 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Hidden Pivotal Players with GoalNet: A GNN-Based Soccer Player Evaluation System
Mar 12, 2025Soccer analysis tools emphasize metrics such as expected goals, leading to an overrepresentation of attacking players' contributions and overlooking players who facilitate ball control and link attacks. Examples include Rodri from Manchester City and Palhinha who just transferred to Bayern Munich. To address this bias, we aim to identify players with pivotal roles in a soccer team, incorporating both spatial and temporal features. In this work, we introduce a GNN-based framework that assigns individual credit for changes in expected threat (xT), thus capturing overlooked yet vital contributions in soccer. Our pipeline encodes both spatial and temporal features in event-centric graphs, enabling fair attribution of non-scoring actions such as defensive or transitional plays. We incorporate centrality measures into the learned player embeddings, ensuring that ball-retaining defenders and defensive midfielders receive due recognition for their overall impact. Furthermore, we explore diverse GNN variants-including Graph Attention Networks and Transformer-based models-to handle long-range dependencies and evolving match contexts, discussing their relative performance and computational complexity. Experiments on real match data confirm the robustness of our approach in highlighting pivotal roles that traditional attacking metrics typically miss, underscoring the model's utility for more comprehensive soccer analytics.
Applied Federated Learning: Architectural Design for Robust and Efficient Learning in Privacy Aware Settings
Jun 07, 2022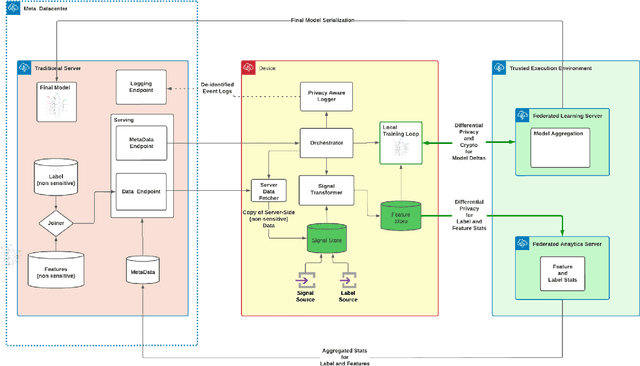
The classical machine learning paradigm requires the aggregation of user data in a central location where machine learning practitioners can preprocess data, calculate features, tune models and evaluate performance. The advantage of this approach includes leveraging high performance hardware (such as GPUs) and the ability of machine learning practitioners to do in depth data analysis to improve model performance. However, these advantages may come at a cost to data privacy. User data is collected, aggregated, and stored on centralized servers for model development. Centralization of data poses risks, including a heightened risk of internal and external security incidents as well as accidental data misuse. Federated learning with differential privacy is designed to avoid the server-side centralization pitfall by bringing the ML learning step to users' devices. Learning is done in a federated manner where each mobile device runs a training loop on a local copy of a model. Updates from on-device models are sent to the server via encrypted communication and through differential privacy to improve the global model. In this paradigm, users' personal data remains on their devices. Surprisingly, model training in this manner comes at a fairly minimal degradation in model performance. However, federated learning comes with many other challenges due to its distributed nature, heterogeneous compute environments and lack of data visibility. This paper explores those challenges and outlines an architectural design solution we are exploring and testing to productionize federated learning at Meta scale.