 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Self-Contained Negation Test Set
Aug 21, 2024



Several methodologies have recently been proposed to evaluate the ability of Pretrained Language Models (PLMs) to interpret negation. In this article, we build on Gubelmann and Handschuh (2022), which studies the modification of PLMs' predictions as a function of the polarity of inputs, in English. Crucially, this test uses ``self-contained'' inputs ending with a masked position: depending on the polarity of a verb in the input, a particular token is either semantically ruled out or allowed at the masked position. By replicating Gubelmann and Handschuh (2022) experiments, we have uncovered flaws that weaken the conclusions that can be drawn from this test. We thus propose an improved version, the Self-Contained Neg Test, which is more controlled, more systematic, and entirely based on examples forming minimal pairs varying only in the presence or absence of verbal negation in English. When applying our test to the roberta and bert base and large models, we show that only roberta-large shows trends that match the expectations, while bert-base is mostly insensitive to negation. For all the tested models though, in a significant number of test instances the top-1 prediction remains the token that is semantically forbidden by the context, which shows how much room for improvement remains for a proper treatment of the negation phenomenon.
Probing structural constraints of negation in Pretrained Language Models
Aug 06, 2024


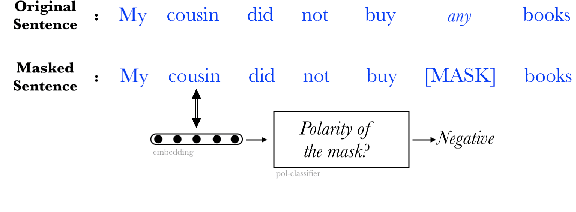
Contradictory results about the encoding of the semantic impact of negation in pretrained language models (PLMs). have been drawn recently (e.g. Kassner and Sch{\"u}tze (2020); Gubelmann and Handschuh (2022)). In this paper we focus rather on the way PLMs encode negation and its formal impact, through the phenomenon of the Negative Polarity Item (NPI) licensing in English. More precisely, we use probes to identify which contextual representations best encode 1) the presence of negation in a sentence, and 2) the polarity of a neighboring masked polarity item. We find that contextual representations of tokens inside the negation scope do allow for (i) a better prediction of the presence of not compared to those outside the scope and (ii) a better prediction of the right polarity of a masked polarity item licensed by not, although the magnitude of the difference varies from PLM to PLM. Importantly, in both cases the trend holds even when controlling for distance to not. This tends to indicate that the embeddings of these models do reflect the notion of negation scope, and do encode the impact of negation on NPI licensing. Yet, further control experiments reveal that the presence of other lexical items is also better captured when using the contextual representation of a token within the same syntactic clause than outside from it, suggesting that PLMs simply capture the more general notion of syntactic clause.
How to Evaluate Coreference in Literary Texts?
Dec 30, 2023In this short paper, we examine the main metrics used to evaluate textual coreference and we detail some of their limitations. We show that a unique score cannot represent the full complexity of the problem at stake, and is thus uninformative, or even misleading. We propose a new way of evaluating coreference, taking into account the context (in our case, the analysis of fictions, esp. novels). More specifically, we propose to distinguish long coreference chains (corresponding to main characters), from short ones (corresponding to secondary characters), and singletons (isolated elements). This way, we hope to get more interpretable and thus more informative results through evaluation.