 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplied Federated Learning: Architectural Design for Robust and Efficient Learning in Privacy Aware Settings
Jun 07, 2022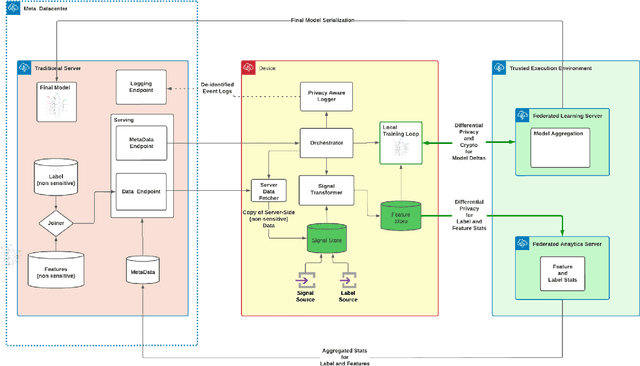
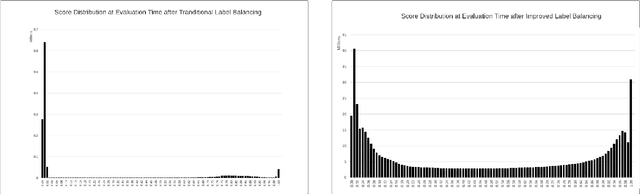
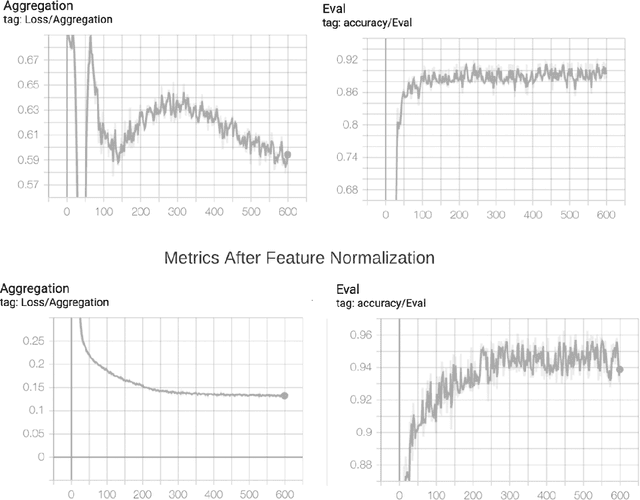
The classical machine learning paradigm requires the aggregation of user data in a central location where machine learning practitioners can preprocess data, calculate features, tune models and evaluate performance. The advantage of this approach includes leveraging high performance hardware (such as GPUs) and the ability of machine learning practitioners to do in depth data analysis to improve model performance. However, these advantages may come at a cost to data privacy. User data is collected, aggregated, and stored on centralized servers for model development. Centralization of data poses risks, including a heightened risk of internal and external security incidents as well as accidental data misuse. Federated learning with differential privacy is designed to avoid the server-side centralization pitfall by bringing the ML learning step to users' devices. Learning is done in a federated manner where each mobile device runs a training loop on a local copy of a model. Updates from on-device models are sent to the server via encrypted communication and through differential privacy to improve the global model. In this paradigm, users' personal data remains on their devices. Surprisingly, model training in this manner comes at a fairly minimal degradation in model performance. However, federated learning comes with many other challenges due to its distributed nature, heterogeneous compute environments and lack of data visibility. This paper explores those challenges and outlines an architectural design solution we are exploring and testing to productionize federated learning at Meta scale.
Predicting Domain Generation Algorithms with Long Short-Term Memory Networks
Nov 02, 2016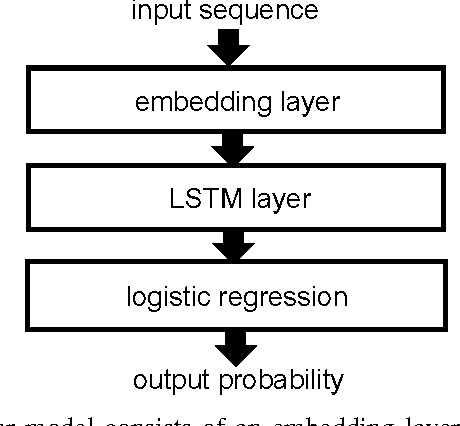
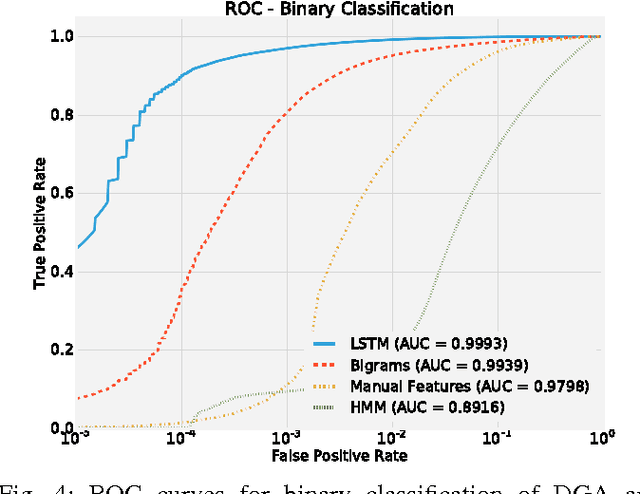


Various families of malware use domain generation algorithms (DGAs) to generate a large number of pseudo-random domain names to connect to a command and control (C&C) server. In order to block DGA C&C traffic, security organizations must first discover the algorithm by reverse engineering malware samples, then generating a list of domains for a given seed. The domains are then either preregistered or published in a DNS blacklist. This process is not only tedious, but can be readily circumvented by malware authors using a large number of seeds in algorithms with multivariate recurrence properties (e.g., banjori) or by using a dynamic list of seeds (e.g., bedep). Another technique to stop malware from using DGAs is to intercept DNS queries on a network and predict whether domains are DGA generated. Such a technique will alert network administrators to the presence of malware on their networks. In addition, if the predictor can also accurately predict the family of DGAs, then network administrators can also be alerted to the type of malware that is on their networks. This paper presents a DGA classifier that leverages long short-term memory (LSTM) networks to predict DGAs and their respective families without the need for a priori feature extraction. Results are significantly better than state-of-the-art techniques, providing 0.9993 area under the receiver operating characteristic curve for binary classification and a micro-averaged F1 score of 0.9906. In other terms, the LSTM technique can provide a 90% detection rate with a 1:10000 false positive (FP) rate---a twenty times FP improvement over comparable methods. Experiments in this paper are run on open datasets and code snippets are provided to reproduce the results.
DeepDGA: Adversarially-Tuned Domain Generation and Detection
Oct 06, 2016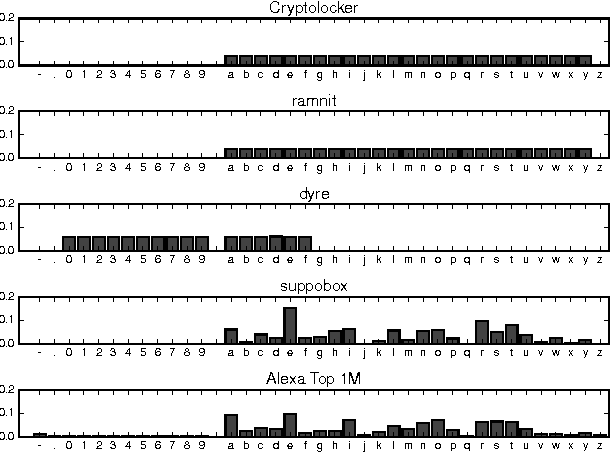
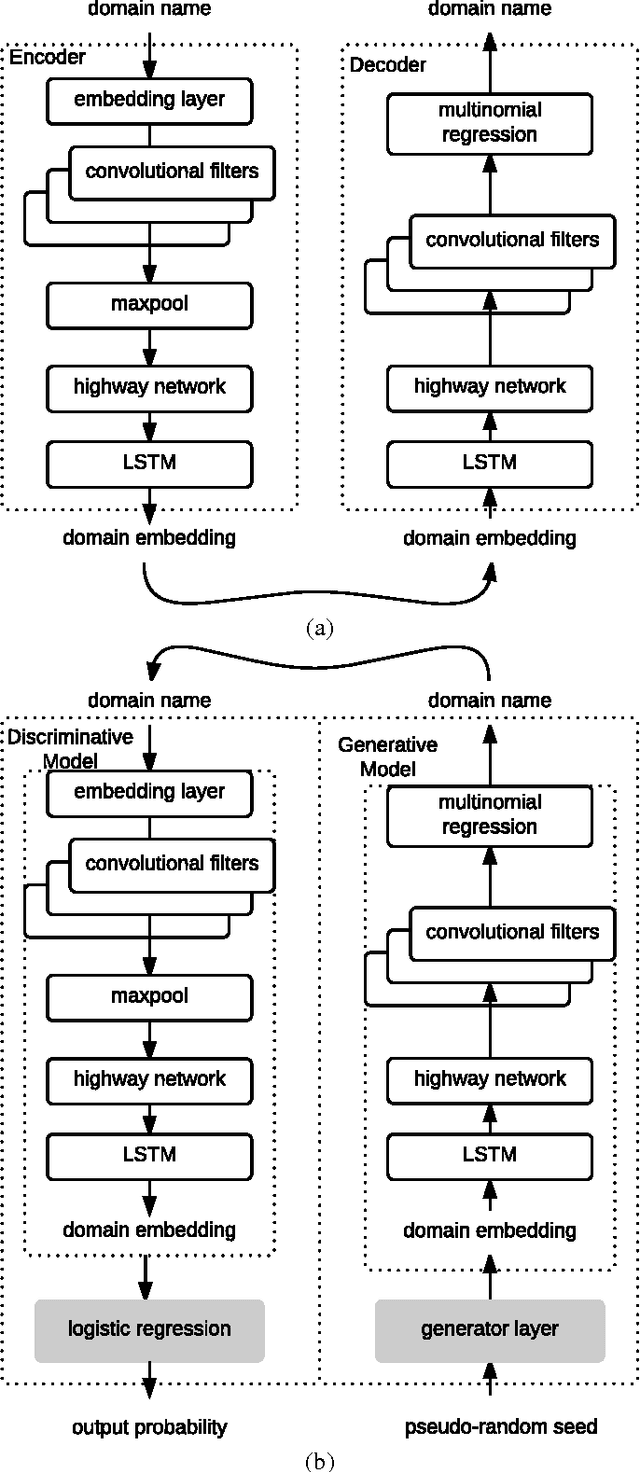
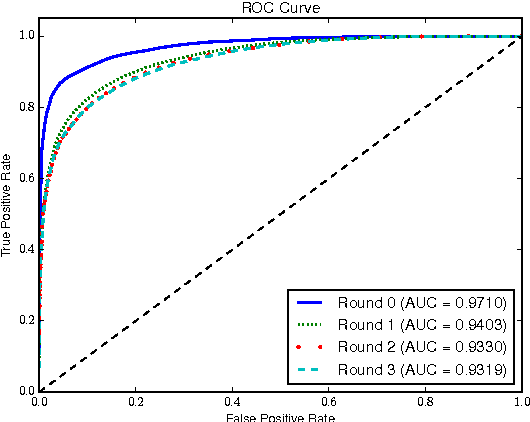
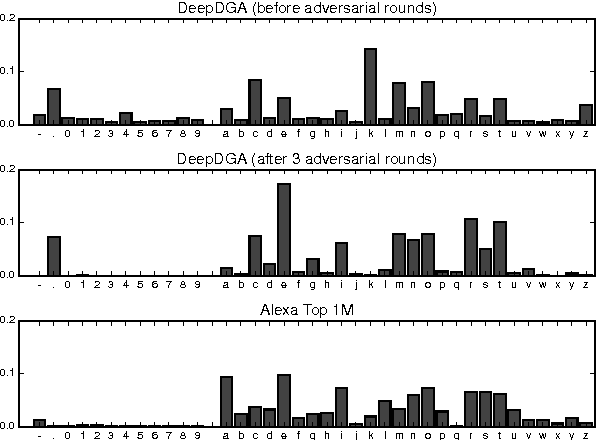
Many malware families utilize domain generation algorithms (DGAs) to establish command and control (C&C) connections. While there are many methods to pseudorandomly generate domains, we focus in this paper on detecting (and generating) domains on a per-domain basis which provides a simple and flexible means to detect known DGA families. Recent machine learning approaches to DGA detection have been successful on fairly simplistic DGAs, many of which produce names of fixed length. However, models trained on limited datasets are somewhat blind to new DGA variants. In this paper, we leverage the concept of generative adversarial networks to construct a deep learning based DGA that is designed to intentionally bypass a deep learning based detector. In a series of adversarial rounds, the generator learns to generate domain names that are increasingly more difficult to detect. In turn, a detector model updates its parameters to compensate for the adversarially generated domains. We test the hypothesis of whether adversarially generated domains may be used to augment training sets in order to harden other machine learning models against yet-to-be-observed DGAs. We detail solutions to several challenges in training this character-based generative adversarial network (GAN). In particular, our deep learning architecture begins as a domain name auto-encoder (encoder + decoder) trained on domains in the Alexa one million. Then the encoder and decoder are reassembled competitively in a generative adversarial network (detector + generator), with novel neural architectures and training strategies to improve convergence.