 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn the LLM era, Word Sense Induction remains unsolved
Mar 12, 2026In the absence of sense-annotated data, word sense induction (WSI) is a compelling alternative to word sense disambiguation, particularly in low-resource or domain-specific settings. In this paper, we emphasize methodological problems in current WSI evaluation. We propose an evaluation on a SemCor-derived dataset, respecting the original corpus polysemy and frequency distributions. We assess pre-trained embeddings and clustering algorithms across parts of speech, and propose and evaluate an LLM-based WSI method for English. We evaluate data augmentation sources (LLM-generated, corpus and lexicon), and semi-supervised scenarios using Wiktionary for data augmentation, must-link constraints, number of clusters per lemma. We find that no unsupervised method (whether ours or previous) surpasses the strong "one cluster per lemma" heuristic (1cpl). We also show that (i) results and best systems may vary across POS, (ii) LLMs have troubles performing this task, (iii) data augmentation is beneficial and (iv) capitalizing on Wiktionary does help. It surpasses previous SOTA system on our test set by 3.3\%. WSI is not solved, and calls for a better articulation of lexicons and LLMs' lexical semantics capabilities.
CareMedEval dataset: Evaluating Critical Appraisal and Reasoning in the Biomedical Field
Nov 05, 2025



Critical appraisal of scientific literature is an essential skill in the biomedical field. While large language models (LLMs) can offer promising support in this task, their reliability remains limited, particularly for critical reasoning in specialized domains. We introduce CareMedEval, an original dataset designed to evaluate LLMs on biomedical critical appraisal and reasoning tasks. Derived from authentic exams taken by French medical students, the dataset contains 534 questions based on 37 scientific articles. Unlike existing benchmarks, CareMedEval explicitly evaluates critical reading and reasoning grounded in scientific papers. Benchmarking state-of-the-art generalist and biomedical-specialized LLMs under various context conditions reveals the difficulty of the task: open and commercial models fail to exceed an Exact Match Rate of 0.5 even though generating intermediate reasoning tokens considerably improves the results. Yet, models remain challenged especially on questions about study limitations and statistical analysis. CareMedEval provides a challenging benchmark for grounded reasoning, exposing current LLM limitations and paving the way for future development of automated support for critical appraisal.
Injecting Wiktionary to improve token-level contextual representations using contrastive learning
Feb 12, 2024



While static word embeddings are blind to context, for lexical semantics tasks context is rather too present in contextual word embeddings, vectors of same-meaning occurrences being too different (Ethayarajh, 2019). Fine-tuning pre-trained language models (PLMs) using contrastive learning was proposed, leveraging automatically self-augmented examples (Liu et al., 2021b). In this paper, we investigate how to inject a lexicon as an alternative source of supervision, using the English Wiktionary. We also test how dimensionality reduction impacts the resulting contextual word embeddings. We evaluate our approach on the Word-In-Context (WiC) task, in the unsupervised setting (not using the training set). We achieve new SoTA result on the original WiC test set. We also propose two new WiC test sets for which we show that our fine-tuning method achieves substantial improvements. We also observe improvements, although modest, for the semantic frame induction task. Although we experimented on English to allow comparison with related work, our method is adaptable to the many languages for which large Wiktionaries exist.
AMU-EURANOVA at CASE 2021 Task 1: Assessing the stability of multilingual BERT
Jun 10, 2021
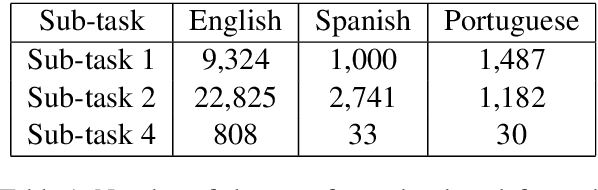
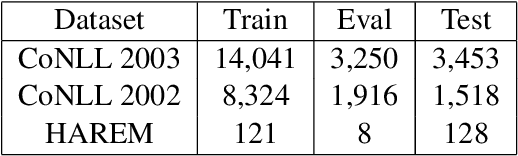

This paper explains our participation in task 1 of the CASE 2021 shared task. This task is about multilingual event extraction from news. We focused on sub-task 4, event information extraction. This sub-task has a small training dataset and we fine-tuned a multilingual BERT to solve this sub-task. We studied the instability problem on the dataset and tried to mitigate it.
To Be or Not To Be a Verbal Multiword Expression: A Quest for Discriminating Features
Jul 22, 2020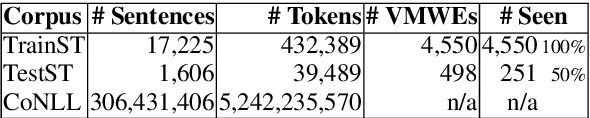
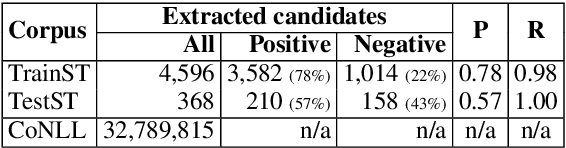
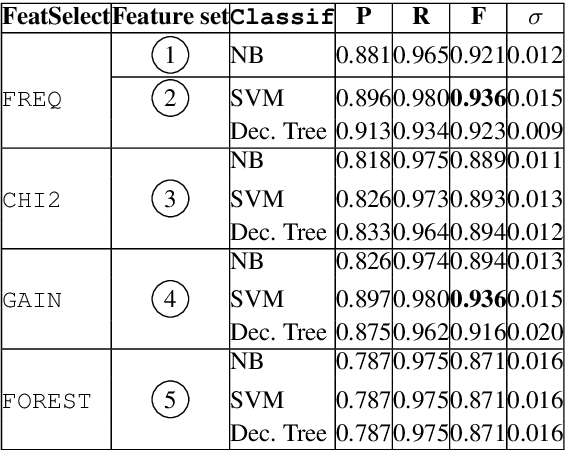

Automatic identification of mutiword expressions (MWEs) is a pre-requisite for semantically-oriented downstream applications. This task is challenging because MWEs, especially verbal ones (VMWEs), exhibit surface variability. However, this variability is usually more restricted than in regular (non-VMWE) constructions, which leads to various variability profiles. We use this fact to determine the optimal set of features which could be used in a supervised classification setting to solve a subproblem of VMWE identification: the identification of occurrences of previously seen VMWEs. Surprisingly, a simple custom frequency-based feature selection method proves more efficient than other standard methods such as Chi-squared test, information gain or decision trees. An SVM classifier using the optimal set of only 6 features outperforms the best systems from a recent shared task on the French seen data.
Multilingual enrichment of disease biomedical ontologies
Apr 07, 2020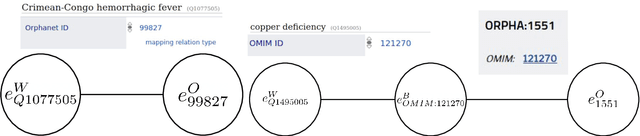



Translating biomedical ontologies is an important challenge, but doing it manually requires much time and money. We study the possibility to use open-source knowledge bases to translate biomedical ontologies. We focus on two aspects: coverage and quality. We look at the coverage of two biomedical ontologies focusing on diseases with respect to Wikidata for 9 European languages (Czech, Dutch, English, French, German, Italian, Polish, Portuguese and Spanish) for both ontologies, plus Arabic, Chinese and Russian for the second one. We first use direct links between Wikidata and the studied ontologies and then use second-order links by going through other intermediate ontologies. We then compare the quality of the translations obtained thanks to Wikidata with a commercial machine translation tool, here Google Cloud Translation.