 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: On the Offensive Potential of AI
Dec 24, 2024



Our society increasingly benefits from Artificial Intelligence (AI). Unfortunately, more and more evidence shows that AI is also used for offensive purposes. Prior works have revealed various examples of use cases in which the deployment of AI can lead to violation of security and privacy objectives. No extant work, however, has been able to draw a holistic picture of the offensive potential of AI. In this SoK paper we seek to lay the ground for a systematic analysis of the heterogeneous capabilities of offensive AI. In particular we (i) account for AI risks to both humans and systems while (ii) consolidating and distilling knowledge from academic literature, expert opinions, industrial venues, as well as laymen -- all of which being valuable sources of information on offensive AI. To enable alignment of such diverse sources of knowledge, we devise a common set of criteria reflecting essential technological factors related to offensive AI. With the help of such criteria, we systematically analyze: 95 research papers; 38 InfoSec briefings (from, e.g., BlackHat); the responses of a user study (N=549) entailing individuals with diverse backgrounds and expertise; and the opinion of 12 experts. Our contributions not only reveal concerning ways (some of which overlooked by prior work) in which AI can be offensively used today, but also represent a foothold to address this threat in the years to come.
Machine Learning Model Attribution Challenge
Feb 17, 2023



We present the findings of the Machine Learning Model Attribution Challenge. Fine-tuned machine learning models may derive from other trained models without obvious attribution characteristics. In this challenge, participants identify the publicly-available base models that underlie a set of anonymous, fine-tuned large language models (LLMs) using only textual output of the models. Contestants aim to correctly attribute the most fine-tuned models, with ties broken in the favor of contestants whose solutions use fewer calls to the fine-tuned models' API. The most successful approaches were manual, as participants observed similarities between model outputs and developed attribution heuristics based on public documentation of the base models, though several teams also submitted automated, statistical solutions.
"Real Attackers Don't Compute Gradients": Bridging the Gap Between Adversarial ML Research and Practice
Dec 29, 2022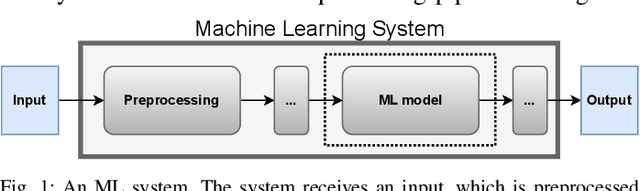
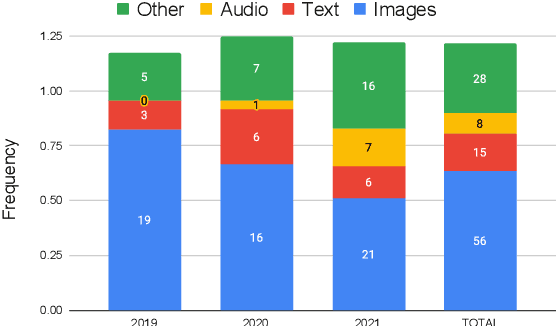
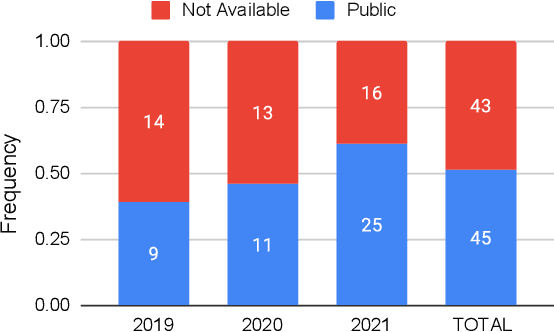
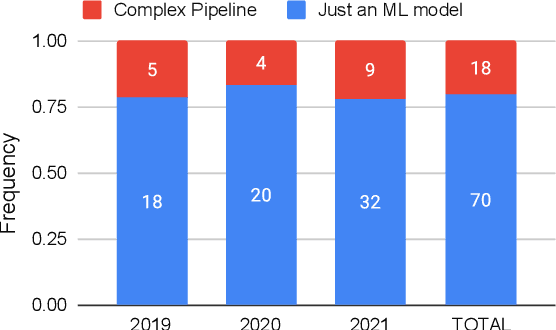
Recent years have seen a proliferation of research on adversarial machine learning. Numerous papers demonstrate powerful algorithmic attacks against a wide variety of machine learning (ML) models, and numerous other papers propose defenses that can withstand most attacks. However, abundant real-world evidence suggests that actual attackers use simple tactics to subvert ML-driven systems, and as a result security practitioners have not prioritized adversarial ML defenses. Motivated by the apparent gap between researchers and practitioners, this position paper aims to bridge the two domains. We first present three real-world case studies from which we can glean practical insights unknown or neglected in research. Next we analyze all adversarial ML papers recently published in top security conferences, highlighting positive trends and blind spots. Finally, we state positions on precise and cost-driven threat modeling, collaboration between industry and academia, and reproducible research. We believe that our positions, if adopted, will increase the real-world impact of future endeavours in adversarial ML, bringing both researchers and practitioners closer to their shared goal of improving the security of ML systems.
Classifying Sequences of Extreme Length with Constant Memory Applied to Malware Detection
Dec 17, 2020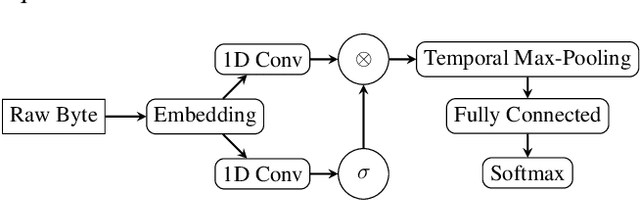

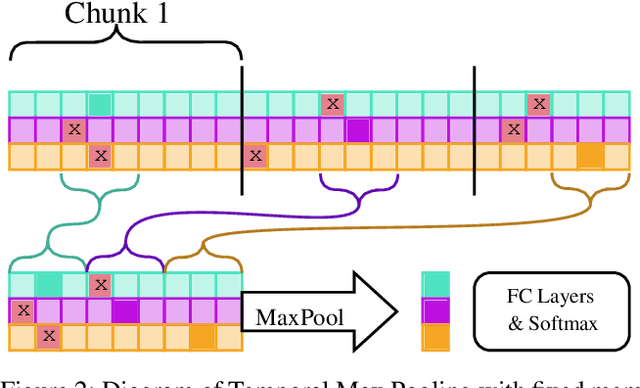
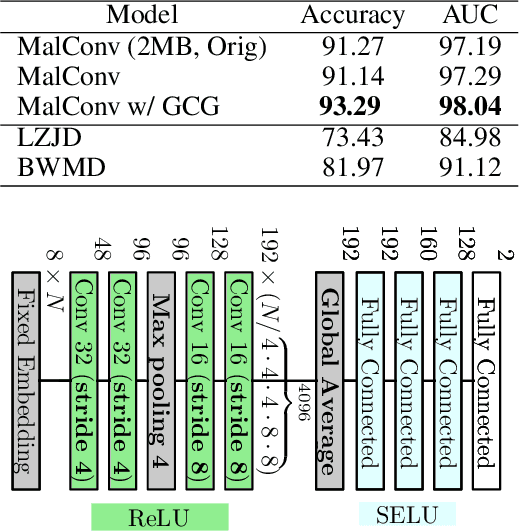
Recent works within machine learning have been tackling inputs of ever-increasing size, with cybersecurity presenting sequence classification problems of particularly extreme lengths. In the case of Windows executable malware detection, inputs may exceed $100$ MB, which corresponds to a time series with $T=100,000,000$ steps. To date, the closest approach to handling such a task is MalConv, a convolutional neural network capable of processing up to $T=2,000,000$ steps. The $\mathcal{O}(T)$ memory of CNNs has prevented further application of CNNs to malware. In this work, we develop a new approach to temporal max pooling that makes the required memory invariant to the sequence length $T$. This makes MalConv $116\times$ more memory efficient, and up to $25.8\times$ faster to train on its original dataset, while removing the input length restrictions to MalConv. We re-invest these gains into improving the MalConv architecture by developing a new Global Channel Gating design, giving us an attention mechanism capable of learning feature interactions across 100 million time steps in an efficient manner, a capability lacked by the original MalConv CNN. Our implementation can be found at https://github.com/NeuromorphicComputationResearchProgram/MalConv2
Automatic Yara Rule Generation Using Biclustering
Sep 06, 2020

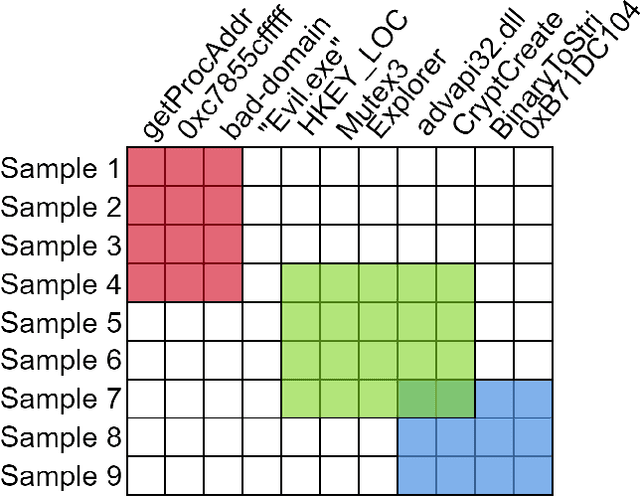

Yara rules are a ubiquitous tool among cybersecurity practitioners and analysts. Developing high-quality Yara rules to detect a malware family of interest can be labor- and time-intensive, even for expert users. Few tools exist and relatively little work has been done on how to automate the generation of Yara rules for specific families. In this paper, we leverage large n-grams ($n \geq 8$) combined with a new biclustering algorithm to construct simple Yara rules more effectively than currently available software. Our method, AutoYara, is fast, allowing for deployment on low-resource equipment for teams that deploy to remote networks. Our results demonstrate that AutoYara can help reduce analyst workload by producing rules with useful true-positive rates while maintaining low false-positive rates, sometimes matching or even outperforming human analysts. In addition, real-world testing by malware analysts indicates AutoYara could reduce analyst time spent constructing Yara rules by 44-86%, allowing them to spend their time on the more advanced malware that current tools can't handle. Code will be made available at https://github.com/NeuromorphicComputationResearchProgram .
Predicting Domain Generation Algorithms with Long Short-Term Memory Networks
Nov 02, 2016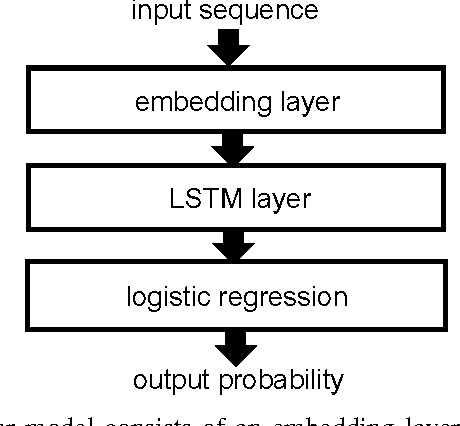
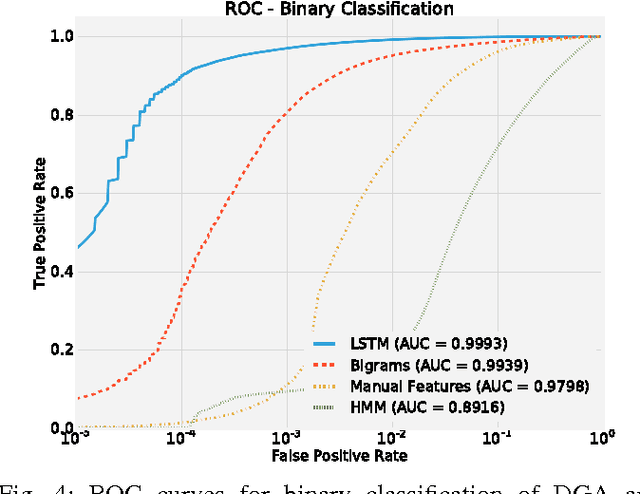


Various families of malware use domain generation algorithms (DGAs) to generate a large number of pseudo-random domain names to connect to a command and control (C&C) server. In order to block DGA C&C traffic, security organizations must first discover the algorithm by reverse engineering malware samples, then generating a list of domains for a given seed. The domains are then either preregistered or published in a DNS blacklist. This process is not only tedious, but can be readily circumvented by malware authors using a large number of seeds in algorithms with multivariate recurrence properties (e.g., banjori) or by using a dynamic list of seeds (e.g., bedep). Another technique to stop malware from using DGAs is to intercept DNS queries on a network and predict whether domains are DGA generated. Such a technique will alert network administrators to the presence of malware on their networks. In addition, if the predictor can also accurately predict the family of DGAs, then network administrators can also be alerted to the type of malware that is on their networks. This paper presents a DGA classifier that leverages long short-term memory (LSTM) networks to predict DGAs and their respective families without the need for a priori feature extraction. Results are significantly better than state-of-the-art techniques, providing 0.9993 area under the receiver operating characteristic curve for binary classification and a micro-averaged F1 score of 0.9906. In other terms, the LSTM technique can provide a 90% detection rate with a 1:10000 false positive (FP) rate---a twenty times FP improvement over comparable methods. Experiments in this paper are run on open datasets and code snippets are provided to reproduce the results.
DeepDGA: Adversarially-Tuned Domain Generation and Detection
Oct 06, 2016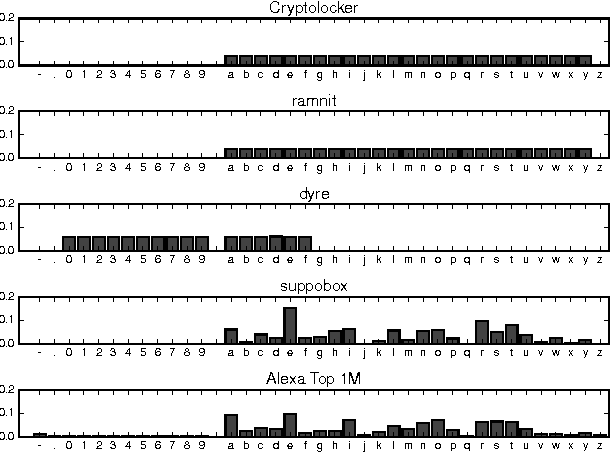
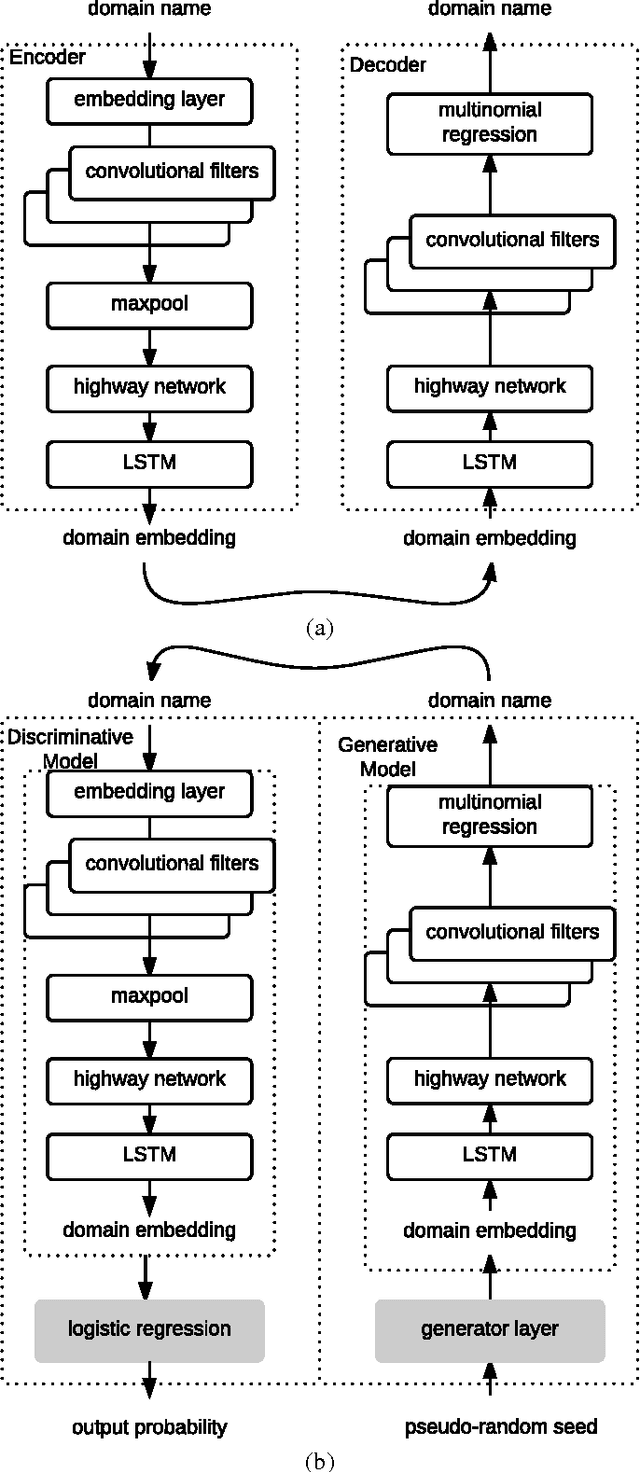
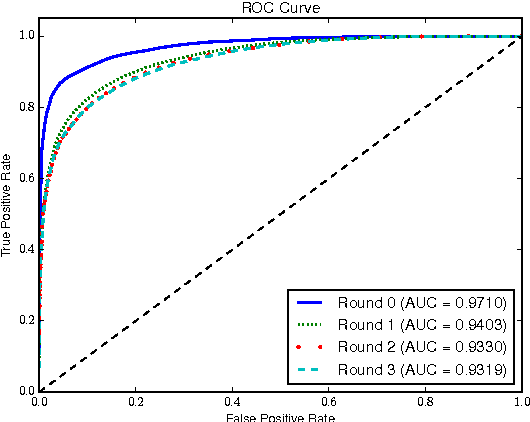
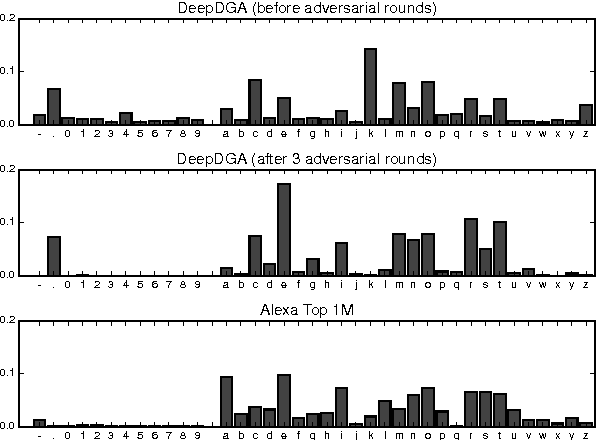
Many malware families utilize domain generation algorithms (DGAs) to establish command and control (C&C) connections. While there are many methods to pseudorandomly generate domains, we focus in this paper on detecting (and generating) domains on a per-domain basis which provides a simple and flexible means to detect known DGA families. Recent machine learning approaches to DGA detection have been successful on fairly simplistic DGAs, many of which produce names of fixed length. However, models trained on limited datasets are somewhat blind to new DGA variants. In this paper, we leverage the concept of generative adversarial networks to construct a deep learning based DGA that is designed to intentionally bypass a deep learning based detector. In a series of adversarial rounds, the generator learns to generate domain names that are increasingly more difficult to detect. In turn, a detector model updates its parameters to compensate for the adversarially generated domains. We test the hypothesis of whether adversarially generated domains may be used to augment training sets in order to harden other machine learning models against yet-to-be-observed DGAs. We detail solutions to several challenges in training this character-based generative adversarial network (GAN). In particular, our deep learning architecture begins as a domain name auto-encoder (encoder + decoder) trained on domains in the Alexa one million. Then the encoder and decoder are reassembled competitively in a generative adversarial network (detector + generator), with novel neural architectures and training strategies to improve convergence.