 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Yara Rule Generation Using Biclustering
Sep 06, 2020

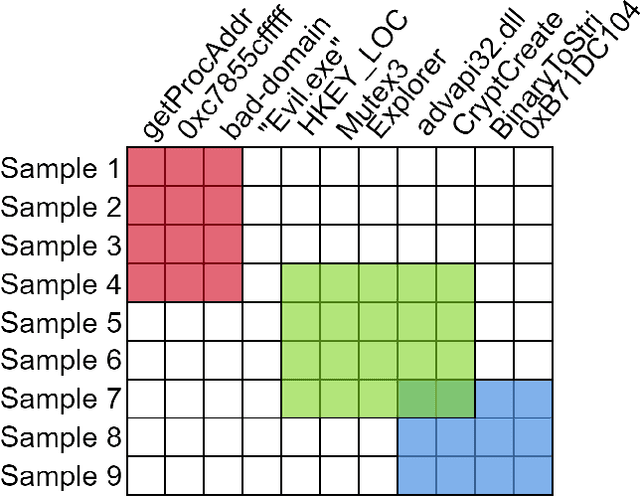

Yara rules are a ubiquitous tool among cybersecurity practitioners and analysts. Developing high-quality Yara rules to detect a malware family of interest can be labor- and time-intensive, even for expert users. Few tools exist and relatively little work has been done on how to automate the generation of Yara rules for specific families. In this paper, we leverage large n-grams ($n \geq 8$) combined with a new biclustering algorithm to construct simple Yara rules more effectively than currently available software. Our method, AutoYara, is fast, allowing for deployment on low-resource equipment for teams that deploy to remote networks. Our results demonstrate that AutoYara can help reduce analyst workload by producing rules with useful true-positive rates while maintaining low false-positive rates, sometimes matching or even outperforming human analysts. In addition, real-world testing by malware analysts indicates AutoYara could reduce analyst time spent constructing Yara rules by 44-86%, allowing them to spend their time on the more advanced malware that current tools can't handle. Code will be made available at https://github.com/NeuromorphicComputationResearchProgram .
KiloGrams: Very Large N-Grams for Malware Classification
Aug 01, 2019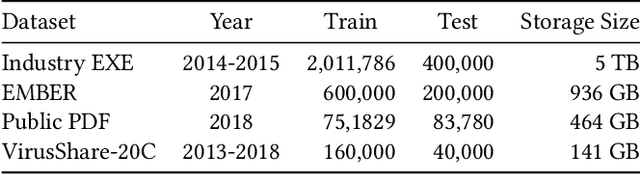
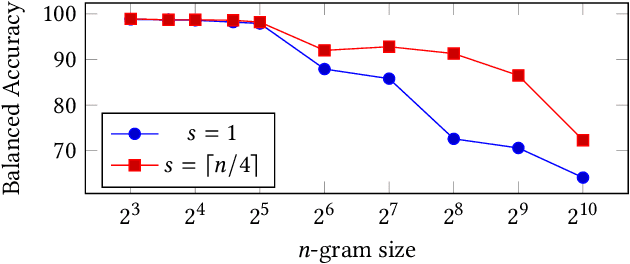
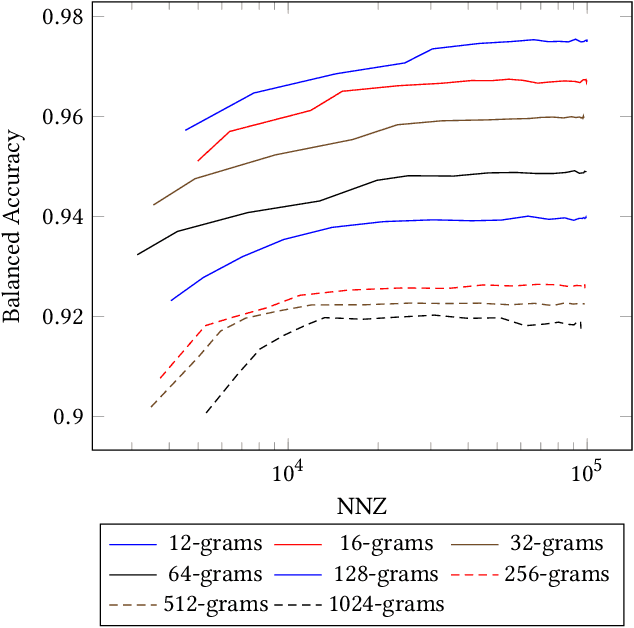
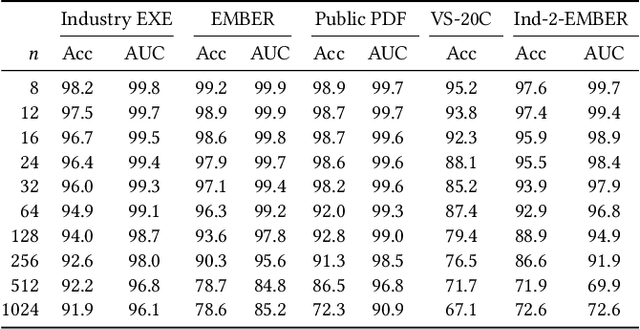
N-grams have been a common tool for information retrieval and machine learning applications for decades. In nearly all previous works, only a few values of $n$ are tested, with $n > 6$ being exceedingly rare. Larger values of $n$ are not tested due to computational burden or the fear of overfitting. In this work, we present a method to find the top-$k$ most frequent $n$-grams that is 60$\times$ faster for small $n$, and can tackle large $n\geq1024$. Despite the unprecedented size of $n$ considered, we show how these features still have predictive ability for malware classification tasks. More important, large $n$-grams provide benefits in producing features that are interpretable by malware analysis, and can be used to create general purpose signatures compatible with industry standard tools like Yara. Furthermore, the counts of common $n$-grams in a file may be added as features to publicly available human-engineered features that rival efficacy of professionally-developed features when used to train gradient-boosted decision tree models on the EMBER dataset.