 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMBER2024 -- A Benchmark Dataset for Holistic Evaluation of Malware Classifiers
Jun 05, 2025



A lack of accessible data has historically restricted malware analysis research, and practitioners have relied heavily on datasets provided by industry sources to advance. Existing public datasets are limited by narrow scope - most include files targeting a single platform, have labels supporting just one type of malware classification task, and make no effort to capture the evasive files that make malware detection difficult in practice. We present EMBER2024, a new dataset that enables holistic evaluation of malware classifiers. Created in collaboration with the authors of EMBER2017 and EMBER2018, the EMBER2024 dataset includes hashes, metadata, feature vectors, and labels for more than 3.2 million files from six file formats. Our dataset supports the training and evaluation of machine learning models on seven malware classification tasks, including malware detection, malware family classification, and malware behavior identification. EMBER2024 is the first to include a collection of malicious files that initially went undetected by a set of antivirus products, creating a "challenge" set to assess classifier performance against evasive malware. This work also introduces EMBER feature version 3, with added support for several new feature types. We are releasing the EMBER2024 dataset to promote reproducibility and empower researchers in the pursuit of new malware research topics.
Is Function Similarity Over-Engineered? Building a Benchmark
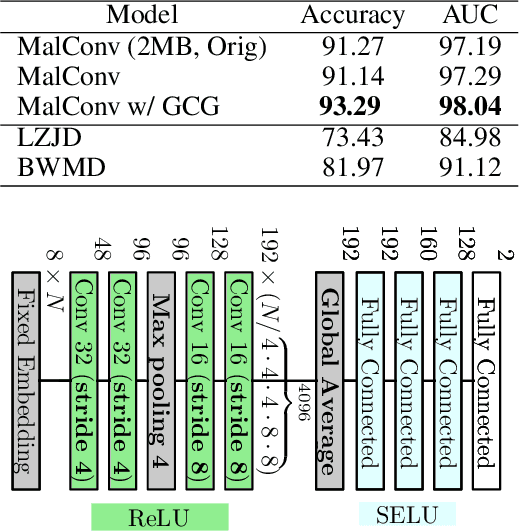
Oct 30, 2024Binary analysis is a core component of many critical security tasks, including reverse engineering, malware analysis, and vulnerability detection. Manual analysis is often time-consuming, but identifying commonly-used or previously-seen functions can reduce the time it takes to understand a new file. However, given the complexity of assembly, and the NP-hard nature of determining function equivalence, this task is extremely difficult. Common approaches often use sophisticated disassembly and decompilation tools, graph analysis, and other expensive pre-processing steps to perform function similarity searches over some corpus. In this work, we identify a number of discrepancies between the current research environment and the underlying application need. To remedy this, we build a new benchmark, REFuSE-Bench, for binary function similarity detection consisting of high-quality datasets and tests that better reflect real-world use cases. In doing so, we address issues like data duplication and accurate labeling, experiment with real malware, and perform the first serious evaluation of ML binary function similarity models on Windows data. Our benchmark reveals that a new, simple basline, one which looks at only the raw bytes of a function, and requires no disassembly or other pre-processing, is able to achieve state-of-the-art performance in multiple settings. Our findings challenge conventional assumptions that complex models with highly-engineered features are being used to their full potential, and demonstrate that simpler approaches can provide significant value.
Classifying Sequences of Extreme Length with Constant Memory Applied to Malware Detection
Dec 17, 2020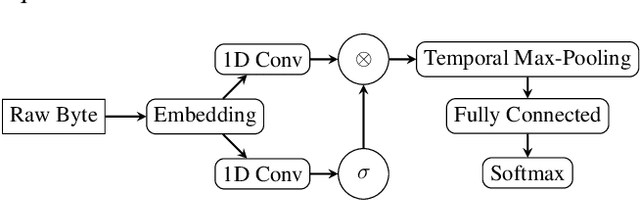

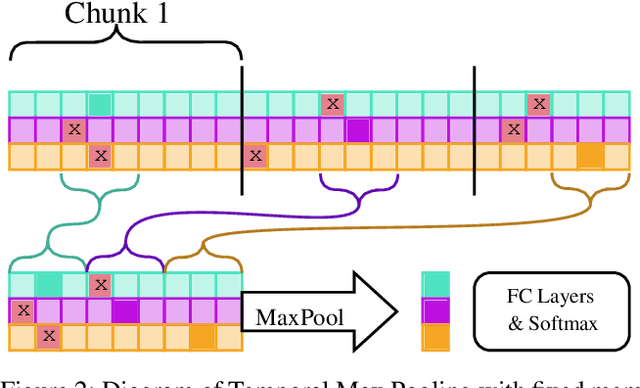
Recent works within machine learning have been tackling inputs of ever-increasing size, with cybersecurity presenting sequence classification problems of particularly extreme lengths. In the case of Windows executable malware detection, inputs may exceed $100$ MB, which corresponds to a time series with $T=100,000,000$ steps. To date, the closest approach to handling such a task is MalConv, a convolutional neural network capable of processing up to $T=2,000,000$ steps. The $\mathcal{O}(T)$ memory of CNNs has prevented further application of CNNs to malware. In this work, we develop a new approach to temporal max pooling that makes the required memory invariant to the sequence length $T$. This makes MalConv $116\times$ more memory efficient, and up to $25.8\times$ faster to train on its original dataset, while removing the input length restrictions to MalConv. We re-invest these gains into improving the MalConv architecture by developing a new Global Channel Gating design, giving us an attention mechanism capable of learning feature interactions across 100 million time steps in an efficient manner, a capability lacked by the original MalConv CNN. Our implementation can be found at https://github.com/NeuromorphicComputationResearchProgram/MalConv2
Automatic Yara Rule Generation Using Biclustering
Sep 06, 2020

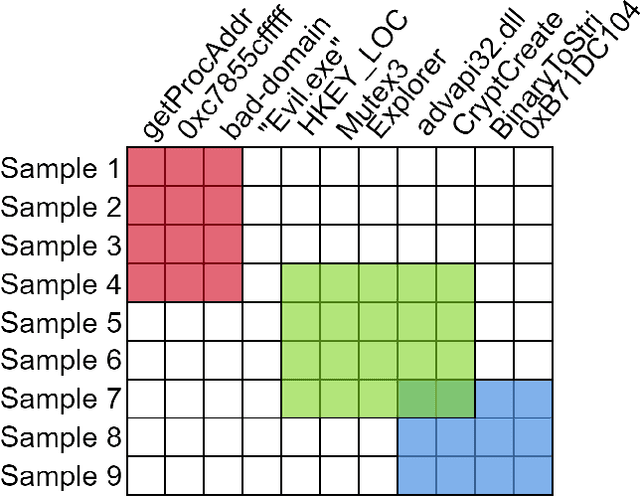

Yara rules are a ubiquitous tool among cybersecurity practitioners and analysts. Developing high-quality Yara rules to detect a malware family of interest can be labor- and time-intensive, even for expert users. Few tools exist and relatively little work has been done on how to automate the generation of Yara rules for specific families. In this paper, we leverage large n-grams ($n \geq 8$) combined with a new biclustering algorithm to construct simple Yara rules more effectively than currently available software. Our method, AutoYara, is fast, allowing for deployment on low-resource equipment for teams that deploy to remote networks. Our results demonstrate that AutoYara can help reduce analyst workload by producing rules with useful true-positive rates while maintaining low false-positive rates, sometimes matching or even outperforming human analysts. In addition, real-world testing by malware analysts indicates AutoYara could reduce analyst time spent constructing Yara rules by 44-86%, allowing them to spend their time on the more advanced malware that current tools can't handle. Code will be made available at https://github.com/NeuromorphicComputationResearchProgram .
KiloGrams: Very Large N-Grams for Malware Classification
Aug 01, 2019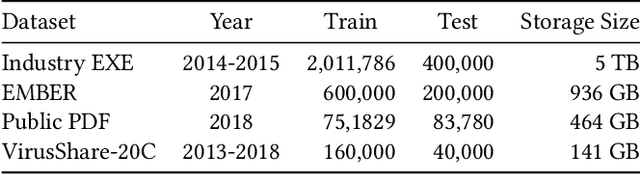
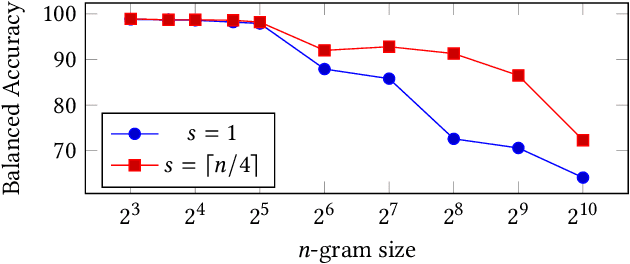
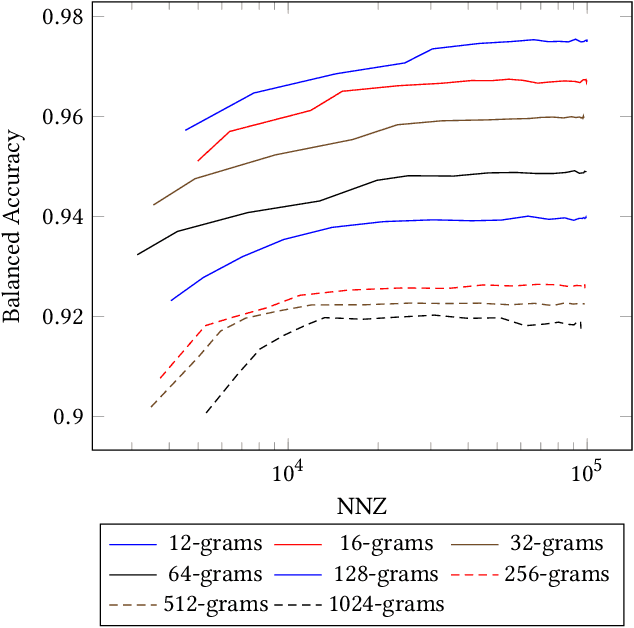
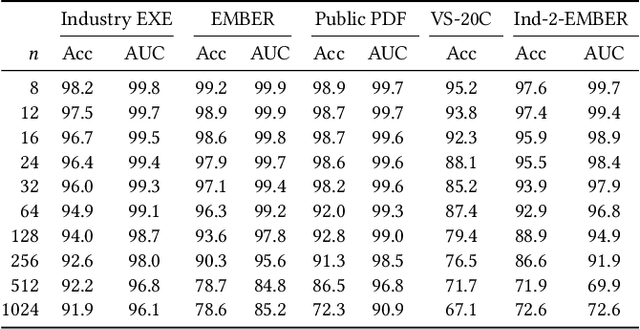
N-grams have been a common tool for information retrieval and machine learning applications for decades. In nearly all previous works, only a few values of $n$ are tested, with $n > 6$ being exceedingly rare. Larger values of $n$ are not tested due to computational burden or the fear of overfitting. In this work, we present a method to find the top-$k$ most frequent $n$-grams that is 60$\times$ faster for small $n$, and can tackle large $n\geq1024$. Despite the unprecedented size of $n$ considered, we show how these features still have predictive ability for malware classification tasks. More important, large $n$-grams provide benefits in producing features that are interpretable by malware analysis, and can be used to create general purpose signatures compatible with industry standard tools like Yara. Furthermore, the counts of common $n$-grams in a file may be added as features to publicly available human-engineered features that rival efficacy of professionally-developed features when used to train gradient-boosted decision tree models on the EMBER dataset.
RelExt: Relation Extraction using Deep Learning approaches for Cybersecurity Knowledge Graph Improvement
May 16, 2019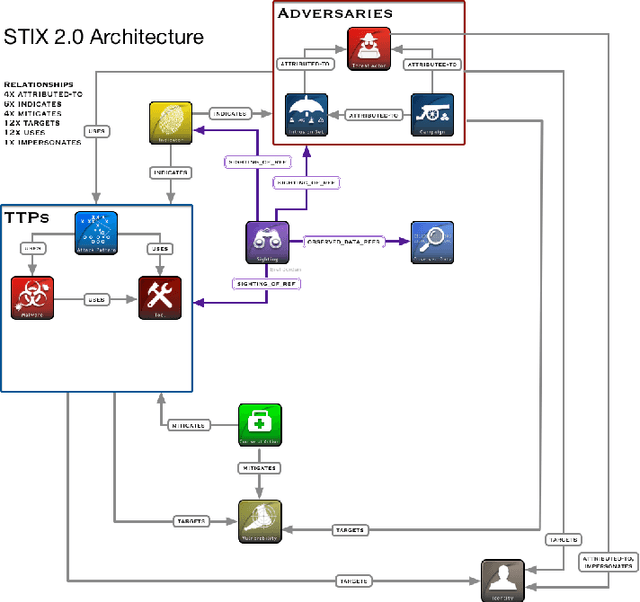

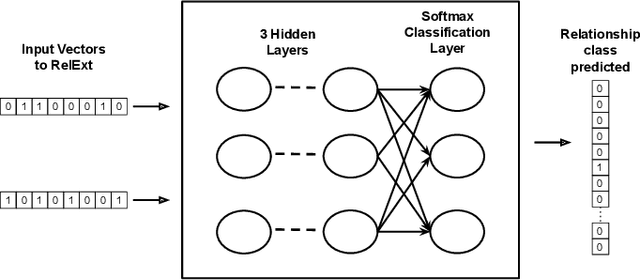

Security Analysts that work in a `Security Operations Center' (SoC) play a major role in ensuring the security of the organization. The amount of background knowledge they have about the evolving and new attacks makes a significant difference in their ability to detect attacks. Open source threat intelligence sources, like text descriptions about cyber-attacks, can be stored in a structured fashion in a cybersecurity knowledge graph. A cybersecurity knowledge graph can be paramount in aiding a security analyst to detect cyber threats because it stores a vast range of cyber threat information in the form of semantic triples which can be queried. A semantic triple contains two cybersecurity entities with a relationship between them. In this work, we propose a system to create semantic triples over cybersecurity text, using deep learning approaches to extract possible relationships. We use the set of semantic triples generated through our system to assert in a cybersecurity knowledge graph. Security Analysts can retrieve this data from the knowledge graph, and use this information to form a decision about a cyber-attack.
Static Malware Detection & Subterfuge: Quantifying the Robustness of Machine Learning and Current Anti-Virus
Jun 12, 2018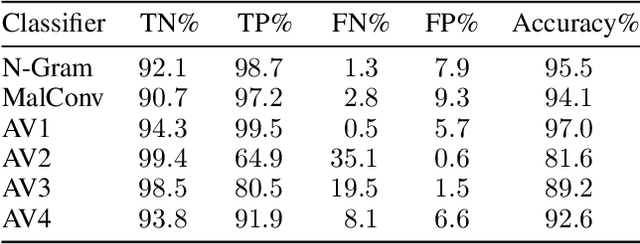
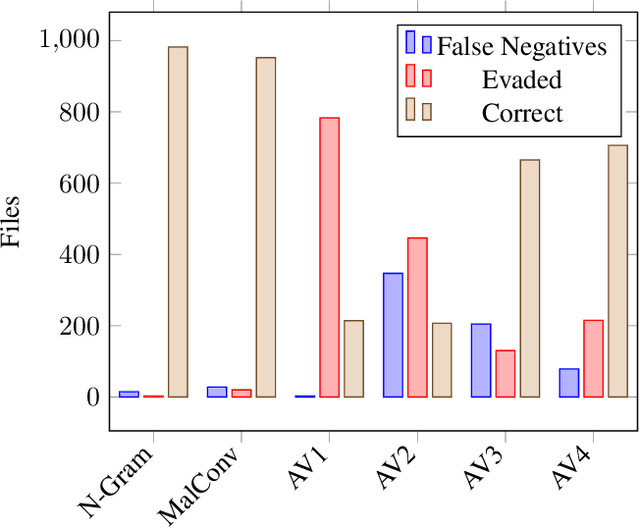
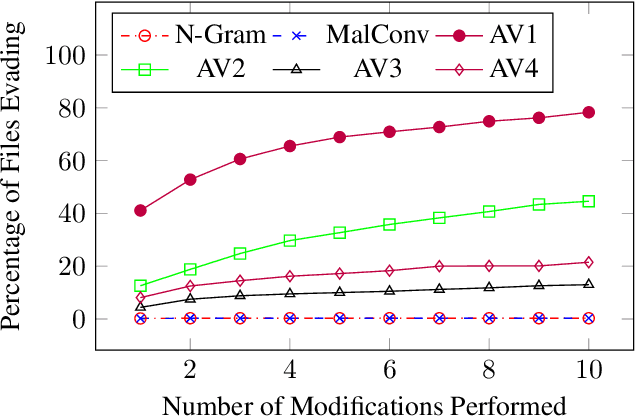
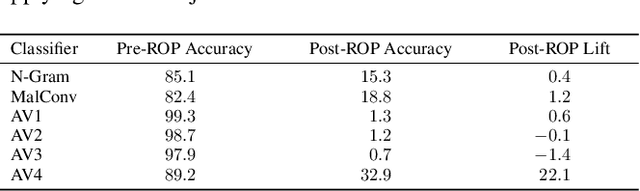
As machine-learning (ML) based systems for malware detection become more prevalent, it becomes necessary to quantify the benefits compared to the more traditional anti-virus (AV) systems widely used today. It is not practical to build an agreed upon test set to benchmark malware detection systems on pure classification performance. Instead we tackle the problem by creating a new testing methodology, where we evaluate the change in performance on a set of known benign & malicious files as adversarial modifications are performed. The change in performance combined with the evasion techniques then quantifies a system's robustness against that approach. Through these experiments we are able to show in a quantifiable way how purely ML based systems can be more robust than AV products at detecting malware that attempts evasion through modification, but may be slower to adapt in the face of significantly novel attacks.