windows PE binaries in training modern learning-based binary analyses. Assemblage can be downloaded from https://assemblage-dataset.net