 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
A synthetic data approach for domain generalization of NLI models
Feb 19, 2024
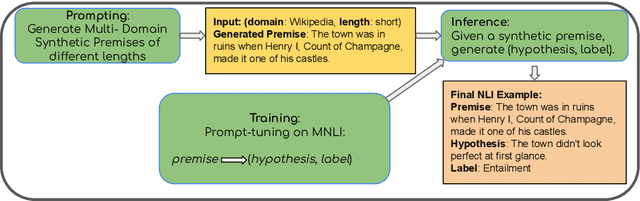


Natural Language Inference (NLI) remains an important benchmark task for LLMs. NLI datasets are a springboard for transfer learning to other semantic tasks, and NLI models are standard tools for identifying the faithfulness of model-generated text. There are several large scale NLI datasets today, and models have improved greatly by hill-climbing on these collections. Yet their realistic performance on out-of-distribution/domain data is less well-understood. We present an in-depth exploration of the problem of domain generalization of NLI models. We demonstrate a new approach for generating synthetic NLI data in diverse domains and lengths, so far not covered by existing training sets. The resulting examples have meaningful premises, the hypotheses are formed in creative ways rather than simple edits to a few premise tokens, and the labels have high accuracy. We show that models trained on this data ($685$K synthetic examples) have the best generalization to completely new downstream test settings. On the TRUE benchmark, a T5-small model trained with our data improves around $7\%$ on average compared to training on the best alternative dataset. The improvements are more pronounced for smaller models, while still meaningful on a T5 XXL model. We also demonstrate gains on test sets when in-domain training data is augmented with our domain-general synthetic data.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
LAIT: Efficient Multi-Segment Encoding in Transformers with Layer-Adjustable Interaction
May 31, 2023



Transformer encoders contextualize token representations by attending to all other tokens at each layer, leading to quadratic increase in compute effort with the input length. In practice, however, the input text of many NLP tasks can be seen as a sequence of related segments (e.g., the sequence of sentences within a passage, or the hypothesis and premise in NLI). While attending across these segments is highly beneficial for many tasks, we hypothesize that this interaction can be delayed until later encoding stages. To this end, we introduce Layer-Adjustable Interactions in Transformers (LAIT). Within LAIT, segmented inputs are first encoded independently, and then jointly. This partial two-tower architecture bridges the gap between a Dual Encoder's ability to pre-compute representations for segments and a fully self-attentive Transformer's capacity to model cross-segment attention. The LAIT framework effectively leverages existing pretrained Transformers and converts them into the hybrid of the two aforementioned architectures, allowing for easy and intuitive control over the performance-efficiency tradeoff. Experimenting on a wide range of NLP tasks, we find LAIT able to reduce 30-50% of the attention FLOPs on many tasks, while preserving high accuracy; in some practical settings, LAIT could reduce actual latency by orders of magnitude.
Text-Blueprint: An Interactive Platform for Plan-based Conditional Generation
Apr 28, 2023While conditional generation models can now generate natural language well enough to create fluent text, it is still difficult to control the generation process, leading to irrelevant, repetitive, and hallucinated content. Recent work shows that planning can be a useful intermediate step to render conditional generation less opaque and more grounded. We present a web browser-based demonstration for query-focused summarization that uses a sequence of question-answer pairs, as a blueprint plan for guiding text generation (i.e., what to say and in what order). We illustrate how users may interact with the generated text and associated plan visualizations, e.g., by editing and modifying the blueprint in order to improve or control the generated output. A short video demonstrating our system is available at https://goo.gle/text-blueprint-demo.
OpineSum: Entailment-based self-training for abstractive opinion summarization
Dec 21, 2022A typical product or place often has hundreds of reviews, and summarization of these texts is an important and challenging problem. Recent progress on abstractive summarization in domains such as news has been driven by supervised systems trained on hundreds of thousands of news articles paired with human-written summaries. However for opinion texts, such large scale datasets are rarely available. Unsupervised methods, self-training, and few-shot learning approaches bridge that gap. In this work, we present a novel self-training approach, OpineSum, for abstractive opinion summarization. The summaries in this approach are built using a novel application of textual entailment and capture the consensus of opinions across the various reviews for an item. This method can be used to obtain silver-standard summaries on a large scale and train both unsupervised and few-shot abstractive summarization systems. OpineSum achieves state-of-the-art performance in both settings.
Resolving Indirect Referring Expressions for Entity Selection
Dec 21, 2022Recent advances in language modeling have enabled new conversational systems. In particular, it is often desirable for people to make choices among specified options when using such systems. We address the problem of reference resolution, when people use natural expressions to choose between real world entities. For example, given the choice `Should we make a Simnel cake or a Pandan cake?' a natural response from a non-expert may be indirect: `let's make the green one'. Reference resolution has been little studied with natural expressions, thus robustly understanding such language has large potential for improving naturalness in dialog, recommendation, and search systems. We create AltEntities (Alternative Entities), a new public dataset of entity pairs and utterances, and develop models for the disambiguation problem. Consisting of 42K indirect referring expressions across three domains, it enables for the first time the study of how large language models can be adapted to this task. We find they achieve 82%-87% accuracy in realistic settings, which while reasonable also invites further advances.
Little Red Riding Hood Goes Around the Globe:Crosslingual Story Planning and Generation with Large Language Models
Dec 20, 2022



We consider the problem of automatically generating stories in multiple languages. Compared to prior work in monolingual story generation, crosslingual story generation allows for more universal research on story planning. We propose to use Prompting Large Language Models with Plans to study which plan is optimal for story generation. We consider 4 types of plans and systematically analyse how the outputs differ for different planning strategies. The study demonstrates that formulating the plans as question-answer pairs leads to more coherent generated stories while the plan gives more control to the story creators.
Conditional Generation with a Question-Answering Blueprint
Jul 01, 2022
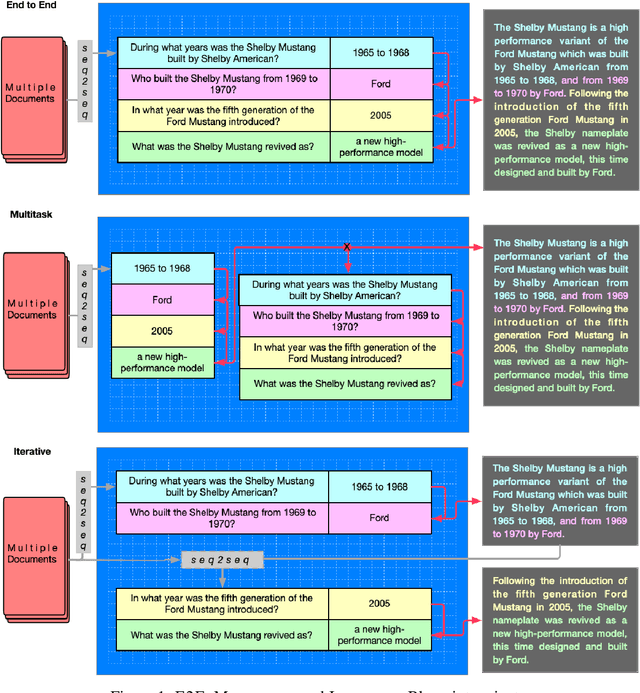
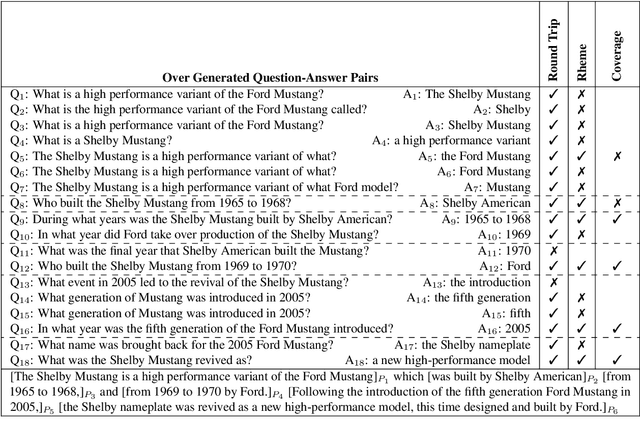
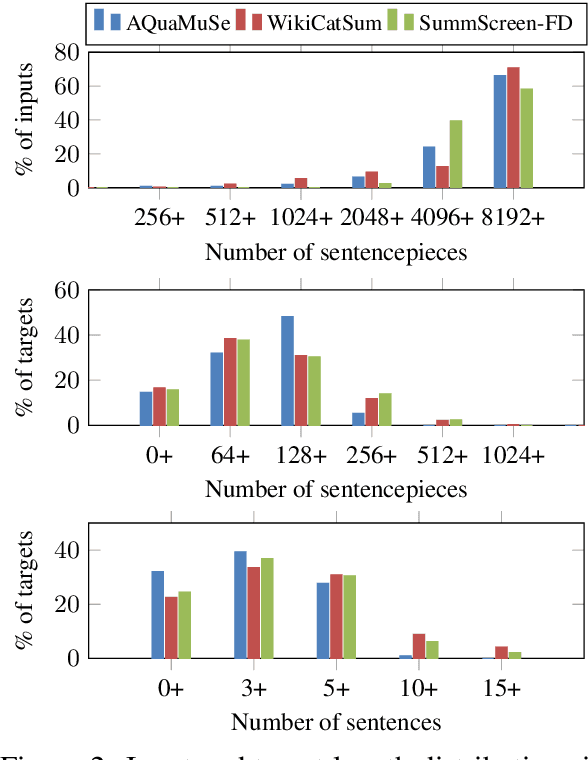
The ability to convey relevant and faithful information is critical for many tasks in conditional generation and yet remains elusive for neural seq-to-seq models whose outputs often reveal hallucinations and fail to correctly cover important details. In this work, we advocate planning as a useful intermediate representation for rendering conditional generation less opaque and more grounded. Our work proposes a new conceptualization of text plans as a sequence of question-answer (QA) pairs. We enhance existing datasets (e.g., for summarization) with a QA blueprint operating as a proxy for both content selection (i.e.,~what to say) and planning (i.e.,~in what order). We obtain blueprints automatically by exploiting state-of-the-art question generation technology and convert input-output pairs into input-blueprint-output tuples. We develop Transformer-based models, each varying in how they incorporate the blueprint in the generated output (e.g., as a global plan or iteratively). Evaluation across metrics and datasets demonstrates that blueprint models are more factual than alternatives which do not resort to planning and allow tighter control of the generation output.
"I'd rather just go to bed": Understanding Indirect Answers
Oct 07, 2020



We revisit a pragmatic inference problem in dialog: understanding indirect responses to questions. Humans can interpret 'I'm starving.' in response to 'Hungry?', even without direct cue words such as 'yes' and 'no'. In dialog systems, allowing natural responses rather than closed vocabularies would be similarly beneficial. However, today's systems are only as sensitive to these pragmatic moves as their language model allows. We create and release the first large-scale English language corpus 'Circa' with 34,268 (polar question, indirect answer) pairs to enable progress on this task. The data was collected via elaborate crowdsourcing, and contains utterances with yes/no meaning, as well as uncertain, middle-ground, and conditional responses. We also present BERT-based neural models to predict such categories for a question-answer pair. We find that while transfer learning from entailment works reasonably, performance is not yet sufficient for robust dialog. Our models reach 82-88% accuracy for a 4-class distinction, and 74-85% for 6 classes.