 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport Exploration Algorithm for Sparse Support Recovery
Jan 31, 2023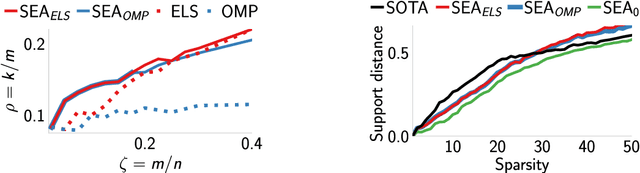
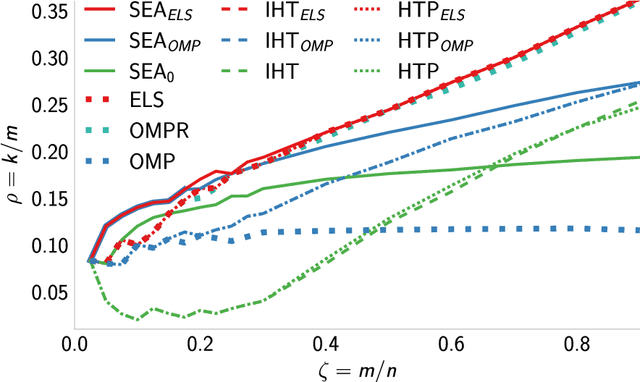
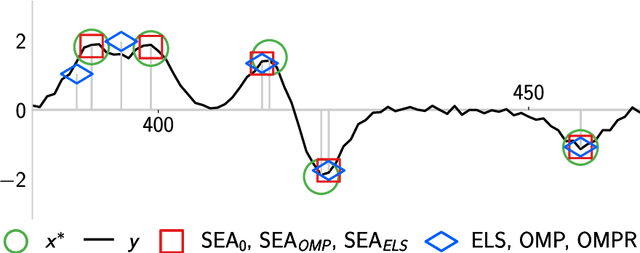
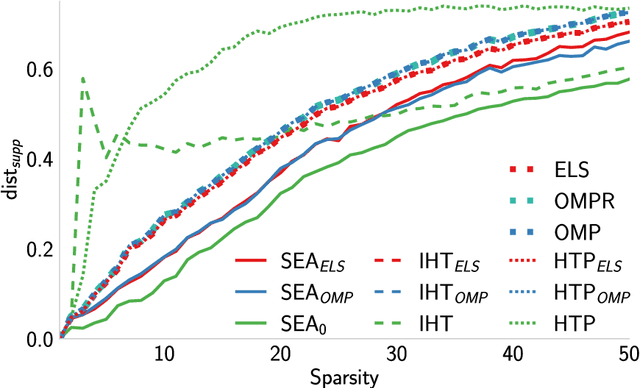
We introduce a new algorithm promoting sparsity called {\it Support Exploration Algorithm (SEA)} and analyze it in the context of support recovery/model selection problems.The algorithm can be interpreted as an instance of the {\it straight-through estimator (STE)} applied to the resolution of a sparse linear inverse problem. SEA uses a non-sparse exploratory vector and makes it evolve in the input space to select the sparse support. We put to evidence an oracle update rule for the exploratory vector and consider the STE update. The theoretical analysis establishes general sufficient conditions of support recovery. The general conditions are specialized to the case where the matrix $A$ performing the linear measurements satisfies the {\it Restricted Isometry Property (RIP)}.Experiments show that SEA can efficiently improve the results of any algorithm. Because of its exploratory nature, SEA also performs remarkably well when the columns of $A$ are strongly coherent.
QuicK-means: Acceleration of K-means by learning a fast transform
Aug 23, 2019
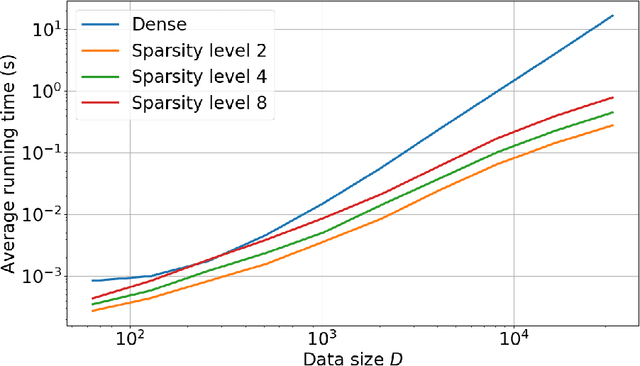

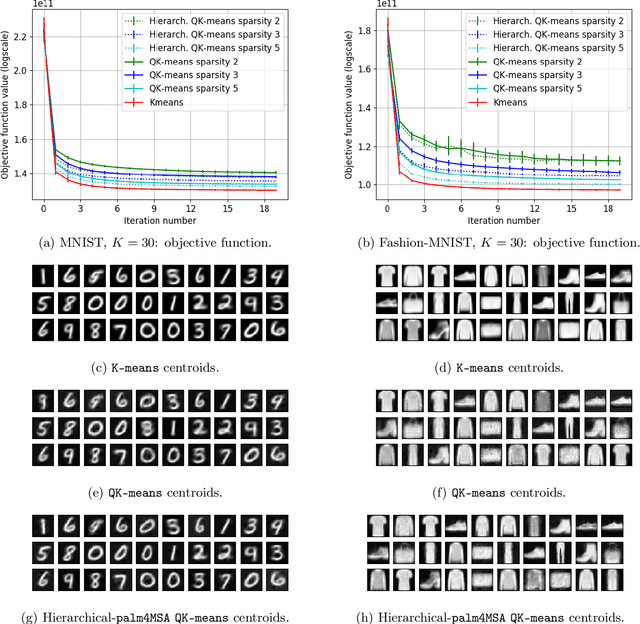
K-means -- and the celebrated Lloyd algorithm -- is more than the clustering method it was originally designed to be. It has indeed proven pivotal to help increase the speed of many machine learning and data analysis techniques such as indexing, nearest-neighbor search and prediction, data compression; its beneficial use has been shown to carry over to the acceleration of kernel machines (when using the Nystr\"om method). Here, we propose a fast extension of K-means, dubbed QuicK-means, that rests on the idea of expressing the matrix of the $K$ centroids as a product of sparse matrices, a feat made possible by recent results devoted to find approximations of matrices as a product of sparse factors. Using such a decomposition squashes the complexity of the matrix-vector product between the factorized $K \times D$ centroid matrix $\mathbf{U}$ and any vector from $\mathcal{O}(K D)$ to $\mathcal{O}(A \log A+B)$, with $A=\min (K, D)$ and $B=\max (K, D)$, where $D$ is the dimension of the training data. This drastic computational saving has a direct impact in the assignment process of a point to a cluster, meaning that it is not only tangible at prediction time, but also at training time, provided the factorization procedure is performed during Lloyd's algorithm. We precisely show that resorting to a factorization step at each iteration does not impair the convergence of the optimization scheme and that, depending on the context, it may entail a reduction of the training time. Finally, we provide discussions and numerical simulations that show the versatility of our computationally-efficient QuicK-means algorithm.
Frank-Wolfe Algorithm for the Exact Sparse Problem
Dec 18, 2018In this paper, we study the properties of the Frank-Wolfe algorithm to solve the \ExactSparse reconstruction problem. We prove that when the dictionary is quasi-incoherent, at each iteration, the Frank-Wolfe algorithm picks up an atom indexed by the support. We also prove that when the dictionary is quasi-incoherent, there exists an iteration beyond which the algorithm converges exponentially fast.
Optimal spectral transportation with application to music transcription
Oct 10, 2016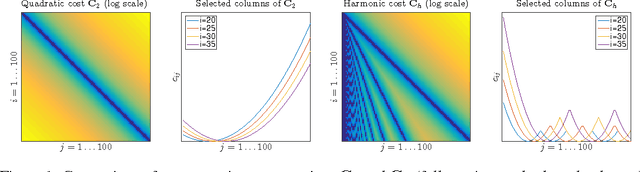


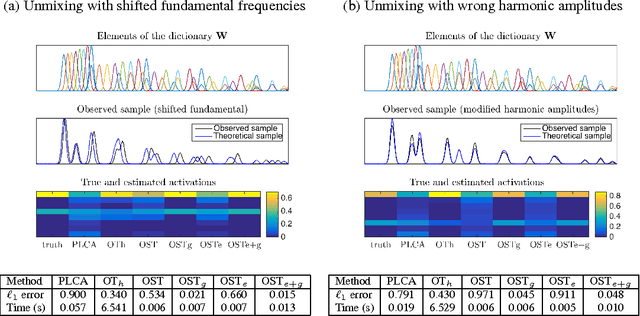
Many spectral unmixing methods rely on the non-negative decomposition of spectral data onto a dictionary of spectral templates. In particular, state-of-the-art music transcription systems decompose the spectrogram of the input signal onto a dictionary of representative note spectra. The typical measures of fit used to quantify the adequacy of the decomposition compare the data and template entries frequency-wise. As such, small displacements of energy from a frequency bin to another as well as variations of timber can disproportionally harm the fit. We address these issues by means of optimal transportation and propose a new measure of fit that treats the frequency distributions of energy holistically as opposed to frequency-wise. Building on the harmonic nature of sound, the new measure is invariant to shifts of energy to harmonically-related frequencies, as well as to small and local displacements of energy. Equipped with this new measure of fit, the dictionary of note templates can be considerably simplified to a set of Dirac vectors located at the target fundamental frequencies (musical pitch values). This in turns gives ground to a very fast and simple decomposition algorithm that achieves state-of-the-art performance on real musical data.
Dynamic Screening: Accelerating First-Order Algorithms for the Lasso and Group-Lasso
Dec 12, 2014
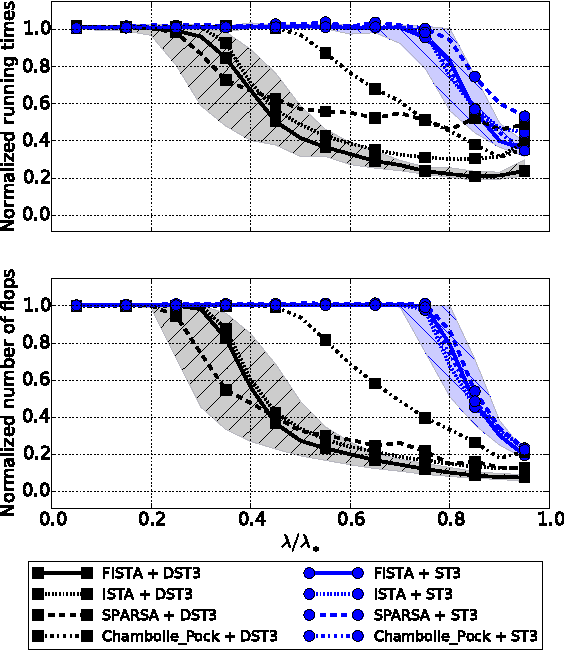
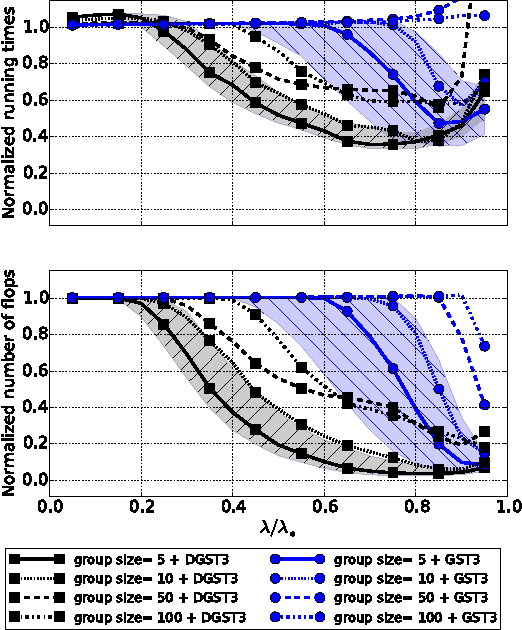

Recent computational strategies based on screening tests have been proposed to accelerate algorithms addressing penalized sparse regression problems such as the Lasso. Such approaches build upon the idea that it is worth dedicating some small computational effort to locate inactive atoms and remove them from the dictionary in a preprocessing stage so that the regression algorithm working with a smaller dictionary will then converge faster to the solution of the initial problem. We believe that there is an even more efficient way to screen the dictionary and obtain a greater acceleration: inside each iteration of the regression algorithm, one may take advantage of the algorithm computations to obtain a new screening test for free with increasing screening effects along the iterations. The dictionary is henceforth dynamically screened instead of being screened statically, once and for all, before the first iteration. We formalize this dynamic screening principle in a general algorithmic scheme and apply it by embedding inside a number of first-order algorithms adapted existing screening tests to solve the Lasso or new screening tests to solve the Group-Lasso. Computational gains are assessed in a large set of experiments on synthetic data as well as real-world sounds and images. They show both the screening efficiency and the gain in terms running times.