 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Dialogue Dataset Creation via Outline-Based Generation
Jan 31, 2022Multilingual task-oriented dialogue (ToD) facilitates access to services and information for many (communities of) speakers. Nevertheless, the potential of this technology is not fully realised, as current datasets for multilingual ToD - both for modular and end-to-end modelling - suffer from severe limitations. 1) When created from scratch, they are usually small in scale and fail to cover many possible dialogue flows. 2) Translation-based ToD datasets might lack naturalness and cultural specificity in the target language. In this work, to tackle these limitations we propose a novel outline-based annotation process for multilingual ToD datasets, where domain-specific abstract schemata of dialogue are mapped into natural language outlines. These in turn guide the target language annotators in writing a dialogue by providing instructions about each turn's intents and slots. Through this process we annotate a new large-scale dataset for training and evaluation of multilingual and cross-lingual ToD systems. Our Cross-lingual Outline-based Dialogue dataset (termed COD) enables natural language understanding, dialogue state tracking, and end-to-end dialogue modelling and evaluation in 4 diverse languages: Arabic, Indonesian, Russian, and Kiswahili. Qualitative and quantitative analyses of COD versus an equivalent translation-based dataset demonstrate improvements in data quality, unlocked by the outline-based approach. Finally, we benchmark a series of state-of-the-art systems for cross-lingual ToD, setting reference scores for future work and demonstrating that COD prevents over-inflated performance, typically met with prior translation-based ToD datasets.
Crossing the Conversational Chasm: A Primer on Multilingual Task-Oriented Dialogue Systems
Apr 17, 2021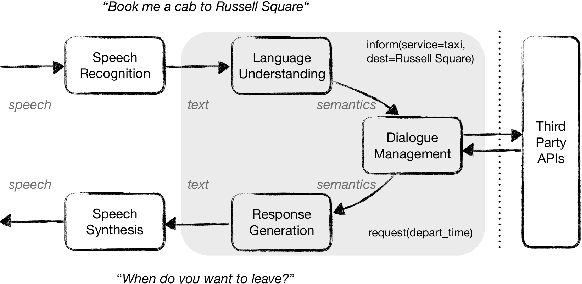
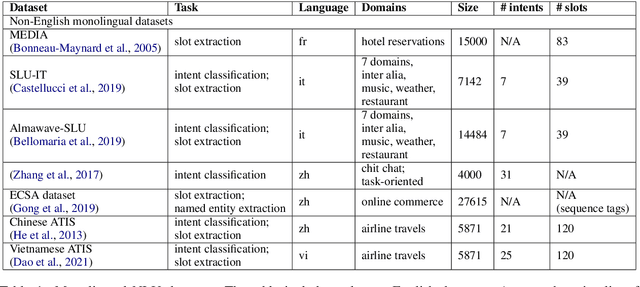

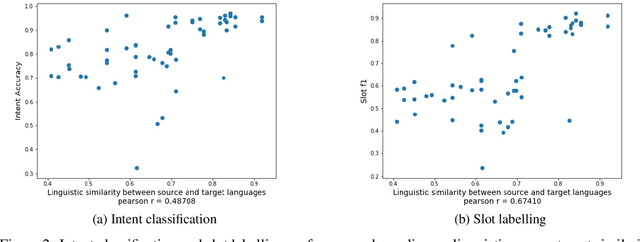
Despite the fact that natural language conversations with machines represent one of the central objectives of AI, and despite the massive increase of research and development efforts in conversational AI, task-oriented dialogue (ToD) -- i.e., conversations with an artificial agent with the aim of completing a concrete task -- is currently limited to a few narrow domains (e.g., food ordering, ticket booking) and a handful of major languages (e.g., English, Chinese). In this work, we provide an extensive overview of existing efforts in multilingual ToD and analyse the factors preventing the development of truly multilingual ToD systems. We identify two main challenges that combined hinder the faster progress in multilingual ToD: (1) current state-of-the-art ToD models based on large pretrained neural language models are data hungry; at the same time (2) data acquisition for ToD use cases is expensive and tedious. Most existing approaches to multilingual ToD thus rely on (zero- or few-shot) cross-lingual transfer from resource-rich languages (in ToD, this is basically only English), either by means of (i) machine translation or (ii) multilingual representation spaces. However, such approaches are currently not a viable solution for a large number of low-resource languages without parallel data and/or limited monolingual corpora. Finally, we discuss critical challenges and potential solutions by drawing parallels between ToD and other cross-lingual and multilingual NLP research.
Verb Knowledge Injection for Multilingual Event Processing
Dec 31, 2020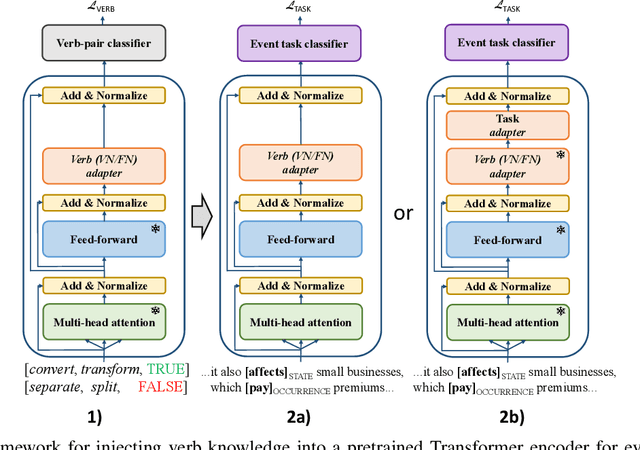



In parallel to their overwhelming success across NLP tasks, language ability of deep Transformer networks, pretrained via language modeling (LM) objectives has undergone extensive scrutiny. While probing revealed that these models encode a range of syntactic and semantic properties of a language, they are still prone to fall back on superficial cues and simple heuristics to solve downstream tasks, rather than leverage deeper linguistic knowledge. In this paper, we target one such area of their deficiency, verbal reasoning. We investigate whether injecting explicit information on verbs' semantic-syntactic behaviour improves the performance of LM-pretrained Transformers in event extraction tasks -- downstream tasks for which accurate verb processing is paramount. Concretely, we impart the verb knowledge from curated lexical resources into dedicated adapter modules (dubbed verb adapters), allowing it to complement, in downstream tasks, the language knowledge obtained during LM-pretraining. We first demonstrate that injecting verb knowledge leads to performance gains in English event extraction. We then explore the utility of verb adapters for event extraction in other languages: we investigate (1) zero-shot language transfer with multilingual Transformers as well as (2) transfer via (noisy automatic) translation of English verb-based lexical constraints. Our results show that the benefits of verb knowledge injection indeed extend to other languages, even when verb adapters are trained on noisily translated constraints.
Common Sense or World Knowledge? Investigating Adapter-Based Knowledge Injection into Pretrained Transformers
May 24, 2020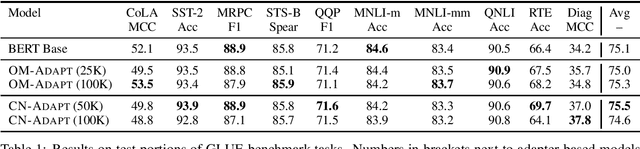
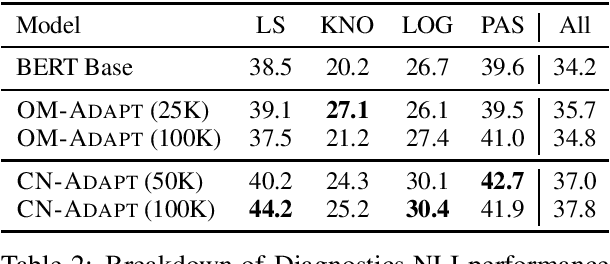
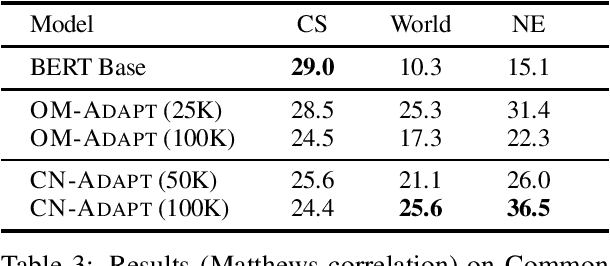
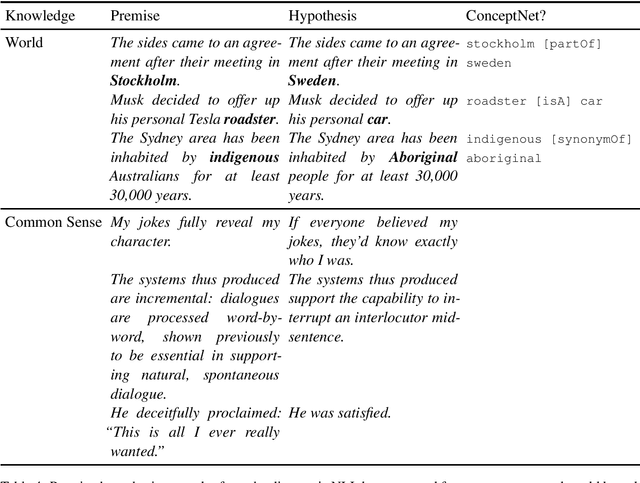
Following the major success of neural language models (LMs) such as BERT or GPT-2 on a variety of language understanding tasks, recent work focused on injecting (structured) knowledge from external resources into these models. While on the one hand, joint pretraining (i.e., training from scratch, adding objectives based on external knowledge to the primary LM objective) may be prohibitively computationally expensive, post-hoc fine-tuning on external knowledge, on the other hand, may lead to the catastrophic forgetting of distributional knowledge. In this work, we investigate models for complementing the distributional knowledge of BERT with conceptual knowledge from ConceptNet and its corresponding Open Mind Common Sense (OMCS) corpus, respectively, using adapter training. While overall results on the GLUE benchmark paint an inconclusive picture, a deeper analysis reveals that our adapter-based models substantially outperform BERT (up to 15-20 performance points) on inference tasks that require the type of conceptual knowledge explicitly present in ConceptNet and OMCS.
XCOPA: A Multilingual Dataset for Causal Commonsense Reasoning
May 01, 2020



In order to simulate human language capacity, natural language processing systems must complement the explicit information derived from raw text with the ability to reason about the possible causes and outcomes of everyday situations. Moreover, the acquired world knowledge should generalise to new languages, modulo cultural differences. Advances in machine commonsense reasoning and cross-lingual transfer depend on the availability of challenging evaluation benchmarks. Motivated by both demands, we introduce Cross-lingual Choice of Plausible Alternatives (XCOPA), a typologically diverse multilingual dataset for causal commonsense reasoning in 11 languages. We benchmark a range of state-of-the-art models on this novel dataset, revealing that current methods based on multilingual pretraining and zero-shot fine-tuning transfer suffer from the curse of multilinguality and fall short of performance in monolingual settings by a large margin. Finally, we propose ways to adapt these models to out-of-sample resource-lean languages where only a small corpus or a bilingual dictionary is available, and report substantial improvements over the random baseline. XCOPA is available at github.com/cambridgeltl/xcopa.
Multi-SimLex: A Large-Scale Evaluation of Multilingual and Cross-Lingual Lexical Semantic Similarity
Mar 10, 2020



We introduce Multi-SimLex, a large-scale lexical resource and evaluation benchmark covering datasets for 12 typologically diverse languages, including major languages (e.g., Mandarin Chinese, Spanish, Russian) as well as less-resourced ones (e.g., Welsh, Kiswahili). Each language dataset is annotated for the lexical relation of semantic similarity and contains 1,888 semantically aligned concept pairs, providing a representative coverage of word classes (nouns, verbs, adjectives, adverbs), frequency ranks, similarity intervals, lexical fields, and concreteness levels. Additionally, owing to the alignment of concepts across languages, we provide a suite of 66 cross-lingual semantic similarity datasets. Due to its extensive size and language coverage, Multi-SimLex provides entirely novel opportunities for experimental evaluation and analysis. On its monolingual and cross-lingual benchmarks, we evaluate and analyze a wide array of recent state-of-the-art monolingual and cross-lingual representation models, including static and contextualized word embeddings (such as fastText, M-BERT and XLM), externally informed lexical representations, as well as fully unsupervised and (weakly) supervised cross-lingual word embeddings. We also present a step-by-step dataset creation protocol for creating consistent, Multi-Simlex-style resources for additional languages. We make these contributions -- the public release of Multi-SimLex datasets, their creation protocol, strong baseline results, and in-depth analyses which can be be helpful in guiding future developments in multilingual lexical semantics and representation learning -- available via a website which will encourage community effort in further expansion of Multi-Simlex to many more languages. Such a large-scale semantic resource could inspire significant further advances in NLP across languages.