 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Wasserstein Distance
Oct 03, 2023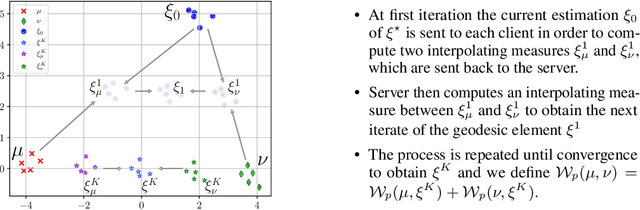

We introduce a principled way of computing the Wasserstein distance between two distributions in a federated manner. Namely, we show how to estimate the Wasserstein distance between two samples stored and kept on different devices/clients whilst a central entity/server orchestrates the computations (again, without having access to the samples). To achieve this feat, we take advantage of the geometric properties of the Wasserstein distance -- in particular, the triangle inequality -- and that of the associated {\em geodesics}: our algorithm, FedWad (for Federated Wasserstein Distance), iteratively approximates the Wasserstein distance by manipulating and exchanging distributions from the space of geodesics in lieu of the input samples. In addition to establishing the convergence properties of FedWad, we provide empirical results on federated coresets and federate optimal transport dataset distance, that we respectively exploit for building a novel federated model and for boosting performance of popular federated learning algorithms.
Personalised Federated Learning On Heterogeneous Feature Spaces
Jan 26, 2023Most personalised federated learning (FL) approaches assume that raw data of all clients are defined in a common subspace i.e. all clients store their data according to the same schema. For real-world applications, this assumption is restrictive as clients, having their own systems to collect and then store data, may use heterogeneous data representations. We aim at filling this gap. To this end, we propose a general framework coined FLIC that maps client's data onto a common feature space via local embedding functions. The common feature space is learnt in a federated manner using Wasserstein barycenters while the local embedding functions are trained on each client via distribution alignment. We integrate this distribution alignement mechanism into a federated learning approach and provide the algorithmics of FLIC. We compare its performances against FL benchmarks involving heterogeneous input features spaces. In addition, we provide theoretical insights supporting the relevance of our methodology.
Shedding a PAC-Bayesian Light on Adaptive Sliced-Wasserstein Distances
Jun 07, 2022
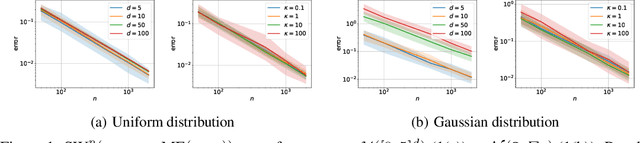
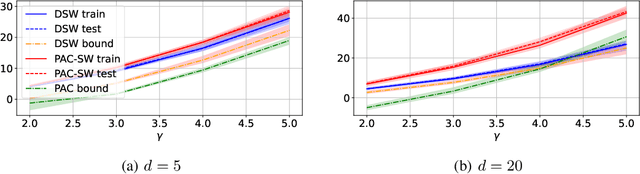
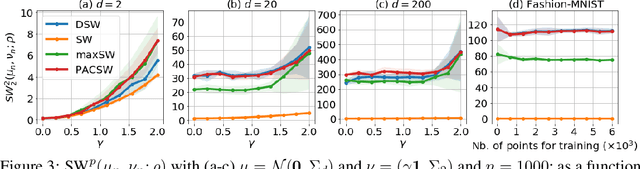
The Sliced-Wasserstein distance (SW) is a computationally efficient and theoretically grounded alternative to the Wasserstein distance. Yet, the literature on its statistical properties with respect to the distribution of slices, beyond the uniform measure, is scarce. To bring new contributions to this line of research, we leverage the PAC-Bayesian theory and the central observation that SW actually hinges on a slice-distribution-dependent Gibbs risk, the kind of quantity PAC-Bayesian bounds have been designed to characterize. We provide four types of results: i) PAC-Bayesian generalization bounds that hold on what we refer as adaptive Sliced-Wasserstein distances, i.e. distances defined with respect to any distribution of slices, ii) a procedure to learn the distribution of slices that yields a maximally discriminative SW, by optimizing our PAC-Bayesian bounds, iii) an insight on how the performance of the so-called distributional Sliced-Wasserstein distance may be explained through our theory, and iv) empirical illustrations of our findings.
Differentially Private Sliced Wasserstein Distance
Jul 05, 2021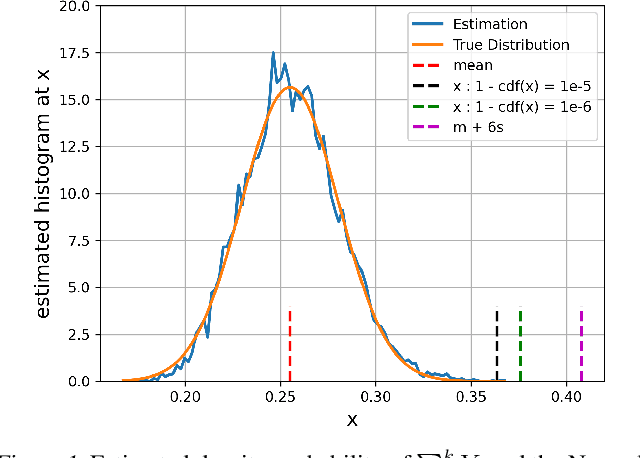
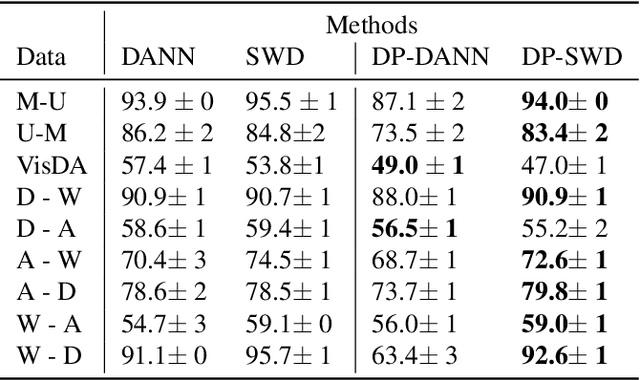
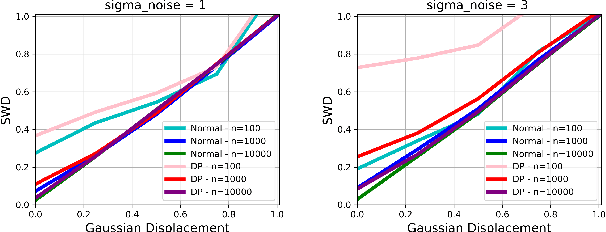
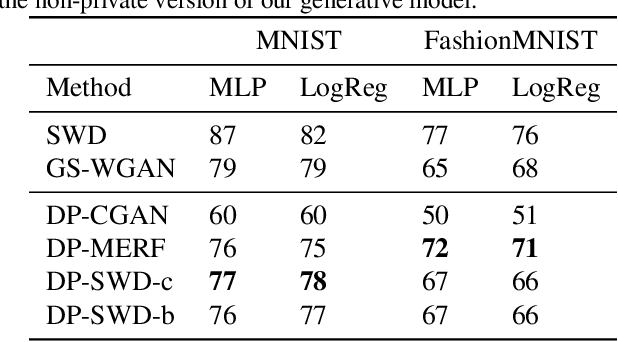
Developing machine learning methods that are privacy preserving is today a central topic of research, with huge practical impacts. Among the numerous ways to address privacy-preserving learning, we here take the perspective of computing the divergences between distributions under the Differential Privacy (DP) framework -- being able to compute divergences between distributions is pivotal for many machine learning problems, such as learning generative models or domain adaptation problems. Instead of resorting to the popular gradient-based sanitization method for DP, we tackle the problem at its roots by focusing on the Sliced Wasserstein Distance and seamlessly making it differentially private. Our main contribution is as follows: we analyze the property of adding a Gaussian perturbation to the intrinsic randomized mechanism of the Sliced Wasserstein Distance, and we establish the sensitivityof the resulting differentially private mechanism. One of our important findings is that this DP mechanism transforms the Sliced Wasserstein distance into another distance, that we call the Smoothed Sliced Wasserstein Distance. This new differentially private distribution distance can be plugged into generative models and domain adaptation algorithms in a transparent way, and we empirically show that it yields highly competitive performance compared with gradient-based DP approaches from the literature, with almost no loss in accuracy for the domain adaptation problems that we consider.
Photonic Differential Privacy with Direct Feedback Alignment
Jun 07, 2021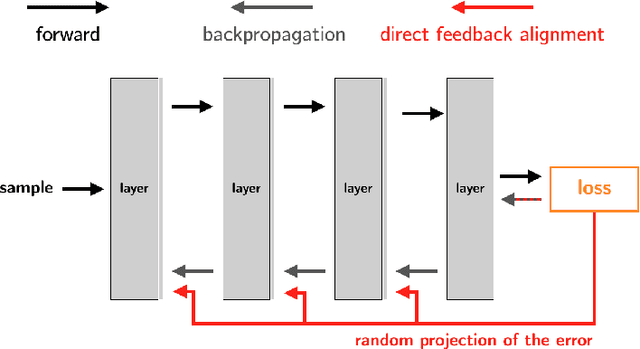
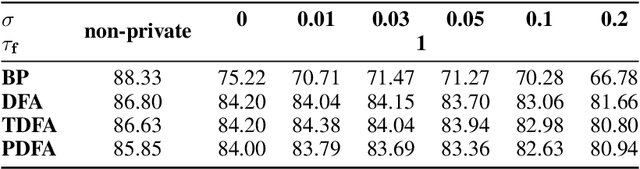
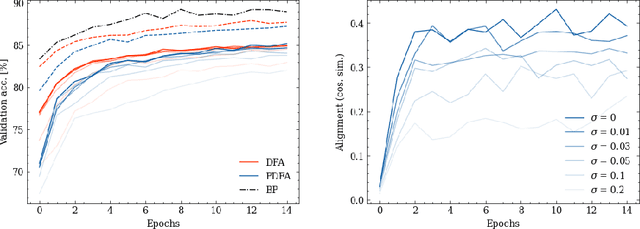
Optical Processing Units (OPUs) -- low-power photonic chips dedicated to large scale random projections -- have been used in previous work to train deep neural networks using Direct Feedback Alignment (DFA), an effective alternative to backpropagation. Here, we demonstrate how to leverage the intrinsic noise of optical random projections to build a differentially private DFA mechanism, making OPUs a solution of choice to provide a private-by-design training. We provide a theoretical analysis of our adaptive privacy mechanism, carefully measuring how the noise of optical random projections propagates in the process and gives rise to provable Differential Privacy. Finally, we conduct experiments demonstrating the ability of our learning procedure to achieve solid end-task performance.
Partial Trace Regression and Low-Rank Kraus Decomposition
Jul 02, 2020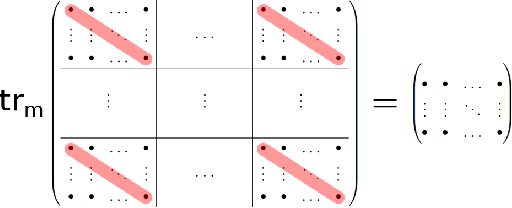

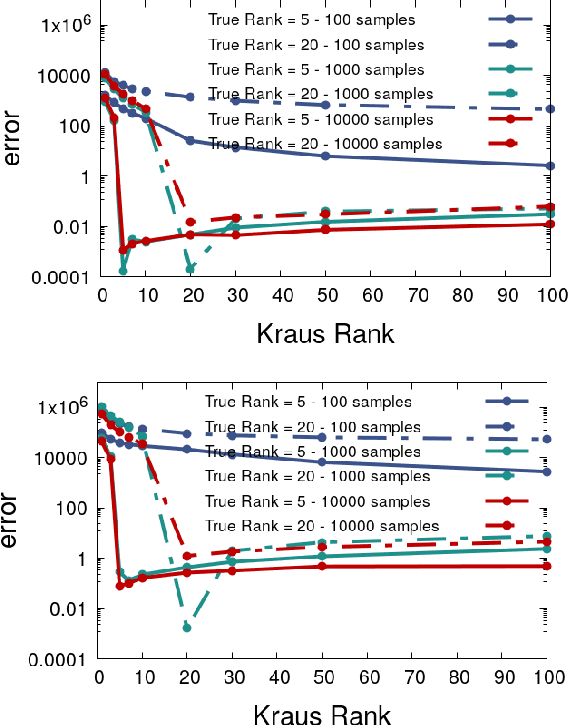
The trace regression model, a direct extension of the well-studied linear regression model, allows one to map matrices to real-valued outputs. We here introduce an even more general model, namely the partial-trace regression model, a family of linear mappings from matrix-valued inputs to matrix-valued outputs; this model subsumes the trace regression model and thus the linear regression model. Borrowing tools from quantum information theory, where partial trace operators have been extensively studied, we propose a framework for learning partial trace regression models from data by taking advantage of the so-called low-rank Kraus representation of completely positive maps. We show the relevance of our framework with synthetic and real-world experiments conducted for both i) matrix-to-matrix regression and ii) positive semidefinite matrix completion, two tasks which can be formulated as partial trace regression problems.
Quantum Bandits
Feb 15, 2020We consider the quantum version of the bandit problem known as {\em best arm identification} (BAI). We first propose a quantum modeling of the BAI problem, which assumes that both the learning agent and the environment are quantum; we then propose an algorithm based on quantum amplitude amplification to solve BAI. We formally analyze the behavior of the algorithm on all instances of the problem and we show, in particular, that it is able to get the optimal solution quadratically faster than what is known to hold in the classical case.
QuicK-means: Acceleration of K-means by learning a fast transform
Aug 23, 2019
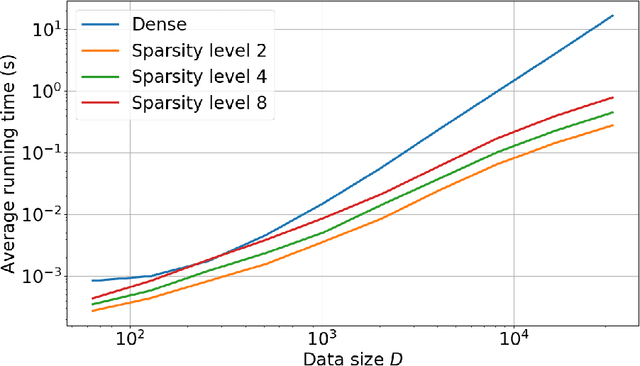

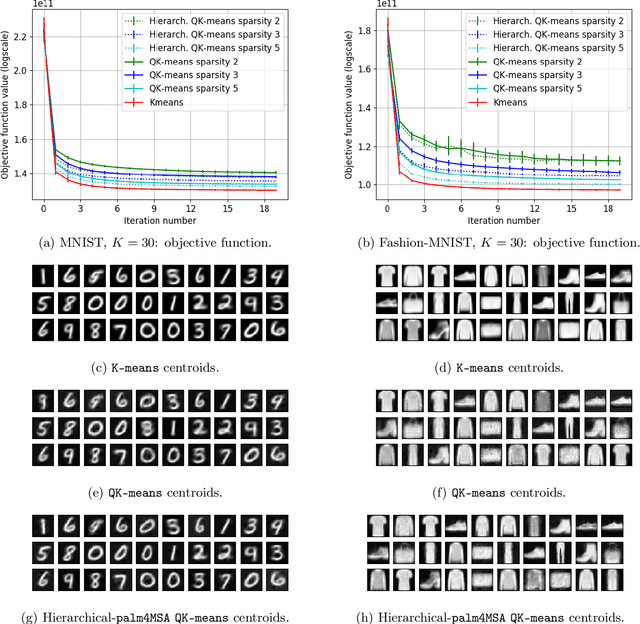
K-means -- and the celebrated Lloyd algorithm -- is more than the clustering method it was originally designed to be. It has indeed proven pivotal to help increase the speed of many machine learning and data analysis techniques such as indexing, nearest-neighbor search and prediction, data compression; its beneficial use has been shown to carry over to the acceleration of kernel machines (when using the Nystr\"om method). Here, we propose a fast extension of K-means, dubbed QuicK-means, that rests on the idea of expressing the matrix of the $K$ centroids as a product of sparse matrices, a feat made possible by recent results devoted to find approximations of matrices as a product of sparse factors. Using such a decomposition squashes the complexity of the matrix-vector product between the factorized $K \times D$ centroid matrix $\mathbf{U}$ and any vector from $\mathcal{O}(K D)$ to $\mathcal{O}(A \log A+B)$, with $A=\min (K, D)$ and $B=\max (K, D)$, where $D$ is the dimension of the training data. This drastic computational saving has a direct impact in the assignment process of a point to a cluster, meaning that it is not only tangible at prediction time, but also at training time, provided the factorization procedure is performed during Lloyd's algorithm. We precisely show that resorting to a factorization step at each iteration does not impair the convergence of the optimization scheme and that, depending on the context, it may entail a reduction of the training time. Finally, we provide discussions and numerical simulations that show the versatility of our computationally-efficient QuicK-means algorithm.
Frank-Wolfe Algorithm for the Exact Sparse Problem
Dec 18, 2018In this paper, we study the properties of the Frank-Wolfe algorithm to solve the \ExactSparse reconstruction problem. We prove that when the dictionary is quasi-incoherent, at each iteration, the Frank-Wolfe algorithm picks up an atom indexed by the support. We also prove that when the dictionary is quasi-incoherent, there exists an iteration beyond which the algorithm converges exponentially fast.
Greedy methods, randomization approaches and multi-arm bandit algorithms for efficient sparsity-constrained optimization
Aug 22, 2016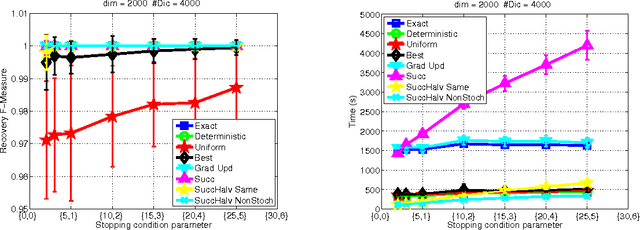
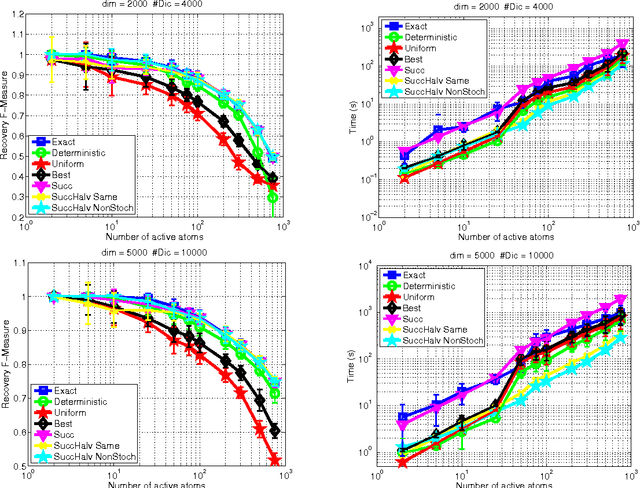
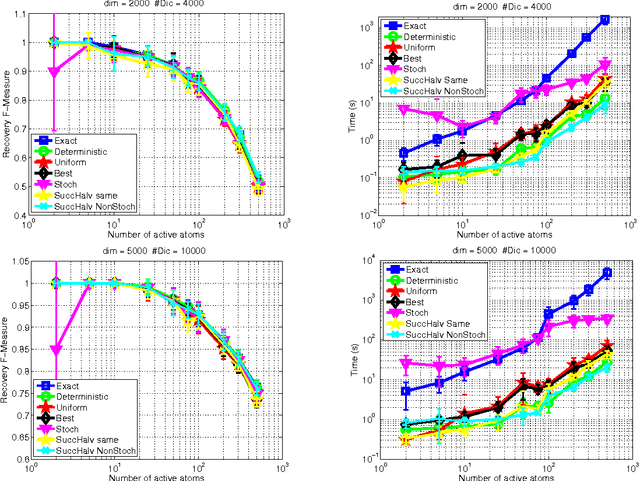
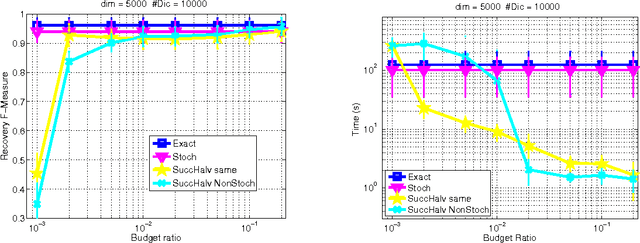
Several sparsity-constrained algorithms such as Orthogonal Matching Pursuit or the Frank-Wolfe algorithm with sparsity constraints work by iteratively selecting a novel atom to add to the current non-zero set of variables. This selection step is usually performed by computing the gradient and then by looking for the gradient component with maximal absolute entry. This step can be computationally expensive especially for large-scale and high-dimensional data. In this work, we aim at accelerating these sparsity-constrained optimization algorithms by exploiting the key observation that, for these algorithms to work, one only needs the coordinate of the gradient's top entry. Hence, we introduce algorithms based on greedy methods and randomization approaches that aim at cheaply estimating the gradient and its top entry. Another of our contribution is to cast the problem of finding the best gradient entry as a best arm identification in a multi-armed bandit problem. Owing to this novel insight, we are able to provide a bandit-based algorithm that directly estimates the top entry in a very efficient way. Theoretical observations stating that the resulting inexact Frank-Wolfe or Orthogonal Matching Pursuit algorithms act, with high probability, similarly to their exact versions are also given. We have carried out several experiments showing that the greedy deterministic and the bandit approaches we propose can achieve an acceleration of an order of magnitude while being as efficient as the exact gradient when used in algorithms such as OMP, Frank-Wolfe or CoSaMP.