 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA synthetic data approach for domain generalization of NLI models
Feb 19, 2024
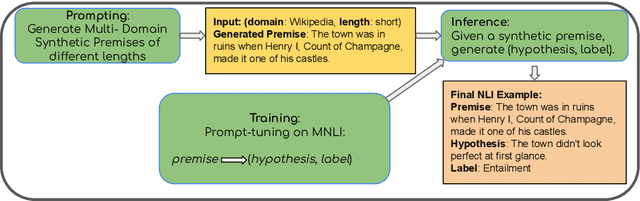


Natural Language Inference (NLI) remains an important benchmark task for LLMs. NLI datasets are a springboard for transfer learning to other semantic tasks, and NLI models are standard tools for identifying the faithfulness of model-generated text. There are several large scale NLI datasets today, and models have improved greatly by hill-climbing on these collections. Yet their realistic performance on out-of-distribution/domain data is less well-understood. We present an in-depth exploration of the problem of domain generalization of NLI models. We demonstrate a new approach for generating synthetic NLI data in diverse domains and lengths, so far not covered by existing training sets. The resulting examples have meaningful premises, the hypotheses are formed in creative ways rather than simple edits to a few premise tokens, and the labels have high accuracy. We show that models trained on this data ($685$K synthetic examples) have the best generalization to completely new downstream test settings. On the TRUE benchmark, a T5-small model trained with our data improves around $7\%$ on average compared to training on the best alternative dataset. The improvements are more pronounced for smaller models, while still meaningful on a T5 XXL model. We also demonstrate gains on test sets when in-domain training data is augmented with our domain-general synthetic data.
Measuring the Impact of Explanation Bias: A Study of Natural Language Justifications for Recommender Systems
Mar 16, 2023Despite the potential impact of explanations on decision making, there is a lack of research on quantifying their effect on users' choices. This paper presents an experimental protocol for measuring the degree to which positively or negatively biased explanations can lead to users choosing suboptimal recommendations. Key elements of this protocol include a preference elicitation stage to allow for personalizing recommendations, manual identification and extraction of item aspects from reviews, and a controlled method for introducing bias through the combination of both positive and negative aspects. We study explanations in two different textual formats: as a list of item aspects and as fluent natural language text. Through a user study with 129 participants, we demonstrate that explanations can significantly affect users' selections and that these findings generalize across explanation formats.
Applied Federated Learning: Architectural Design for Robust and Efficient Learning in Privacy Aware Settings
Jun 07, 2022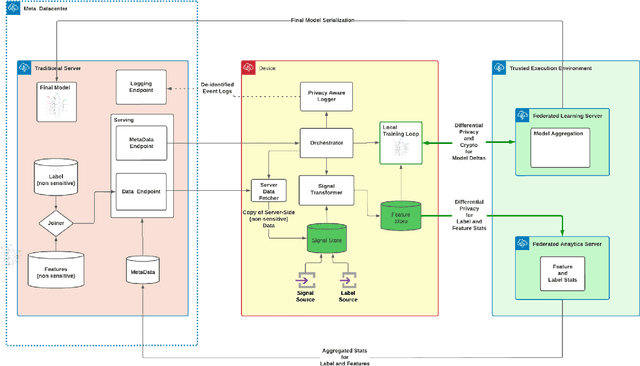
The classical machine learning paradigm requires the aggregation of user data in a central location where machine learning practitioners can preprocess data, calculate features, tune models and evaluate performance. The advantage of this approach includes leveraging high performance hardware (such as GPUs) and the ability of machine learning practitioners to do in depth data analysis to improve model performance. However, these advantages may come at a cost to data privacy. User data is collected, aggregated, and stored on centralized servers for model development. Centralization of data poses risks, including a heightened risk of internal and external security incidents as well as accidental data misuse. Federated learning with differential privacy is designed to avoid the server-side centralization pitfall by bringing the ML learning step to users' devices. Learning is done in a federated manner where each mobile device runs a training loop on a local copy of a model. Updates from on-device models are sent to the server via encrypted communication and through differential privacy to improve the global model. In this paradigm, users' personal data remains on their devices. Surprisingly, model training in this manner comes at a fairly minimal degradation in model performance. However, federated learning comes with many other challenges due to its distributed nature, heterogeneous compute environments and lack of data visibility. This paper explores those challenges and outlines an architectural design solution we are exploring and testing to productionize federated learning at Meta scale.