 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning primal-dual sparse kernel machines
Aug 27, 2021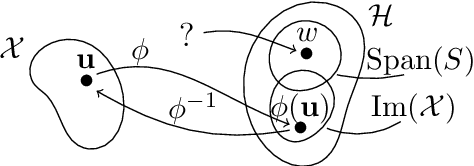
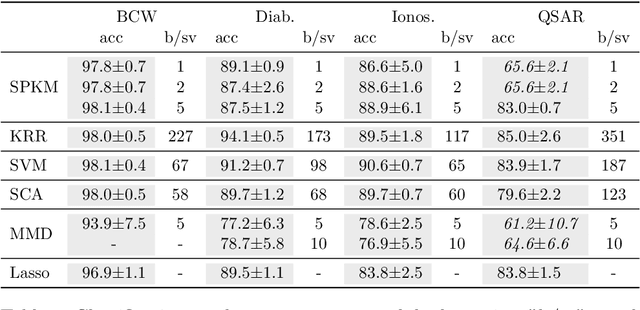
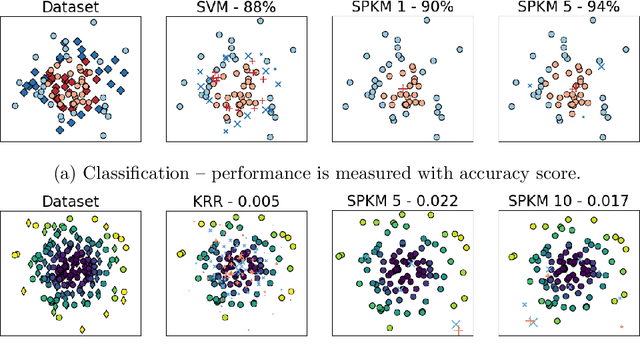
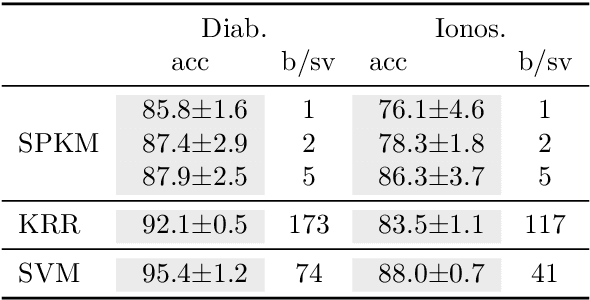
Traditionally, kernel methods rely on the representer theorem which states that the solution to a learning problem is obtained as a linear combination of the data mapped into the reproducing kernel Hilbert space (RKHS). While elegant from theoretical point of view, the theorem is prohibitive for algorithms' scalability to large datasets, and the interpretability of the learned function. In this paper, instead of using the traditional representer theorem, we propose to search for a solution in RKHS that has a pre-image decomposition in the original data space, where the elements don't necessarily correspond to the elements in the training set. Our gradient-based optimisation method then hinges on optimising over possibly sparse elements in the input space, and enables us to obtain a kernel-based model with both primal and dual sparsity. We give theoretical justification on the proposed method's generalization ability via a Rademacher bound. Our experiments demonstrate a better scalability and interpretability with accuracy on par with the traditional kernel-based models.
AMU-EURANOVA at CASE 2021 Task 1: Assessing the stability of multilingual BERT
Jun 10, 2021
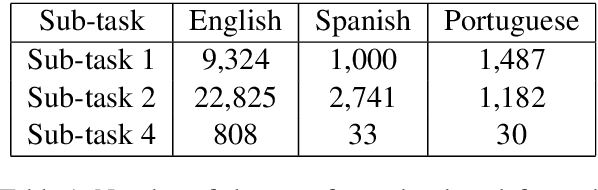
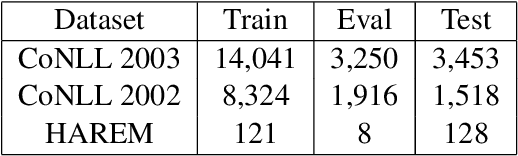

This paper explains our participation in task 1 of the CASE 2021 shared task. This task is about multilingual event extraction from news. We focused on sub-task 4, event information extraction. This sub-task has a small training dataset and we fine-tuned a multilingual BERT to solve this sub-task. We studied the instability problem on the dataset and tried to mitigate it.
Multilingual enrichment of disease biomedical ontologies
Apr 07, 2020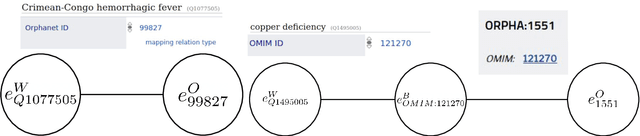



Translating biomedical ontologies is an important challenge, but doing it manually requires much time and money. We study the possibility to use open-source knowledge bases to translate biomedical ontologies. We focus on two aspects: coverage and quality. We look at the coverage of two biomedical ontologies focusing on diseases with respect to Wikidata for 9 European languages (Czech, Dutch, English, French, German, Italian, Polish, Portuguese and Spanish) for both ontologies, plus Arabic, Chinese and Russian for the second one. We first use direct links between Wikidata and the studied ontologies and then use second-order links by going through other intermediate ontologies. We then compare the quality of the translations obtained thanks to Wikidata with a commercial machine translation tool, here Google Cloud Translation.
Kernel transfer over multiple views for missing data completion
Oct 14, 2019



We consider the kernel completion problem with the presence of multiple views in the data. In this context the data samples can be fully missing in some views, creating missing columns and rows to the kernel matrices that are calculated individually for each view. We propose to solve the problem of completing the kernel matrices by transferring the features of the other views to represent the view under consideration. We align the known part of the kernel matrix with a new kernel built from the features of the other views. We are thus able to find generalizable structures in the kernel under completion, and represent it accurately. Its missing values can be predicted with the data available in other views. We illustrate the benefits of our approach with simulated data and multivariate digits dataset, as well as with real biological datasets from studies of pattern formation in early \textit{Drosophila melanogaster} embryogenesis.
Multi-view Metric Learning in Vector-valued Kernel Spaces
Mar 21, 2018



We consider the problem of metric learning for multi-view data and present a novel method for learning within-view as well as between-view metrics in vector-valued kernel spaces, as a way to capture multi-modal structure of the data. We formulate two convex optimization problems to jointly learn the metric and the classifier or regressor in kernel feature spaces. An iterative three-step multi-view metric learning algorithm is derived from the optimization problems. In order to scale the computation to large training sets, a block-wise Nystr{\"o}m approximation of the multi-view kernel matrix is introduced. We justify our approach theoretically and experimentally, and show its performance on real-world datasets against relevant state-of-the-art methods.
On multi-class learning through the minimization of the confusion matrix norm
Nov 03, 2013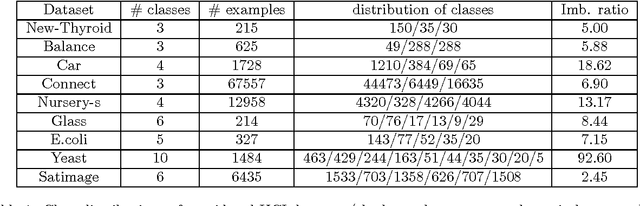
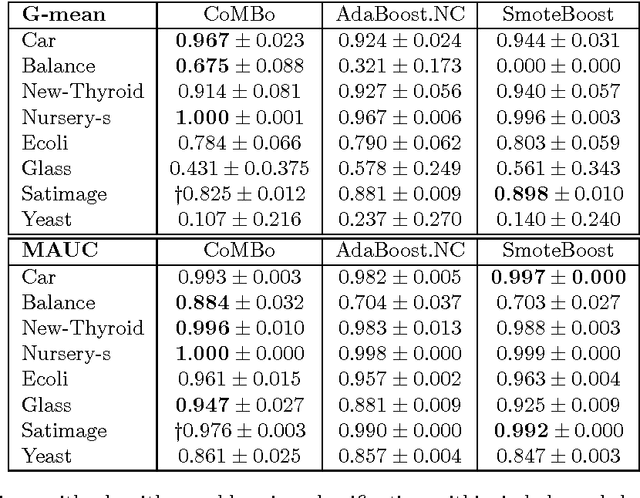
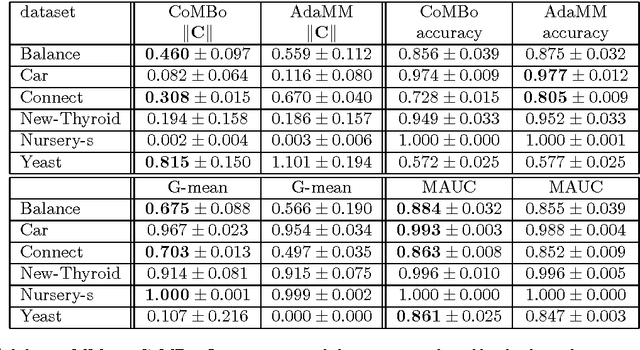
In imbalanced multi-class classification problems, the misclassification rate as an error measure may not be a relevant choice. Several methods have been developed where the performance measure retained richer information than the mere misclassification rate: misclassification costs, ROC-based information, etc. Following this idea of dealing with alternate measures of performance, we propose to address imbalanced classification problems by using a new measure to be optimized: the norm of the confusion matrix. Indeed, recent results show that using the norm of the confusion matrix as an error measure can be quite interesting due to the fine-grain informations contained in the matrix, especially in the case of imbalanced classes. Our first contribution then consists in showing that optimizing criterion based on the confusion matrix gives rise to a common background for cost-sensitive methods aimed at dealing with imbalanced classes learning problems. As our second contribution, we propose an extension of a recent multi-class boosting method --- namely AdaBoost.MM --- to the imbalanced class problem, by greedily minimizing the empirical norm of the confusion matrix. A theoretical analysis of the properties of the proposed method is presented, while experimental results illustrate the behavior of the algorithm and show the relevancy of the approach compared to other methods.