 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrate to Interpret
Jul 07, 2022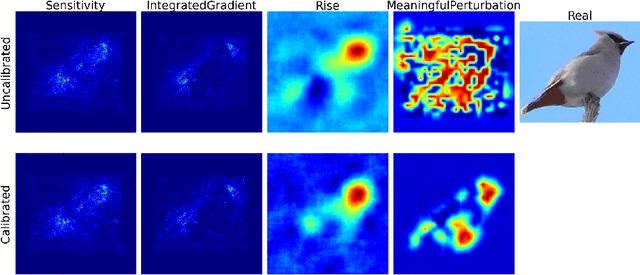
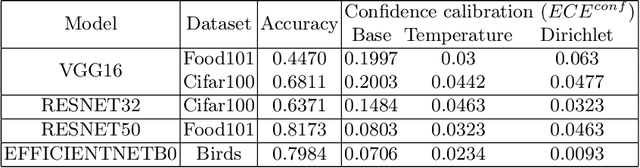
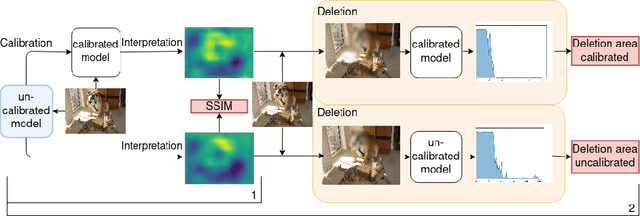
Trustworthy machine learning is driving a large number of ML community works in order to improve ML acceptance and adoption. The main aspect of trustworthy machine learning are the followings: fairness, uncertainty, robustness, explainability and formal guaranties. Each of these individual domains gains the ML community interest, visible by the number of related publications. However few works tackle the interconnection between these fields. In this paper we show a first link between uncertainty and explainability, by studying the relation between calibration and interpretation. As the calibration of a given model changes the way it scores samples, and interpretation approaches often rely on these scores, it seems safe to assume that the confidence-calibration of a model interacts with our ability to interpret such model. In this paper, we show, in the context of networks trained on image classification tasks, to what extent interpretations are sensitive to confidence-calibration. It leads us to suggest a simple practice to improve the interpretation outcomes: Calibrate to Interpret.
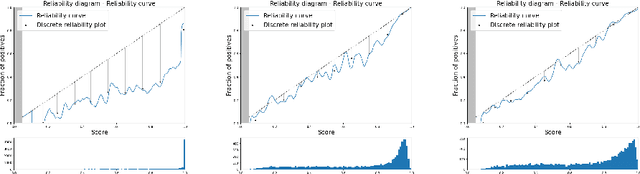
Estimating Expected Calibration Errors
Sep 08, 2021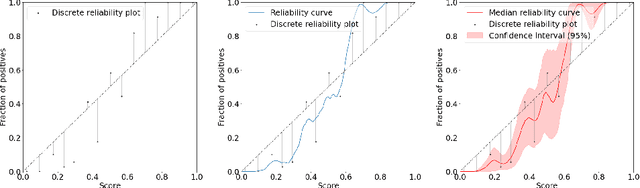
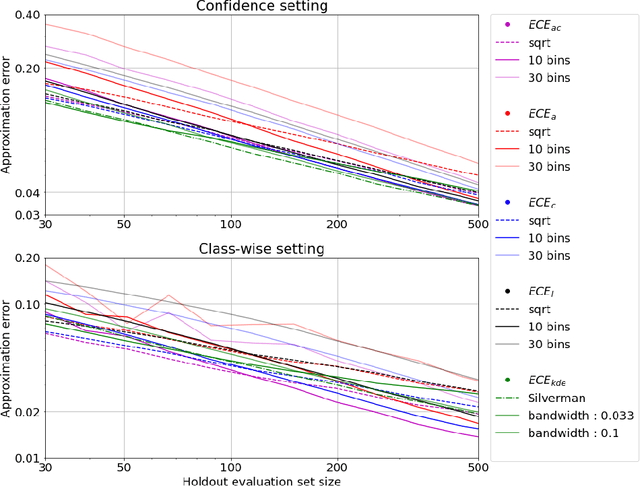
Uncertainty in probabilistic classifiers predictions is a key concern when models are used to support human decision making, in broader probabilistic pipelines or when sensitive automatic decisions have to be taken. Studies have shown that most models are not intrinsically well calibrated, meaning that their decision scores are not consistent with posterior probabilities. Hence being able to calibrate these models, or enforce calibration while learning them, has regained interest in recent literature. In this context, properly assessing calibration is paramount to quantify new contributions tackling calibration. However, there is room for improvement for commonly used metrics and evaluation of calibration could benefit from deeper analyses. Thus this paper focuses on the empirical evaluation of calibration metrics in the context of classification. More specifically it evaluates different estimators of the Expected Calibration Error ($ECE$), amongst which legacy estimators and some novel ones, proposed in this paper. We build an empirical procedure to quantify the quality of these $ECE$ estimators, and use it to decide which estimator should be used in practice for different settings.
AMU-EURANOVA at CASE 2021 Task 1: Assessing the stability of multilingual BERT
Jun 10, 2021
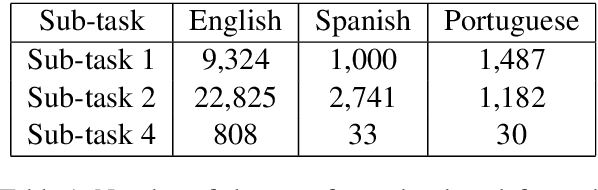

This paper explains our participation in task 1 of the CASE 2021 shared task. This task is about multilingual event extraction from news. We focused on sub-task 4, event information extraction. This sub-task has a small training dataset and we fine-tuned a multilingual BERT to solve this sub-task. We studied the instability problem on the dataset and tried to mitigate it.
Multilingual enrichment of disease biomedical ontologies
Apr 07, 2020



Translating biomedical ontologies is an important challenge, but doing it manually requires much time and money. We study the possibility to use open-source knowledge bases to translate biomedical ontologies. We focus on two aspects: coverage and quality. We look at the coverage of two biomedical ontologies focusing on diseases with respect to Wikidata for 9 European languages (Czech, Dutch, English, French, German, Italian, Polish, Portuguese and Spanish) for both ontologies, plus Arabic, Chinese and Russian for the second one. We first use direct links between Wikidata and the studied ontologies and then use second-order links by going through other intermediate ontologies. We then compare the quality of the translations obtained thanks to Wikidata with a commercial machine translation tool, here Google Cloud Translation.
STRASS: A Light and Effective Method for Extractive Summarization Based on Sentence Embeddings
Jul 16, 2019

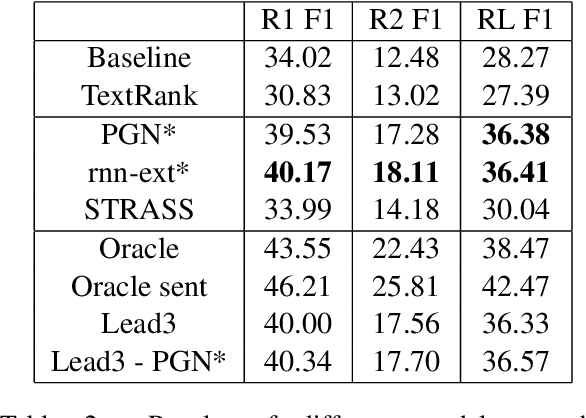

This paper introduces STRASS: Summarization by TRAnsformation Selection and Scoring. It is an extractive text summarization method which leverages the semantic information in existing sentence embedding spaces. Our method creates an extractive summary by selecting the sentences with the closest embeddings to the document embedding. The model learns a transformation of the document embedding to minimize the similarity between the extractive summary and the ground truth summary. As the transformation is only composed of a dense layer, the training can be done on CPU, therefore, inexpensive. Moreover, inference time is short and linear according to the number of sentences. As a second contribution, we introduce the French CASS dataset, composed of judgments from the French Court of cassation and their corresponding summaries. On this dataset, our results show that our method performs similarly to the state of the art extractive methods with effective training and inferring time.
Dynamic Screening: Accelerating First-Order Algorithms for the Lasso and Group-Lasso
Dec 12, 2014
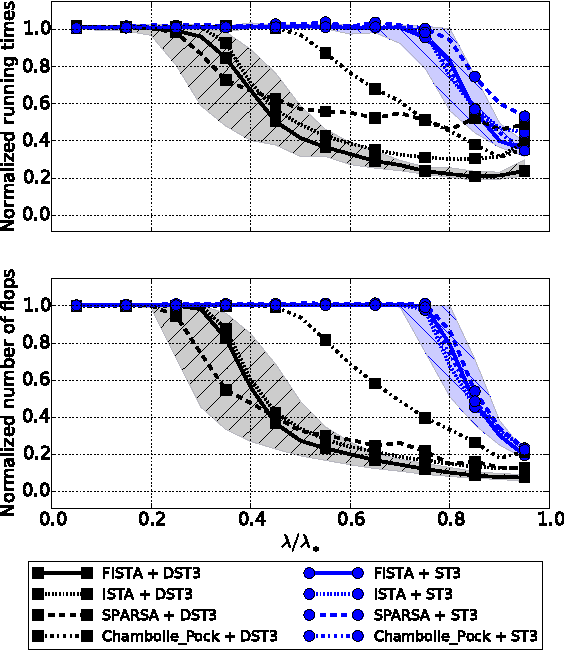
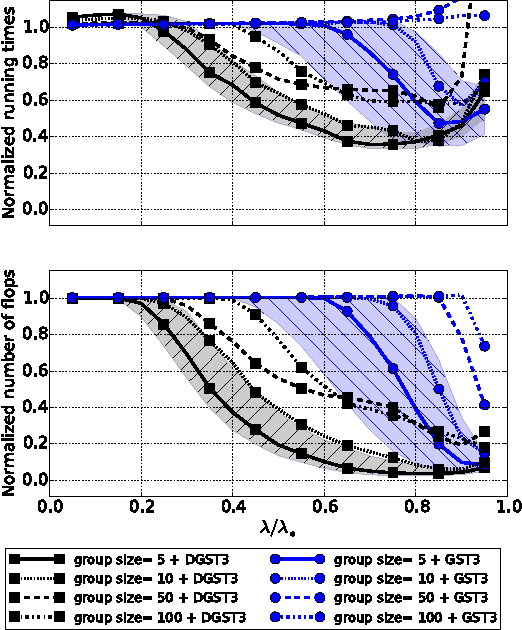

Recent computational strategies based on screening tests have been proposed to accelerate algorithms addressing penalized sparse regression problems such as the Lasso. Such approaches build upon the idea that it is worth dedicating some small computational effort to locate inactive atoms and remove them from the dictionary in a preprocessing stage so that the regression algorithm working with a smaller dictionary will then converge faster to the solution of the initial problem. We believe that there is an even more efficient way to screen the dictionary and obtain a greater acceleration: inside each iteration of the regression algorithm, one may take advantage of the algorithm computations to obtain a new screening test for free with increasing screening effects along the iterations. The dictionary is henceforth dynamically screened instead of being screened statically, once and for all, before the first iteration. We formalize this dynamic screening principle in a general algorithmic scheme and apply it by embedding inside a number of first-order algorithms adapted existing screening tests to solve the Lasso or new screening tests to solve the Group-Lasso. Computational gains are assessed in a large set of experiments on synthetic data as well as real-world sounds and images. They show both the screening efficiency and the gain in terms running times.