 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Quantum Operator-Valued Kernels
Jun 04, 2025Quantum kernels are reproducing kernel functions built using quantum-mechanical principles and are studied with the aim of outperforming their classical counterparts. The enthusiasm for quantum kernel machines has been tempered by recent studies that have suggested that quantum kernels could not offer speed-ups when learning on classical data. However, most of the research in this area has been devoted to scalar-valued kernels in standard classification or regression settings for which classical kernel methods are efficient and effective, leaving very little room for improvement with quantum kernels. This position paper argues that quantum kernel research should focus on more expressive kernel classes. We build upon recent advances in operator-valued kernels, and propose guidelines for investigating quantum kernels. This should help to design a new generation of quantum kernel machines and fully explore their potentials.
Large-Scale Quantum Separability Through a Reproducible Machine Learning Lens
Jun 15, 2023



The quantum separability problem consists in deciding whether a bipartite density matrix is entangled or separable. In this work, we propose a machine learning pipeline for finding approximate solutions for this NP-hard problem in large-scale scenarios. We provide an efficient Frank-Wolfe-based algorithm to approximately seek the nearest separable density matrix and derive a systematic way for labeling density matrices as separable or entangled, allowing us to treat quantum separability as a classification problem. Our method is applicable to any two-qudit mixed states. Numerical experiments with quantum states of 3- and 7-dimensional qudits validate the efficiency of the proposed procedure, and demonstrate that it scales up to thousands of density matrices with a high quantum entanglement detection accuracy. This takes a step towards benchmarking quantum separability to support the development of more powerful entanglement detection techniques.
Proceedings of the fourth "international Traveling Workshop on Interactions between low-complexity data models and Sensing Techniques" (iTWIST'18)
Dec 20, 2018The iTWIST workshop series aim at fostering collaboration between international scientific teams for developing new theories, applications and generalizations of low-complexity models. These events emphasize dissemination of ideas through both specific oral and poster presentations, as well as free discussions. For this fourth edition, iTWIST'18 gathered in CIRM, Marseille, France, 74 international participants and featured 7 invited talks, 16 oral presentations, and 21 posters. From iTWIST'18, the scientific committee has decided that the workshop proceedings will adopt the episcience.org philosophy, combined with arXiv.org: in a nutshell, "the proceedings are equivalent to an overlay page, built above arXiv.org; they add value to these archives by attaching a scientific caution to the validated papers." This means that all papers listed in the HTML page of this arxiv publication (see the menu on the right) have been thoroughly evaluated and approved by two independent reviewers, and authors have revised their work according to the comments provided by these reviewers.
Frank-Wolfe Algorithm for the Exact Sparse Problem
Dec 18, 2018In this paper, we study the properties of the Frank-Wolfe algorithm to solve the \ExactSparse reconstruction problem. We prove that when the dictionary is quasi-incoherent, at each iteration, the Frank-Wolfe algorithm picks up an atom indexed by the support. We also prove that when the dictionary is quasi-incoherent, there exists an iteration beyond which the algorithm converges exponentially fast.
Optimal Computational Trade-Off of Inexact Proximal Methods
Oct 21, 2012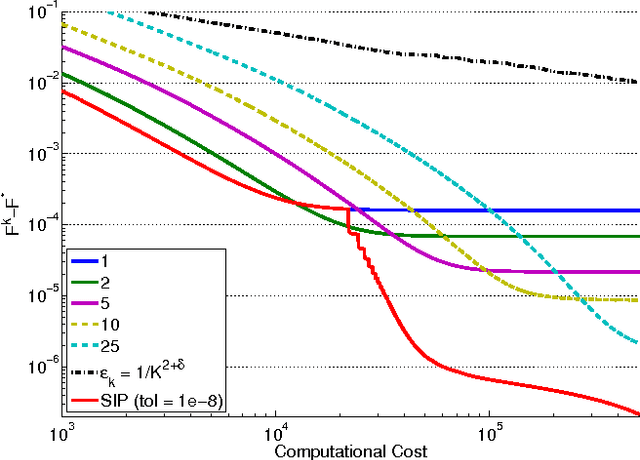
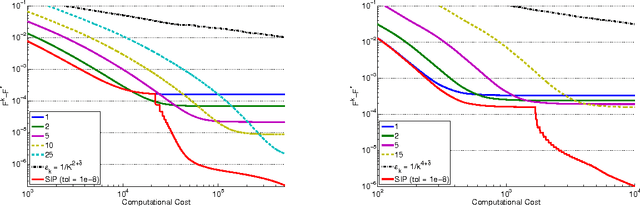
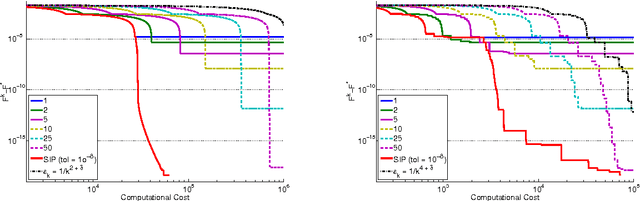
In this paper, we investigate the trade-off between convergence rate and computational cost when minimizing a composite functional with proximal-gradient methods, which are popular optimisation tools in machine learning. We consider the case when the proximity operator is computed via an iterative procedure, which provides an approximation of the exact proximity operator. In that case, we obtain algorithms with two nested loops. We show that the strategy that minimizes the computational cost to reach a solution with a desired accuracy in finite time is to set the number of inner iterations to a constant, which differs from the strategy indicated by a convergence rate analysis. In the process, we also present a new procedure called SIP (that is Speedy Inexact Proximal-gradient algorithm) that is both computationally efficient and easy to implement. Our numerical experiments confirm the theoretical findings and suggest that SIP can be a very competitive alternative to the standard procedure.
Stochastic Low-Rank Kernel Learning for Regression
Jan 11, 2012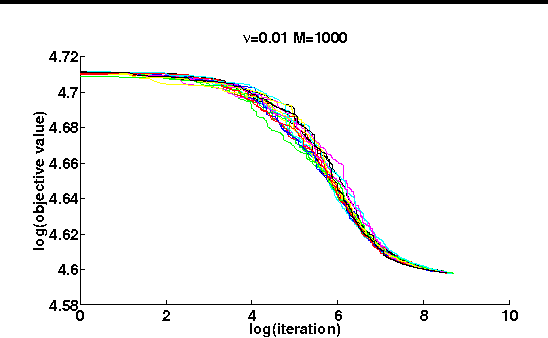
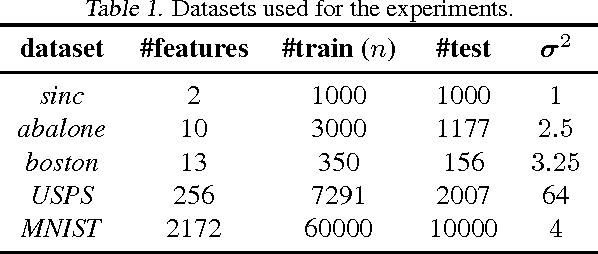
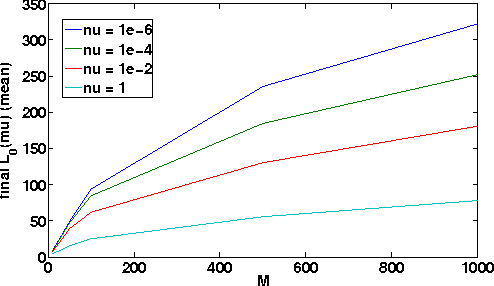
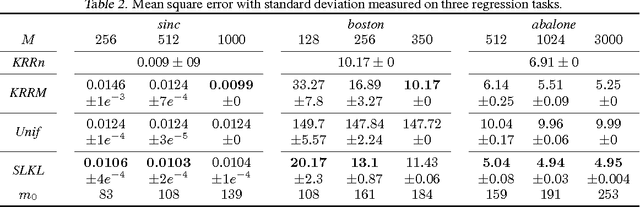
We present a novel approach to learn a kernel-based regression function. It is based on the useof conical combinations of data-based parameterized kernels and on a new stochastic convex optimization procedure of which we establish convergence guarantees. The overall learning procedure has the nice properties that a) the learned conical combination is automatically designed to perform the regression task at hand and b) the updates implicated by the optimization procedure are quite inexpensive. In order to shed light on the appositeness of our learning strategy, we present empirical results from experiments conducted on various benchmark datasets.