 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Adapting Large Language Models for Few-Shot Multilingual NLU: Are We There Yet?
Mar 04, 2024Supervised fine-tuning (SFT), supervised instruction tuning (SIT) and in-context learning (ICL) are three alternative, de facto standard approaches to few-shot learning. ICL has gained popularity recently with the advent of LLMs due to its simplicity and sample efficiency. Prior research has conducted only limited investigation into how these approaches work for multilingual few-shot learning, and the focus so far has been mostly on their performance. In this work, we present an extensive and systematic comparison of the three approaches, testing them on 6 high- and low-resource languages, three different NLU tasks, and a myriad of language and domain setups. Importantly, performance is only one aspect of the comparison, where we also analyse the approaches through the optics of their computational, inference and financial costs. Our observations show that supervised instruction tuning has the best trade-off between performance and resource requirements. As another contribution, we analyse the impact of target language adaptation of pretrained LLMs and find that the standard adaptation approaches can (superficially) improve target language generation capabilities, but language understanding elicited through ICL does not improve and remains limited, with low scores especially for low-resource languages.
SQATIN: Supervised Instruction Tuning Meets Question Answering for Improved Dialogue NLU
Nov 16, 2023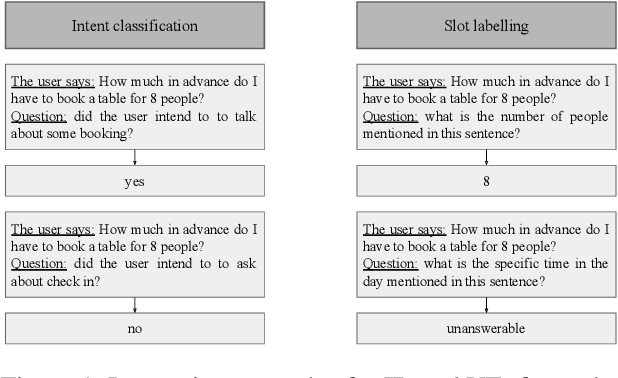
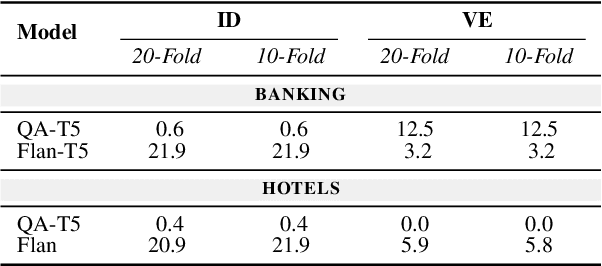
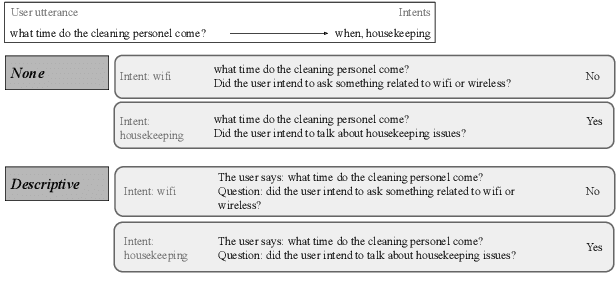
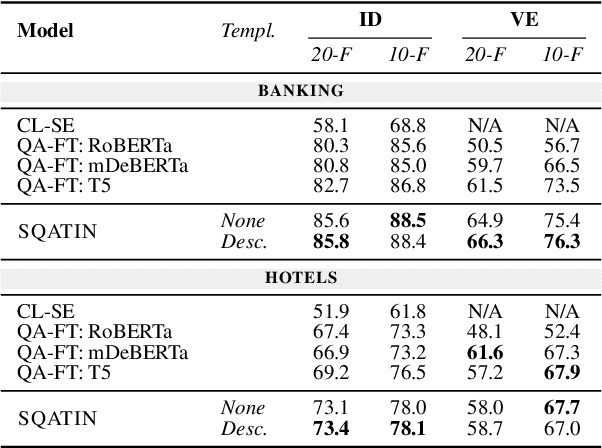
Task-oriented dialogue (ToD) systems help users execute well-defined tasks across a variety of domains (e.g., $\textit{flight booking}$ or $\textit{food ordering}$), with their Natural Language Understanding (NLU) components being dedicated to the analysis of user utterances, predicting users' intents ($\textit{Intent Detection}$, ID) and extracting values for informational slots ($\textit{Value Extraction}$, VE). In most domains, labelled NLU data is scarce, making sample-efficient learning -- enabled with effective transfer paradigms -- paramount. In this work, we introduce SQATIN, a new framework for dialog NLU based on (i) instruction tuning and (ii) question-answering-based formulation of ID and VE tasks. According to the evaluation on established NLU benchmarks, SQATIN sets the new state of the art in dialogue NLU, substantially surpassing the performance of current models based on standard fine-tuning objectives in both in-domain training and cross-domain transfer. SQATIN yields particularly large performance gains in cross-domain transfer, owing to the fact that our QA-based instruction tuning leverages similarities between natural language descriptions of classes (i.e., slots and intents) across domains.
$\textit{Dial BeInfo for Faithfulness}$: Improving Factuality of Information-Seeking Dialogue via Behavioural Fine-Tuning
Nov 16, 2023



Factuality is a crucial requirement in information seeking dialogue: the system should respond to the user's queries so that the responses are meaningful and aligned with the knowledge provided to the system. However, most modern large language models suffer from hallucinations, that is, they generate responses not supported by or contradicting the knowledge source. To mitigate the issue and increase faithfulness of information-seeking dialogue systems, we introduce BeInfo, a simple yet effective method that applies behavioural tuning to aid information-seeking dialogue. Relying on three standard datasets, we show that models tuned with BeInfo} become considerably more faithful to the knowledge source both for datasets and domains seen during BeInfo-tuning, as well as on unseen domains, when applied in a zero-shot manner. In addition, we show that the models with 3B parameters (e.g., Flan-T5) tuned with BeInfo demonstrate strong performance on data from real `production' conversations and outperform GPT4 when tuned on a limited amount of such realistic in-domain dialogues.
Transfer-Free Data-Efficient Multilingual Slot Labeling
May 22, 2023



Slot labeling (SL) is a core component of task-oriented dialogue (ToD) systems, where slots and corresponding values are usually language-, task- and domain-specific. Therefore, extending the system to any new language-domain-task configuration requires (re)running an expensive and resource-intensive data annotation process. To mitigate the inherent data scarcity issue, current research on multilingual ToD assumes that sufficient English-language annotated data are always available for particular tasks and domains, and thus operates in a standard cross-lingual transfer setup. In this work, we depart from this often unrealistic assumption. We examine challenging scenarios where such transfer-enabling English annotated data cannot be guaranteed, and focus on bootstrapping multilingual data-efficient slot labelers in transfer-free scenarios directly in the target languages without any English-ready data. We propose a two-stage slot labeling approach (termed TWOSL) which transforms standard multilingual sentence encoders into effective slot labelers. In Stage 1, relying on SL-adapted contrastive learning with only a handful of SL-annotated examples, we turn sentence encoders into task-specific span encoders. In Stage 2, we recast SL from a token classification into a simpler, less data-intensive span classification task. Our results on two standard multilingual TOD datasets and across diverse languages confirm the effectiveness and robustness of TWOSL. It is especially effective for the most challenging transfer-free few-shot setups, paving the way for quick and data-efficient bootstrapping of multilingual slot labelers for ToD.
MULTI3NLU++: A Multilingual, Multi-Intent, Multi-Domain Dataset for Natural Language Understanding in Task-Oriented Dialogue
Dec 20, 2022



Task-oriented dialogue (TOD) systems have been applied in a range of domains to support human users to achieve specific goals. Systems are typically constructed for a single domain or language and do not generalise well beyond this. Their extension to other languages in particular is restricted by the lack of available training data for many of the world's languages. To support work on Natural Language Understanding (NLU) in TOD across multiple languages and domains simultaneously, we constructed MULTI3NLU++, a multilingual, multi-intent, multi-domain dataset. MULTI3NLU++ extends the English-only NLU++ dataset to include manual translations into a range of high, medium and low resource languages (Spanish, Marathi, Turkish and Amharic), in two domains (banking and hotels). MULTI3NLU++ inherits the multi-intent property of NLU++, where an utterance may be labelled with multiple intents, providing a more realistic representation of a user's goals and aligning with the more complex tasks that commercial systems aim to model. We use MULTI3NLU++ to benchmark state-of-the-art multilingual language models as well as Machine Translation and Question Answering systems for the NLU task of intent detection for TOD systems in the multilingual setting. The results demonstrate the challenging nature of the dataset, particularly in the low-resource language setting.
Little Red Riding Hood Goes Around the Globe:Crosslingual Story Planning and Generation with Large Language Models
Dec 20, 2022



We consider the problem of automatically generating stories in multiple languages. Compared to prior work in monolingual story generation, crosslingual story generation allows for more universal research on story planning. We propose to use Prompting Large Language Models with Plans to study which plan is optimal for story generation. We consider 4 types of plans and systematically analyse how the outputs differ for different planning strategies. The study demonstrates that formulating the plans as question-answer pairs leads to more coherent generated stories while the plan gives more control to the story creators.
Cross-Lingual Dialogue Dataset Creation via Outline-Based Generation
Jan 31, 2022Multilingual task-oriented dialogue (ToD) facilitates access to services and information for many (communities of) speakers. Nevertheless, the potential of this technology is not fully realised, as current datasets for multilingual ToD - both for modular and end-to-end modelling - suffer from severe limitations. 1) When created from scratch, they are usually small in scale and fail to cover many possible dialogue flows. 2) Translation-based ToD datasets might lack naturalness and cultural specificity in the target language. In this work, to tackle these limitations we propose a novel outline-based annotation process for multilingual ToD datasets, where domain-specific abstract schemata of dialogue are mapped into natural language outlines. These in turn guide the target language annotators in writing a dialogue by providing instructions about each turn's intents and slots. Through this process we annotate a new large-scale dataset for training and evaluation of multilingual and cross-lingual ToD systems. Our Cross-lingual Outline-based Dialogue dataset (termed COD) enables natural language understanding, dialogue state tracking, and end-to-end dialogue modelling and evaluation in 4 diverse languages: Arabic, Indonesian, Russian, and Kiswahili. Qualitative and quantitative analyses of COD versus an equivalent translation-based dataset demonstrate improvements in data quality, unlocked by the outline-based approach. Finally, we benchmark a series of state-of-the-art systems for cross-lingual ToD, setting reference scores for future work and demonstrating that COD prevents over-inflated performance, typically met with prior translation-based ToD datasets.
Crossing the Conversational Chasm: A Primer on Multilingual Task-Oriented Dialogue Systems
Apr 17, 2021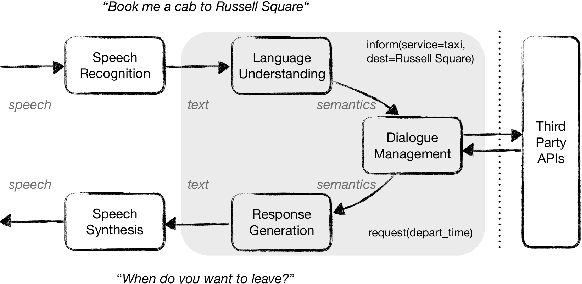
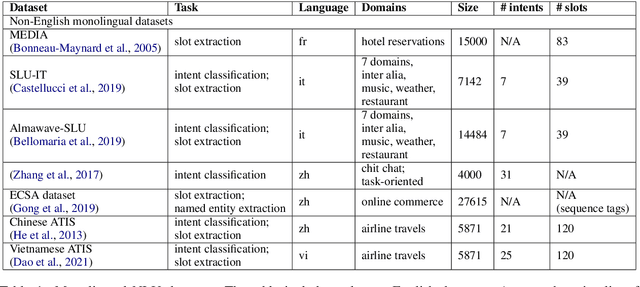

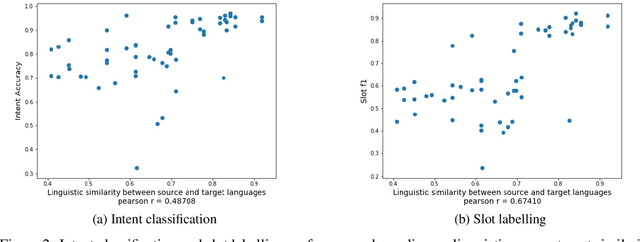
Despite the fact that natural language conversations with machines represent one of the central objectives of AI, and despite the massive increase of research and development efforts in conversational AI, task-oriented dialogue (ToD) -- i.e., conversations with an artificial agent with the aim of completing a concrete task -- is currently limited to a few narrow domains (e.g., food ordering, ticket booking) and a handful of major languages (e.g., English, Chinese). In this work, we provide an extensive overview of existing efforts in multilingual ToD and analyse the factors preventing the development of truly multilingual ToD systems. We identify two main challenges that combined hinder the faster progress in multilingual ToD: (1) current state-of-the-art ToD models based on large pretrained neural language models are data hungry; at the same time (2) data acquisition for ToD use cases is expensive and tedious. Most existing approaches to multilingual ToD thus rely on (zero- or few-shot) cross-lingual transfer from resource-rich languages (in ToD, this is basically only English), either by means of (i) machine translation or (ii) multilingual representation spaces. However, such approaches are currently not a viable solution for a large number of low-resource languages without parallel data and/or limited monolingual corpora. Finally, we discuss critical challenges and potential solutions by drawing parallels between ToD and other cross-lingual and multilingual NLP research.
Pretraining Methods for Dialog Context Representation Learning
Jun 04, 2019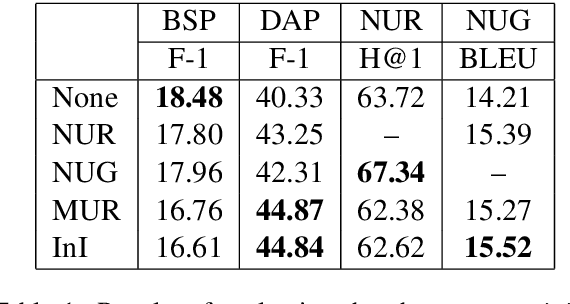

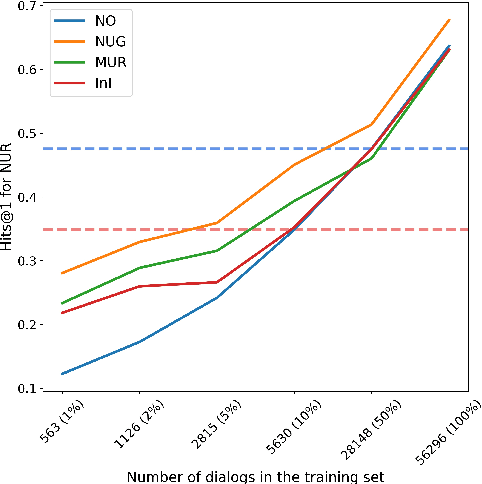
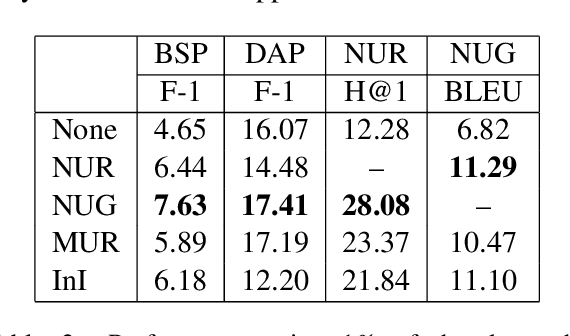
This paper examines various unsupervised pretraining objectives for learning dialog context representations. Two novel methods of pretraining dialog context encoders are proposed, and a total of four methods are examined. Each pretraining objective is fine-tuned and evaluated on a set of downstream dialog tasks using the MultiWoz dataset and strong performance improvement is observed. Further evaluation shows that our pretraining objectives result in not only better performance, but also better convergence, models that are less data hungry and have better domain generalizability.
Beyond Turing: Intelligent Agents Centered on the User
Jan 20, 2019
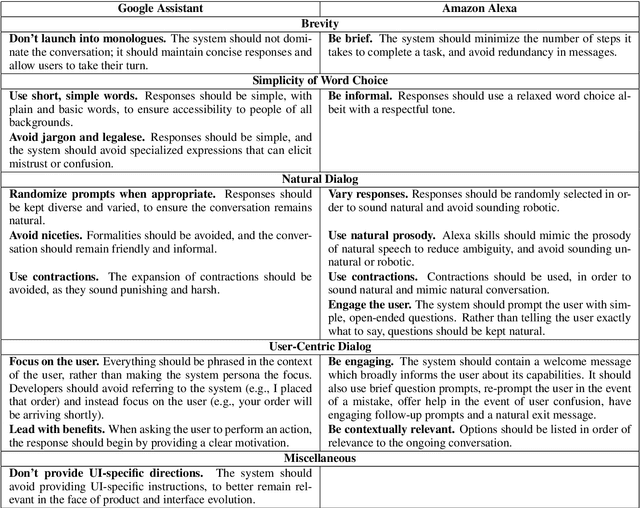


This paper makes the case that while most research on intelligent agents presently centers on the agent and not on the user, the opposite should be true. Covering slot-filling, gaming and chatbot agents, it looks at where the tendency to attend to the agent has come from and why it is important to concentrate more on the user. After reviewing relevant literature, we propose some first approaches to creating and assessing user-centric systems.