 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking LoRA Memory Through the Lens of KV Cache Compression
Jun 04, 2026Parametric retrieval augmentation encodes document information into lightweight, document-specific modules such as LoRA adapters, reducing the need to include all evidence as input context. However, it remains unclear how this parameter-side memory interacts with context-side memory stored in the KV cache. We study this interaction in document-level question answering by progressively evicting document key-value states and measuring when a document LoRA contributes beyond the retained context. We find that document LoRA adds little when the KV cache is largely intact, but becomes increasingly useful under aggressive compression, recovering 13-21 ROUGE-L points when no document context remains. The gain is largest when the base model encodes the document, and the adapter is applied only during answer generation, suggesting that document LoRA is better understood as decoding-time parametric memory than as a document encoder. Finally, QA-style supervision produces substantially stronger adapters than raw-context next-token-prediction. These results position document LoRA as a complementary memory channel whose value emerges precisely when context-side evidence is scarce.
mmBERT: A Modern Multilingual Encoder with Annealed Language Learning
Sep 08, 2025Encoder-only languages models are frequently used for a variety of standard machine learning tasks, including classification and retrieval. However, there has been a lack of recent research for encoder models, especially with respect to multilingual models. We introduce mmBERT, an encoder-only language model pretrained on 3T tokens of multilingual text in over 1800 languages. To build mmBERT we introduce several novel elements, including an inverse mask ratio schedule and an inverse temperature sampling ratio. We add over 1700 low-resource languages to the data mix only during the decay phase, showing that it boosts performance dramatically and maximizes the gains from the relatively small amount of training data. Despite only including these low-resource languages in the short decay phase we achieve similar classification performance to models like OpenAI's o3 and Google's Gemini 2.5 Pro. Overall, we show that mmBERT significantly outperforms the previous generation of models on classification and retrieval tasks -- on both high and low-resource languages.
SpectR: Dynamically Composing LM Experts with Spectral Routing
Apr 04, 2025Training large, general-purpose language models poses significant challenges. The growing availability of specialized expert models, fine-tuned from pretrained models for specific tasks or domains, offers a promising alternative. Leveraging the potential of these existing expert models in real-world applications requires effective methods to select or merge the models best suited for a given task. This paper introduces SPECTR, an approach for dynamically composing expert models at each time step during inference. Notably, our method requires no additional training and enables flexible, token- and layer-wise model combinations. Our experimental results demonstrate that SPECTR improves routing accuracy over alternative training-free methods, increasing task performance across expert domains.
RE-AdaptIR: Improving Information Retrieval through Reverse Engineered Adaptation
Jun 20, 2024



Large language models (LLMs) fine-tuned for text-retrieval have demonstrated state-of-the-art results across several information retrieval (IR) benchmarks. However, supervised training for improving these models requires numerous labeled examples, which are generally unavailable or expensive to acquire. In this work, we explore the effectiveness of extending reverse engineered adaptation to the context of information retrieval (RE-AdaptIR). We use RE-AdaptIR to improve LLM-based IR models using only unlabeled data. We demonstrate improved performance both in training domains as well as zero-shot in domains where the models have seen no queries. We analyze performance changes in various fine-tuning scenarios and offer findings of immediate use to practitioners.
RE-Adapt: Reverse Engineered Adaptation of Large Language Models
May 23, 2024

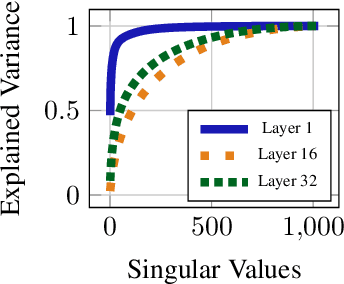

We introduce RE-Adapt, an approach to fine-tuning large language models on new domains without degrading any pre-existing instruction-tuning. We reverse engineer an adapter which isolates what an instruction-tuned model has learned beyond its corresponding pretrained base model. Importantly, this requires no additional data or training. We can then fine-tune the base model on a new domain and readapt it to instruction following with the reverse engineered adapter. RE-Adapt and our low-rank variant LoRE-Adapt both outperform other methods of fine-tuning, across multiple popular LLMs and datasets, even when the models are used in conjunction with retrieval-augmented generation.
AdapterSwap: Continuous Training of LLMs with Data Removal and Access-Control Guarantees
Apr 12, 2024Large language models (LLMs) are increasingly capable of completing knowledge intensive tasks by recalling information from a static pretraining corpus. Here we are concerned with LLMs in the context of evolving data requirements. For instance: batches of new data that are introduced periodically; subsets of data with user-based access controls; or requirements on dynamic removal of documents with guarantees that associated knowledge cannot be recalled. We wish to satisfy these requirements while at the same time ensuring a model does not forget old information when new data becomes available. To address these issues, we introduce AdapterSwap, a training and inference scheme that organizes knowledge from a data collection into a set of low-rank adapters, which are dynamically composed during inference. Our experiments demonstrate AdapterSwap's ability to support efficient continual learning, while also enabling organizations to have fine-grained control over data access and deletion.
Toucan: Token-Aware Character Level Language Modeling
Nov 15, 2023Character-level language models obviate the need for separately trained tokenizers, but efficiency suffers from longer sequence lengths. Learning to combine character representations into tokens has made training these models more efficient, but they still require decoding characters individually. We propose Toucan, an augmentation to character-level models to make them "token-aware". Comparing our method to prior work, we demonstrate significant speed-ups in character generation without a loss in language modeling performance. We then explore differences between our learned dynamic tokenization of character sequences with popular fixed vocabulary solutions such as Byte-Pair Encoding and WordPiece, finding our approach leads to a greater amount of longer sequences tokenized as single items. Our project and code are available at https://nlp.jhu.edu/nuggets/.
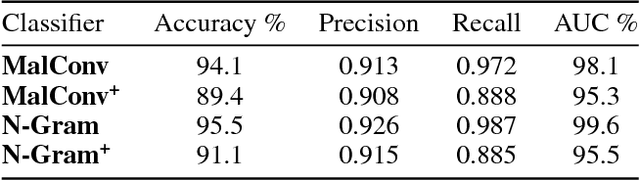
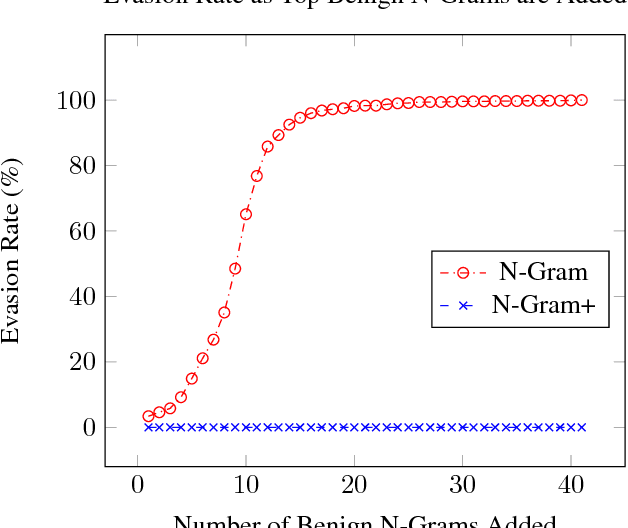
Classifying Sequences of Extreme Length with Constant Memory Applied to Malware Detection
Dec 17, 2020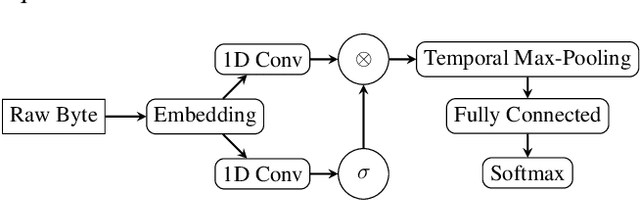

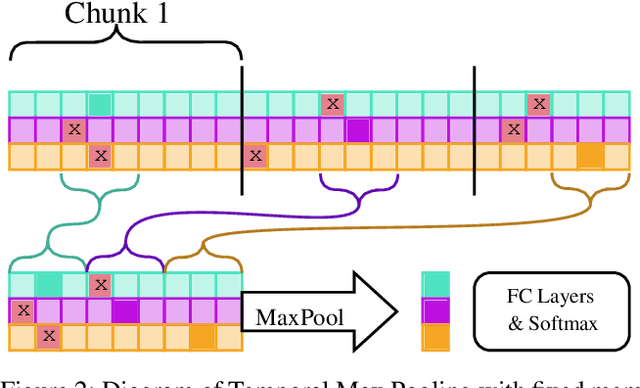
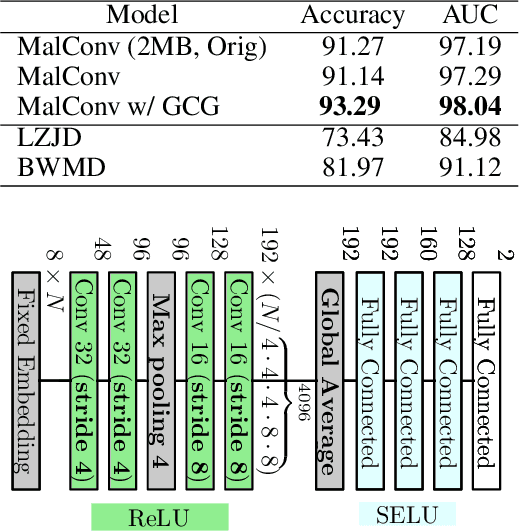
Recent works within machine learning have been tackling inputs of ever-increasing size, with cybersecurity presenting sequence classification problems of particularly extreme lengths. In the case of Windows executable malware detection, inputs may exceed $100$ MB, which corresponds to a time series with $T=100,000,000$ steps. To date, the closest approach to handling such a task is MalConv, a convolutional neural network capable of processing up to $T=2,000,000$ steps. The $\mathcal{O}(T)$ memory of CNNs has prevented further application of CNNs to malware. In this work, we develop a new approach to temporal max pooling that makes the required memory invariant to the sequence length $T$. This makes MalConv $116\times$ more memory efficient, and up to $25.8\times$ faster to train on its original dataset, while removing the input length restrictions to MalConv. We re-invest these gains into improving the MalConv architecture by developing a new Global Channel Gating design, giving us an attention mechanism capable of learning feature interactions across 100 million time steps in an efficient manner, a capability lacked by the original MalConv CNN. Our implementation can be found at https://github.com/NeuromorphicComputationResearchProgram/MalConv2
Non-Negative Networks Against Adversarial Attacks
Jun 15, 2018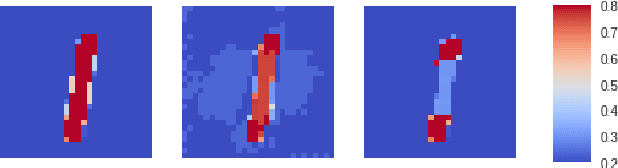
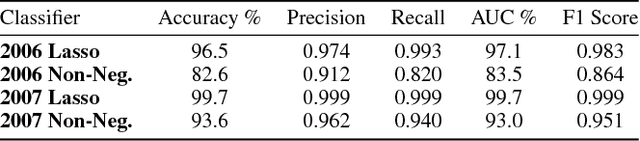
Adversarial attacks against Neural Networks are a problem of considerable importance, for which effective defenses are not yet readily available. We make progress toward this problem by showing that non-negative weight constraints can be used to improve resistance in specific scenarios. In particular, we show that they can provide an effective defense for binary classification problems with asymmetric cost, such as malware or spam detection. We also show how non-negativity can be leveraged to reduce an attacker's ability to perform targeted misclassification attacks in other domains such as image processing.
Static Malware Detection & Subterfuge: Quantifying the Robustness of Machine Learning and Current Anti-Virus
Jun 12, 2018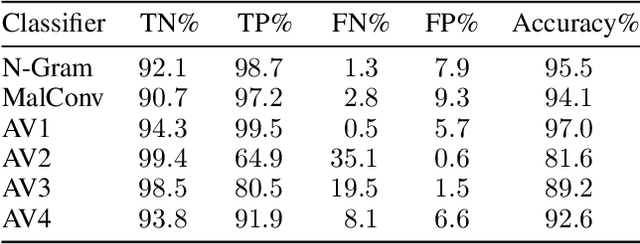
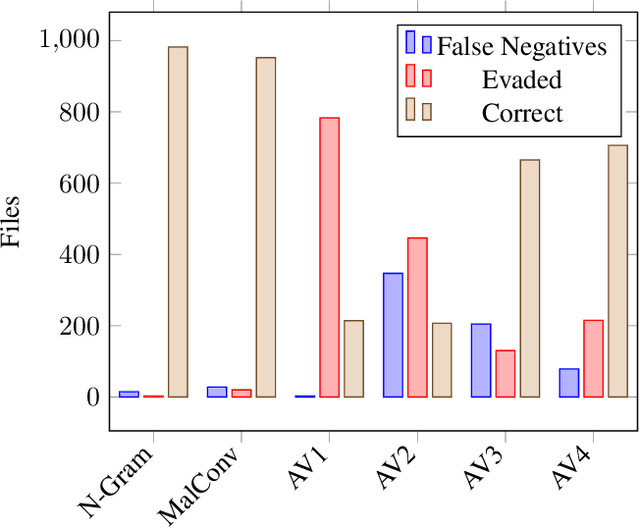
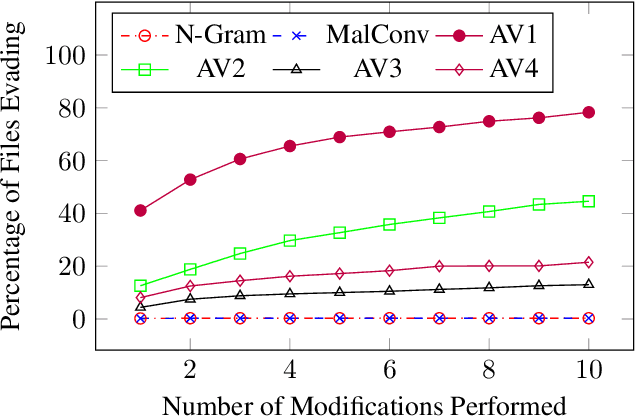
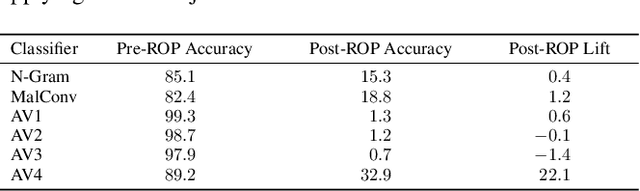
As machine-learning (ML) based systems for malware detection become more prevalent, it becomes necessary to quantify the benefits compared to the more traditional anti-virus (AV) systems widely used today. It is not practical to build an agreed upon test set to benchmark malware detection systems on pure classification performance. Instead we tackle the problem by creating a new testing methodology, where we evaluate the change in performance on a set of known benign & malicious files as adversarial modifications are performed. The change in performance combined with the evasion techniques then quantifies a system's robustness against that approach. Through these experiments we are able to show in a quantifiable way how purely ML based systems can be more robust than AV products at detecting malware that attempts evasion through modification, but may be slower to adapt in the face of significantly novel attacks.