 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossing the Conversational Chasm: A Primer on Multilingual Task-Oriented Dialogue Systems
Paper and Code
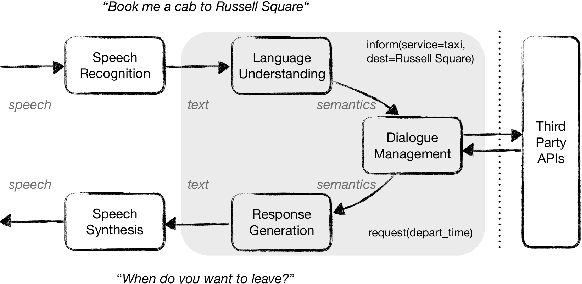
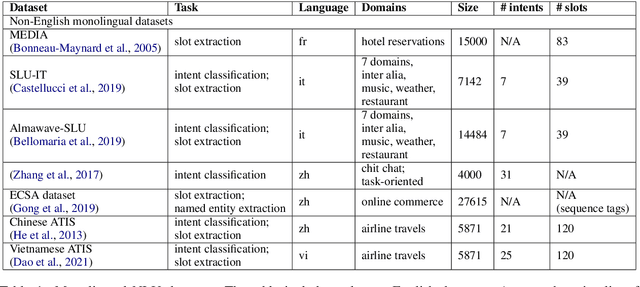

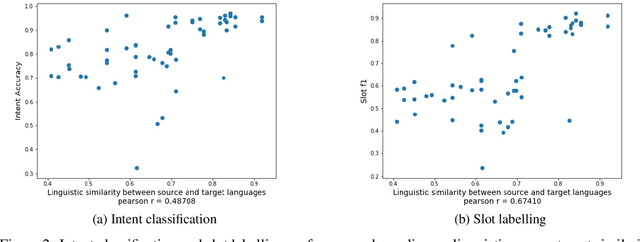
Despite the fact that natural language conversations with machines represent one of the central objectives of AI, and despite the massive increase of research and development efforts in conversational AI, task-oriented dialogue (ToD) -- i.e., conversations with an artificial agent with the aim of completing a concrete task -- is currently limited to a few narrow domains (e.g., food ordering, ticket booking) and a handful of major languages (e.g., English, Chinese). In this work, we provide an extensive overview of existing efforts in multilingual ToD and analyse the factors preventing the development of truly multilingual ToD systems. We identify two main challenges that combined hinder the faster progress in multilingual ToD: (1) current state-of-the-art ToD models based on large pretrained neural language models are data hungry; at the same time (2) data acquisition for ToD use cases is expensive and tedious. Most existing approaches to multilingual ToD thus rely on (zero- or few-shot) cross-lingual transfer from resource-rich languages (in ToD, this is basically only English), either by means of (i) machine translation or (ii) multilingual representation spaces. However, such approaches are currently not a viable solution for a large number of low-resource languages without parallel data and/or limited monolingual corpora. Finally, we discuss critical challenges and potential solutions by drawing parallels between ToD and other cross-lingual and multilingual NLP research.