 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Via: Analysis and Estimation of the Impact of Large Language Models in Academic Papers
Mar 26, 2026Through an analysis of arXiv papers, we report several shifts in word usage that are likely driven by large language models (LLMs) but have not previously received sufficient attention, such as the increased frequency of "beyond" and "via" in titles and the decreased frequency of "the" and "of" in abstracts. Due to the similarities among different LLMs, experiments show that current classifiers struggle to accurately determine which specific model generated a given text in multi-class classification tasks. Meanwhile, variations across LLMs also result in evolving patterns of word usage in academic papers. By adopting a direct and highly interpretable linear approach and accounting for differences between models and prompts, we quantitatively assess these effects and show that real-world LLM usage is heterogeneous and dynamic.
Markovian Generation Chains in Large Language Models
Mar 11, 2026The widespread use of large language models (LLMs) raises an important question: how do texts evolve when they are repeatedly processed by LLMs? In this paper, we define this iterative inference process as Markovian generation chains, where each step takes a specific prompt template and the previous output as input, without including any prior memory. In iterative rephrasing and round-trip translation experiments, the output either converges to a small recurrent set or continues to produce novel sentences over a finite horizon. Through sentence-level Markov chain modeling and analysis of simulated data, we show that iterative process can either increase or reduce sentence diversity depending on factors such as the temperature parameter and the initial input sentence. These results offer valuable insights into the dynamics of iterative LLM inference and their implications for multi-agent LLM systems.
MajinBook: An open catalogue of digital world literature with likes
Nov 18, 2025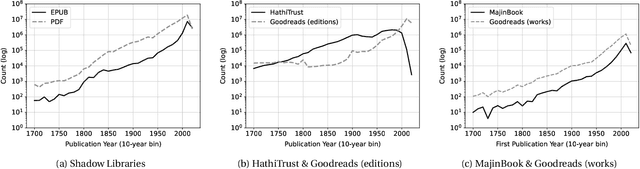
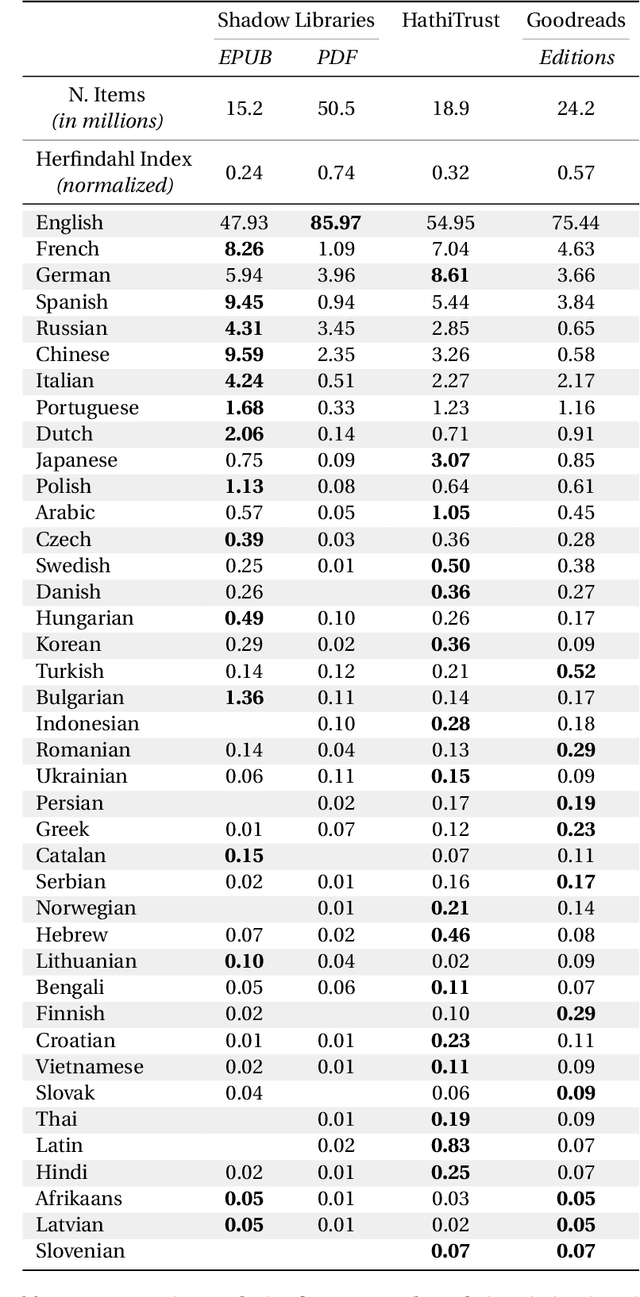
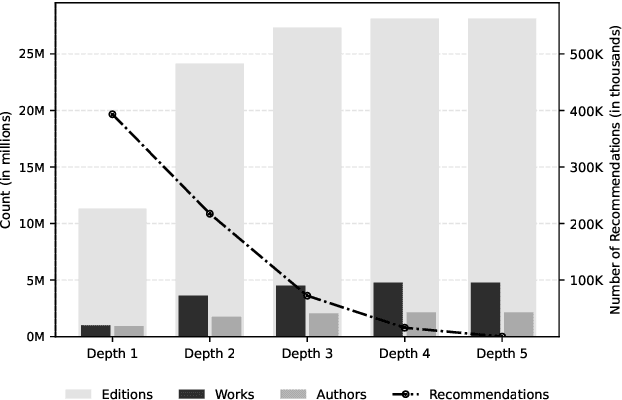
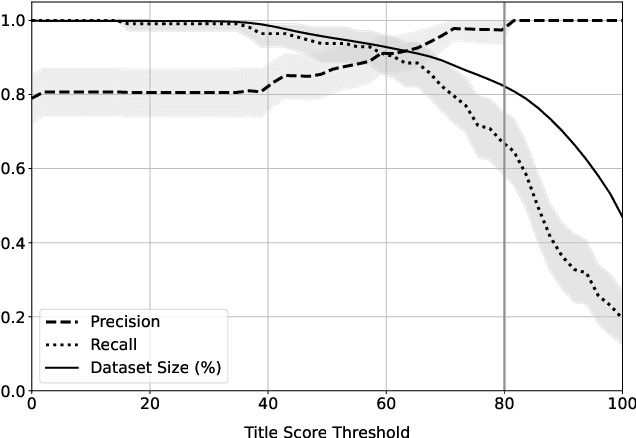
This data paper introduces MajinBook, an open catalogue designed to facilitate the use of shadow libraries--such as Library Genesis and Z-Library--for computational social science and cultural analytics. By linking metadata from these vast, crowd-sourced archives with structured bibliographic data from Goodreads, we create a high-precision corpus of over 539,000 references to English-language books spanning three centuries, enriched with first publication dates, genres, and popularity metrics like ratings and reviews. Our methodology prioritizes natively digital EPUB files to ensure machine-readable quality, while addressing biases in traditional corpora like HathiTrust, and includes secondary datasets for French, German, and Spanish. We evaluate the linkage strategy for accuracy, release all underlying data openly, and discuss the project's legal permissibility under EU and US frameworks for text and data mining in research.
On the Detectability of LLM-Generated Text: What Exactly Is LLM-Generated Text?
Oct 23, 2025With the widespread use of large language models (LLMs), many researchers have turned their attention to detecting text generated by them. However, there is no consistent or precise definition of their target, namely "LLM-generated text". Differences in usage scenarios and the diversity of LLMs further increase the difficulty of detection. What is commonly regarded as the detecting target usually represents only a subset of the text that LLMs can potentially produce. Human edits to LLM outputs, together with the subtle influences that LLMs exert on their users, are blurring the line between LLM-generated and human-written text. Existing benchmarks and evaluation approaches do not adequately address the various conditions in real-world detector applications. Hence, the numerical results of detectors are often misunderstood, and their significance is diminishing. Therefore, detectors remain useful under specific conditions, but their results should be interpreted only as references rather than decisive indicators.
Annotating References to Mythological Entities in French Literature
Dec 24, 2024In this paper, we explore the relevance of large language models (LLMs) for annotating references to Roman and Greek mythological entities in modern and contemporary French literature. We present an annotation scheme and demonstrate that recent LLMs can be directly applied to follow this scheme effectively, although not without occasionally making significant analytical errors. Additionally, we show that LLMs (and, more specifically, ChatGPT) are capable of offering interpretative insights into the use of mythological references by literary authors. However, we also find that LLMs struggle to accurately identify relevant passages in novels (when used as an information retrieval engine), often hallucinating and generating fabricated examples-an issue that raises significant ethical concerns. Nonetheless, when used carefully, LLMs remain valuable tools for performing annotations with high accuracy, especially for tasks that would be difficult to annotate comprehensively on a large scale through manual methods alone.
An Incremental Clustering Baseline for Event Detection on Twitter
Dec 16, 2024
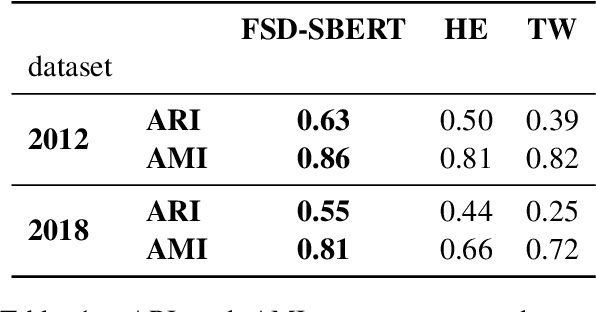
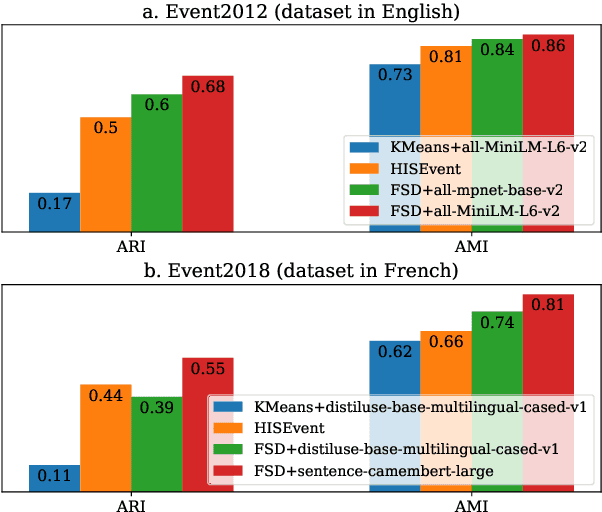
Event detection in text streams is a crucial task for the analysis of online media and social networks. One of the current challenges in this field is establishing a performance standard while maintaining an acceptable level of computational complexity. In our study, we use an incremental clustering algorithm combined with recent advancements in sentence embeddings. Our objective is to compare our findings with previous studies, specifically those by Cao et al. (2024) and Mazoyer et al. (2020). Our results demonstrate significant improvements and could serve as a relevant baseline for future research in this area.
How to Evaluate Coreference in Literary Texts?
Dec 30, 2023In this short paper, we examine the main metrics used to evaluate textual coreference and we detail some of their limitations. We show that a unique score cannot represent the full complexity of the problem at stake, and is thus uninformative, or even misleading. We propose a new way of evaluating coreference, taking into account the context (in our case, the analysis of fictions, esp. novels). More specifically, we propose to distinguish long coreference chains (corresponding to main characters), from short ones (corresponding to secondary characters), and singletons (isolated elements). This way, we hope to get more interpretable and thus more informative results through evaluation.
On the Correspondence between Compositionality and Imitation in Emergent Neural Communication
May 22, 2023Compositionality is a hallmark of human language that not only enables linguistic generalization, but also potentially facilitates acquisition. When simulating language emergence with neural networks, compositionality has been shown to improve communication performance; however, its impact on imitation learning has yet to be investigated. Our work explores the link between compositionality and imitation in a Lewis game played by deep neural agents. Our contributions are twofold: first, we show that the learning algorithm used to imitate is crucial: supervised learning tends to produce more average languages, while reinforcement learning introduces a selection pressure toward more compositional languages. Second, our study reveals that compositional languages are easier to imitate, which may induce the pressure toward compositional languages in RL imitation settings.
Modern French Poetry Generation with RoBERTa and GPT-2
Dec 06, 2022

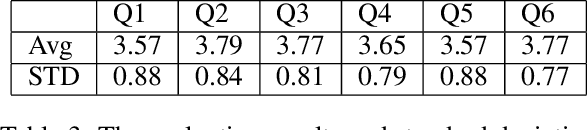
We present a novel neural model for modern poetry generation in French. The model consists of two pretrained neural models that are fine-tuned for the poem generation task. The encoder of the model is a RoBERTa based one while the decoder is based on GPT-2. This way the model can benefit from the superior natural language understanding performance of RoBERTa and the good natural language generation performance of GPT-2. Our evaluation shows that the model can create French poetry successfully. On a 5 point scale, the lowest score of 3.57 was given by human judges to typicality and emotionality of the output poetry while the best score of 3.79 was given to understandability.
Automatic Generation of Factual News Headlines in Finnish
Dec 05, 2022We present a novel approach to generating news headlines in Finnish for a given news story. We model this as a summarization task where a model is given a news article, and its task is to produce a concise headline describing the main topic of the article. Because there are no openly available GPT-2 models for Finnish, we will first build such a model using several corpora. The model is then fine-tuned for the headline generation task using a massive news corpus. The system is evaluated by 3 expert journalists working in a Finnish media house. The results showcase the usability of the presented approach as a headline suggestion tool to facilitate the news production process.