 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
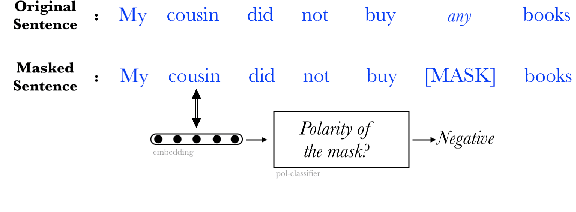
The Self-Contained Negation Test Set
Aug 21, 2024



Several methodologies have recently been proposed to evaluate the ability of Pretrained Language Models (PLMs) to interpret negation. In this article, we build on Gubelmann and Handschuh (2022), which studies the modification of PLMs' predictions as a function of the polarity of inputs, in English. Crucially, this test uses ``self-contained'' inputs ending with a masked position: depending on the polarity of a verb in the input, a particular token is either semantically ruled out or allowed at the masked position. By replicating Gubelmann and Handschuh (2022) experiments, we have uncovered flaws that weaken the conclusions that can be drawn from this test. We thus propose an improved version, the Self-Contained Neg Test, which is more controlled, more systematic, and entirely based on examples forming minimal pairs varying only in the presence or absence of verbal negation in English. When applying our test to the roberta and bert base and large models, we show that only roberta-large shows trends that match the expectations, while bert-base is mostly insensitive to negation. For all the tested models though, in a significant number of test instances the top-1 prediction remains the token that is semantically forbidden by the context, which shows how much room for improvement remains for a proper treatment of the negation phenomenon.
Probing structural constraints of negation in Pretrained Language Models
Aug 06, 2024


Contradictory results about the encoding of the semantic impact of negation in pretrained language models (PLMs). have been drawn recently (e.g. Kassner and Sch{\"u}tze (2020); Gubelmann and Handschuh (2022)). In this paper we focus rather on the way PLMs encode negation and its formal impact, through the phenomenon of the Negative Polarity Item (NPI) licensing in English. More precisely, we use probes to identify which contextual representations best encode 1) the presence of negation in a sentence, and 2) the polarity of a neighboring masked polarity item. We find that contextual representations of tokens inside the negation scope do allow for (i) a better prediction of the presence of not compared to those outside the scope and (ii) a better prediction of the right polarity of a masked polarity item licensed by not, although the magnitude of the difference varies from PLM to PLM. Importantly, in both cases the trend holds even when controlling for distance to not. This tends to indicate that the embeddings of these models do reflect the notion of negation scope, and do encode the impact of negation on NPI licensing. Yet, further control experiments reveal that the presence of other lexical items is also better captured when using the contextual representation of a token within the same syntactic clause than outside from it, suggesting that PLMs simply capture the more general notion of syntactic clause.
Injecting Wiktionary to improve token-level contextual representations using contrastive learning
Feb 12, 2024



While static word embeddings are blind to context, for lexical semantics tasks context is rather too present in contextual word embeddings, vectors of same-meaning occurrences being too different (Ethayarajh, 2019). Fine-tuning pre-trained language models (PLMs) using contrastive learning was proposed, leveraging automatically self-augmented examples (Liu et al., 2021b). In this paper, we investigate how to inject a lexicon as an alternative source of supervision, using the English Wiktionary. We also test how dimensionality reduction impacts the resulting contextual word embeddings. We evaluate our approach on the Word-In-Context (WiC) task, in the unsupervised setting (not using the training set). We achieve new SoTA result on the original WiC test set. We also propose two new WiC test sets for which we show that our fine-tuning method achieves substantial improvements. We also observe improvements, although modest, for the semantic frame induction task. Although we experimented on English to allow comparison with related work, our method is adaptable to the many languages for which large Wiktionaries exist.
Auxiliary Tasks to Boost Biaffine Semantic Dependency Parsing
Feb 12, 2024The biaffine parser of Dozat and Manning (2017) was successfully extended to semantic dependency parsing (SDP) (Dozat and Manning, 2018). Its performance on graphs is surprisingly high given that, without the constraint of producing a tree, all arcs for a given sentence are predicted independently from each other (modulo a shared representation of tokens). To circumvent such an independence of decision, while retaining the O(n^2) complexity and highly parallelizable architecture, we propose to use simple auxiliary tasks that introduce some form of interdependence between arcs. Experiments on the three English acyclic datasets of SemEval 2015 task 18 (Oepen et al., 2015), and on French deep syntactic cyclic graphs (Ribeyre et al., 2014) show modest but systematic performance gains on a near state-of-the-art baseline using transformer-based contextualized representations. This provides a simple and robust method to boost SDP performance.