 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA synthetic data approach for domain generalization of NLI models
Paper and Code
Feb 19, 2024
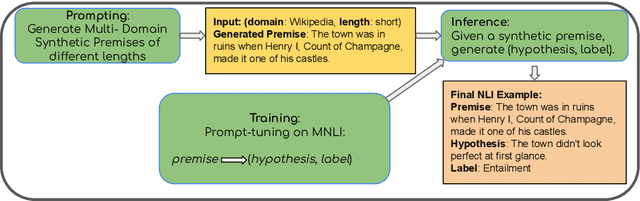


Natural Language Inference (NLI) remains an important benchmark task for LLMs. NLI datasets are a springboard for transfer learning to other semantic tasks, and NLI models are standard tools for identifying the faithfulness of model-generated text. There are several large scale NLI datasets today, and models have improved greatly by hill-climbing on these collections. Yet their realistic performance on out-of-distribution/domain data is less well-understood. We present an in-depth exploration of the problem of domain generalization of NLI models. We demonstrate a new approach for generating synthetic NLI data in diverse domains and lengths, so far not covered by existing training sets. The resulting examples have meaningful premises, the hypotheses are formed in creative ways rather than simple edits to a few premise tokens, and the labels have high accuracy. We show that models trained on this data ($685$K synthetic examples) have the best generalization to completely new downstream test settings. On the TRUE benchmark, a T5-small model trained with our data improves around $7\%$ on average compared to training on the best alternative dataset. The improvements are more pronounced for smaller models, while still meaningful on a T5 XXL model. We also demonstrate gains on test sets when in-domain training data is augmented with our domain-general synthetic data.