 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing time-frequency resolution with optimal transport and barycentric fusion of multiple spectrogram
Apr 16, 2026Time-frequency representations, such as the short-time Fourier transform (STFT), are fundamental tools for analyzing non-stationary signals. However, their ability to achieve sharp localization in both time and frequency is inherently limited by the Gabor-Heisenberg uncertainty principle. In this paper, we address this limitation by introducing a method to generate super-resolution spectrograms through the fusion of two or more spectrograms with varying resolutions. Specifically, we compute the super-resolution spectrogram as the barycenter of input spectrograms using optimal transport (OT) divergences. Unlike existing fusion approaches, our method does not require the input spectrograms to share the same time-frequency grid. Instead, the input spectrograms can be computed using any STFT parameters, and the resulting super-resolution spectrogram can be defined on an arbitrary user-specified grid. We explore various OT divergences based on different transportation costs. Notably, we introduce a novel transportation cost that preserves time-frequency geometry while significantly reducing computational complexity compared to standard Wasserstein barycenters. We adopt the unbalanced OT framework and derive a new block majorization-minimization algorithm for efficient barycenter computation. We validate the proposed method on controlled synthetic signals and recorded speech using both quantitative and qualitative evaluations. The results show that our approach combines the best localization properties of the input spectrograms and outperforms an unsupervised state-of-the-art fusion method.
PDRs4All XX. Haute Couture: Spectral stitching of JWST MIRI-IFU cubes with matrix completion
Nov 17, 2025MIRI is the imager and spectrograph covering wavelengths from $4.9$ to $27.9$ $μ$m onboard the James Webb Space Telescope (JWST). The Medium-Resolution Spectrometer (MRS) consists of four integral field units (IFU), each of which has three sub-channels. The twelve resulting spectral data cubes have different fields of view, spatial, and spectral resolutions. The wavelength range of each cube partially overlaps with the neighboring bands, and the overlap regions typically show flux mismatches which have to be corrected by spectral stitching methods. Stitching methods aim to produce a single data cube incorporating the data of the individual sub-channels, which requires matching the spatial resolution and the flux discrepancies. We present Haute Couture, a novel stitching algorithm which uses non-negative matrix factorization (NMF) to perform a matrix completion, where the available MRS data cubes are treated as twelve sub-matrices of a larger incomplete matrix. Prior to matrix completion, we also introduce a novel pre-processing to homogenize the global intensities of the twelve cubes. Our pre-processing consists in jointly optimizing a set of global scale parameters that maximize the fit between the cubes where spectral overlap occurs. We apply our novel stitching method to JWST data obtained as part of the PDRs4All observing program of the Orion Bar, and produce a uniform cube reconstructed with the best spatial resolution over the full range of wavelengths.
Audio signal interpolation using optimal transportation of spectrograms
Feb 21, 2025We present a novel approach for generating an artificial audio signal that interpolates between given source and target sounds. Our approach relies on the computation of Wasserstein barycenters of the source and target spectrograms, followed by phase reconstruction and inversion. In contrast with previous works, our new method considers the spectrograms globally and does not operate on a temporal frame-to-frame basis. An other contribution is to endow the transportation cost matrix with a specific structure that prohibits remote displacements of energy along the time axis, and for which optimal transport is made possible by leveraging the unbalanced transport framework. The proposed cost matrix makes sense from the audio perspective and also allows to reduce the computation load. Results with synthetic musical notes and real environmental sounds illustrate the potential of our novel approach.
Majorization-minimization for Sparse Nonnegative Matrix Factorization with the $β$-divergence
Jul 13, 2022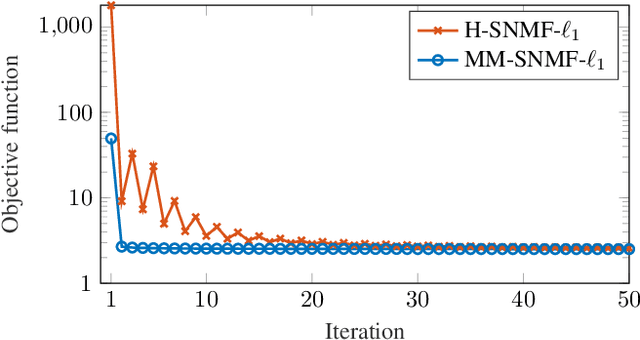
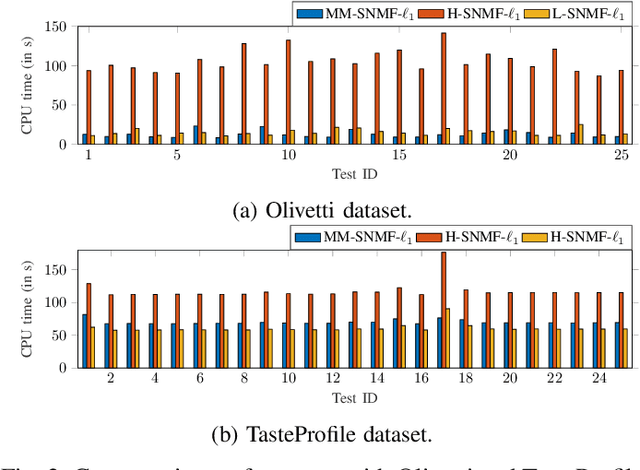
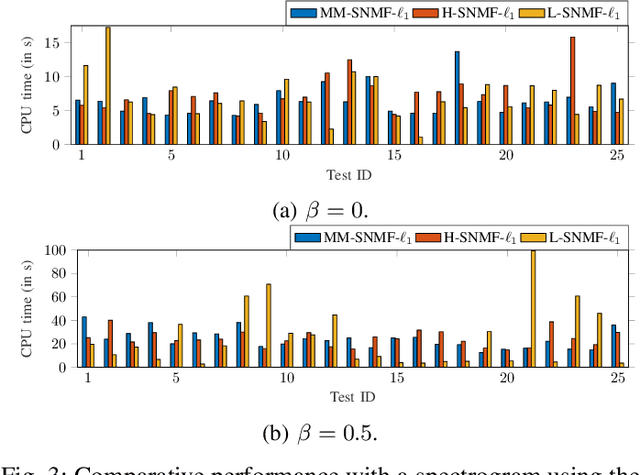
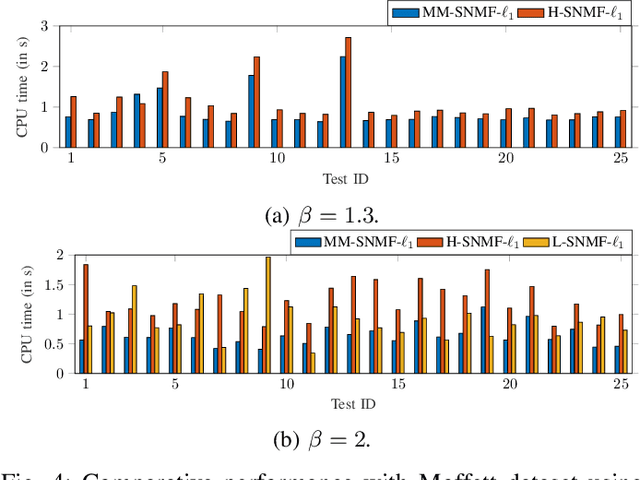
This article introduces new multiplicative updates for nonnegative matrix factorization with the $\beta$-divergence and sparse regularization of one of the two factors (say, the activation matrix). It is well known that the norm of the other factor (the dictionary matrix) needs to be controlled in order to avoid an ill-posed formulation. Standard practice consists in constraining the columns of the dictionary to have unit norm, which leads to a nontrivial optimization problem. Our approach leverages a reparametrization of the original problem into the optimization of an equivalent scale-invariant objective function. From there, we derive block-descent majorization-minimization algorithms that result in simple multiplicative updates for either $\ell_{1}$-regularization or the more "aggressive" log-regularization. In contrast with other state-of-the-art methods, our algorithms are universal in the sense that they can be applied to any $\beta$-divergence (i.e., any value of $\beta$) and that they come with convergence guarantees. We report numerical comparisons with existing heuristic and Lagrangian methods using various datasets: face images, an audio spectrogram, hyperspectral data, and song play counts. We show that our methods obtain solutions of similar quality at convergence (similar objective values) but with significantly reduced CPU times.
Algorithms for audio inpainting based on probabilistic nonnegative matrix factorization
Jun 28, 2022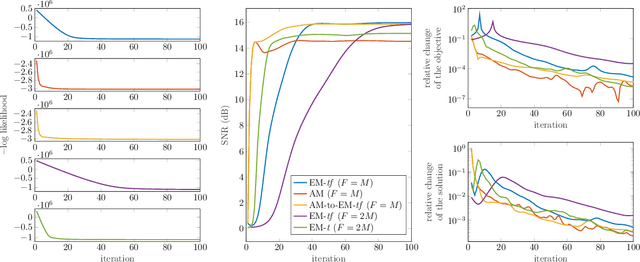

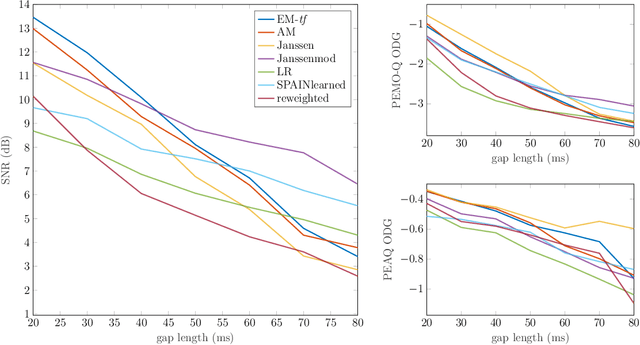
Audio inpainting, i.e., the task of restoring missing or occluded audio signal samples, usually relies on sparse representations or autoregressive modeling. In this paper, we propose to structure the spectrogram with nonnegative matrix factorization (NMF) in a probabilistic framework. First, we treat the missing samples as latent variables, and derive two expectation-maximization algorithms for estimating the parameters of the model, depending on whether we formulate the problem in the time- or time-frequency domain. Then, we treat the missing samples as parameters, and we address this novel problem by deriving an alternating minimization scheme. We assess the potential of these algorithms for the task of restoring short- to middle-length gaps in music signals. Experiments reveal great convergence properties of the proposed methods, as well as competitive performance when compared to state-of-the-art audio inpainting techniques.
A majorization-minimization algorithm for nonnegative binary matrix factorization
Apr 20, 2022
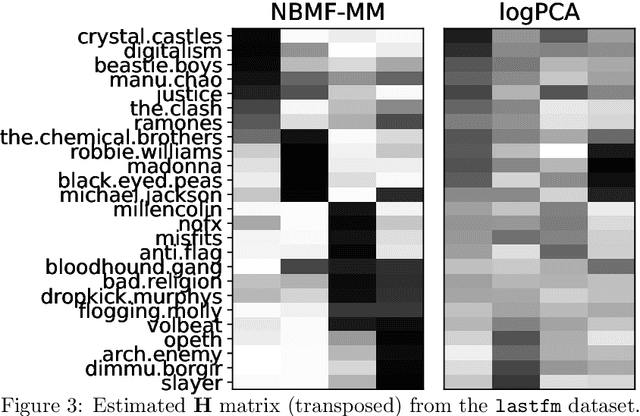
This paper tackles the problem of decomposing binary data using matrix factorization. We consider the family of mean-parametrized Bernoulli models, a class of generative models that are well suited for modeling binary data and enables interpretability of the factors. We factorize the Bernoulli parameter and consider an additional Beta prior on one of the factors to further improve the model's expressive power. While similar models have been proposed in the literature, they only exploit the Beta prior as a proxy to ensure a valid Bernoulli parameter in a Bayesian setting; in practice it reduces to a uniform or uninformative prior. Besides, estimation in these models has focused on costly Bayesian inference. In this paper, we propose a simple yet very efficient majorization-minimization algorithm for maximum a posteriori estimation. Our approach leverages the Beta prior whose parameters can be tuned to improve performance in matrix completion tasks. Experiments conducted on three public binary datasets show that our approach offers an excellent trade-off between prediction performance, computational complexity, and interpretability.
Learning the Proximity Operator in Unfolded ADMM for Phase Retrieval
Apr 04, 2022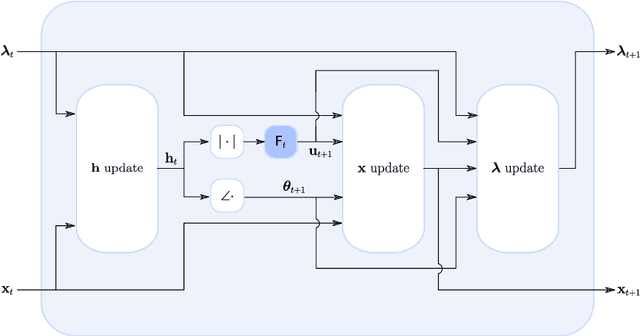
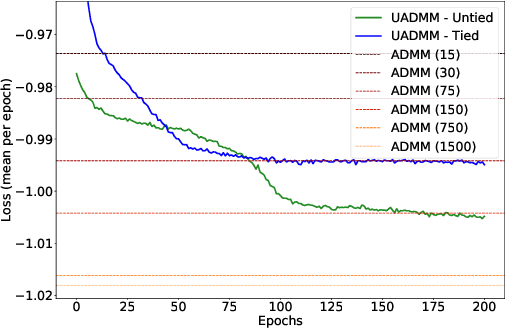
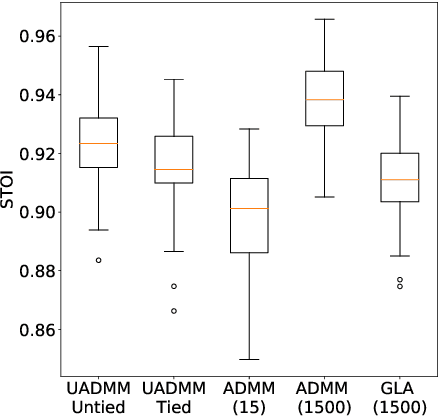
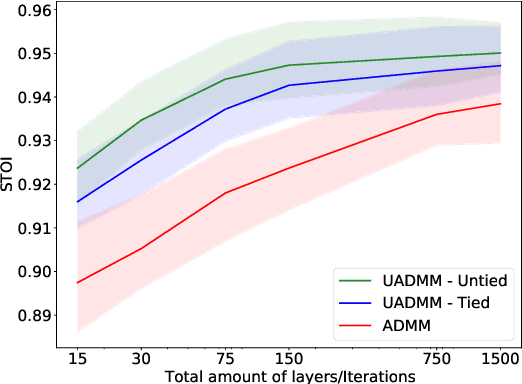
This paper considers the phase retrieval (PR) problem, which aims to reconstruct a signal from phaseless measurements such as magnitude or power spectrograms. PR is generally handled as a minimization problem involving a quadratic loss. Recent works have considered alternative discrepancy measures, such as the Bregman divergences, but it is still challenging to tailor the optimal loss for a given setting. In this paper we propose a novel strategy to automatically learn the optimal metric for PR. We unfold a recently introduced ADMM algorithm into a neural network, and we emphasize that the information about the loss used to formulate the PR problem is conveyed by the proximity operator involved in the ADMM updates. Therefore, we replace this proximity operator with trainable activation functions: learning these in a supervised setting is then equivalent to learning an optimal metric for PR. Experiments conducted with speech signals show that our approach outperforms the baseline ADMM, using a light and interpretable neural architecture.
Accelerating Non-Negative and Bounded-Variable Linear Regression Algorithms with Safe Screening
Feb 15, 2022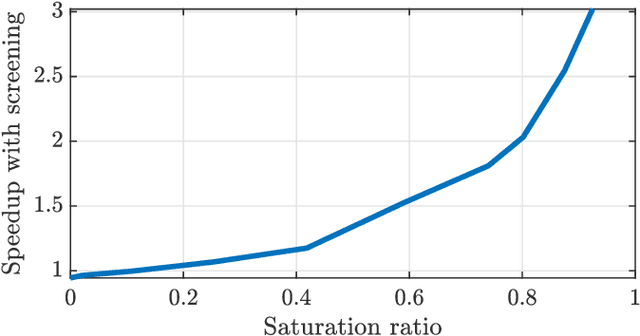
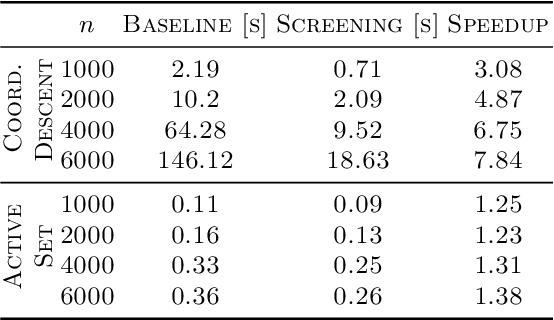
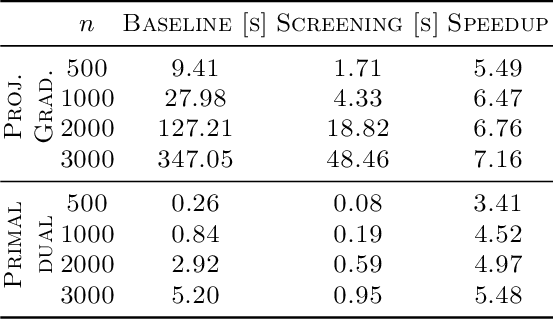
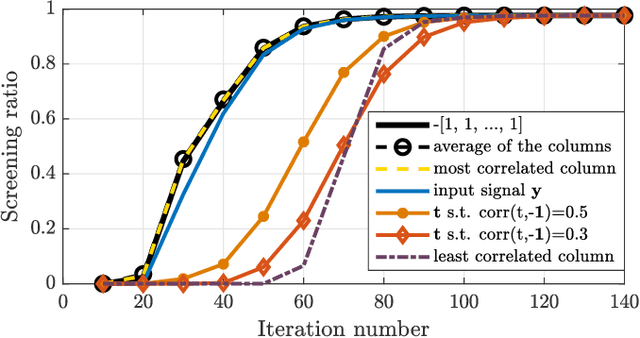
Non-negative and bounded-variable linear regression problems arise in a variety of applications in machine learning and signal processing. In this paper, we propose a technique to accelerate existing solvers for these problems by identifying saturated coordinates in the course of iterations. This is akin to safe screening techniques previously proposed for sparsity-regularized regression problems. The proposed strategy is provably safe as it provides theoretical guarantees that the identified coordinates are indeed saturated in the optimal solution. Experimental results on synthetic and real data show compelling accelerations for both non-negative and bounded-variable problems.
On the Relationships between Transform-Learning NMF and Joint-Diagonalization
Dec 10, 2021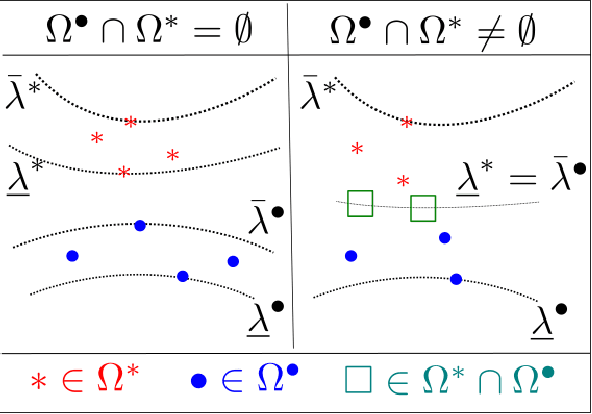
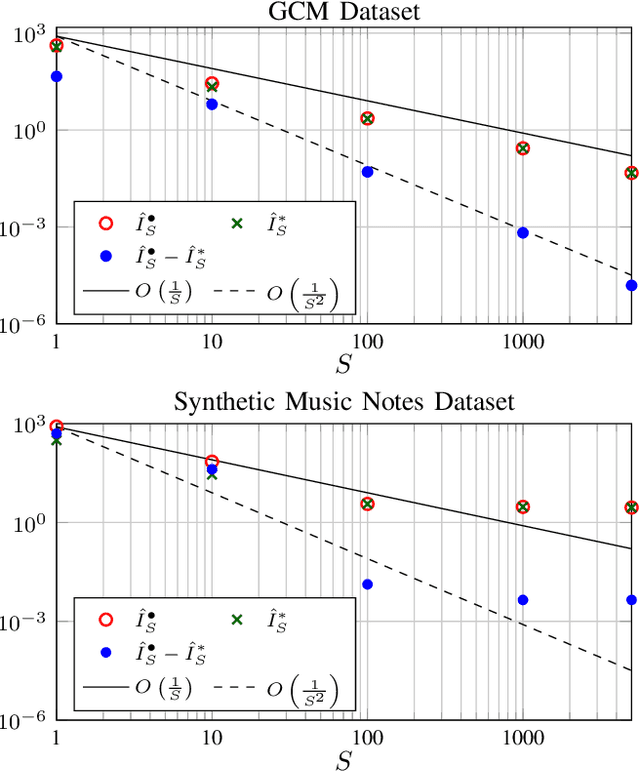
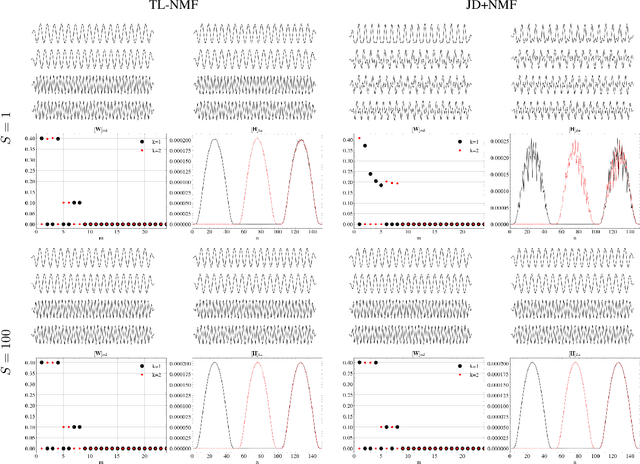
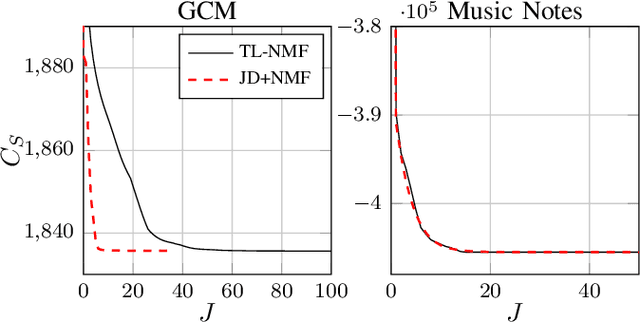
Non-negative matrix factorization with transform learning (TL-NMF) is a recent idea that aims at learning data representations suited to NMF. In this work, we relate TL-NMF to the classical matrix joint-diagonalization (JD) problem. We show that, when the number of data realizations is sufficiently large, TL-NMF can be replaced by a two-step approach -- termed as JD+NMF -- that estimates the transform through JD, prior to NMF computation. In contrast, we found that when the number of data realizations is limited, not only is JD+NMF no longer equivalent to TL-NMF, but the inherent low-rank constraint of TL-NMF turns out to be an essential ingredient to learn meaningful transforms for NMF.
Joint Majorization-Minimization for Nonnegative Matrix Factorization with the $β$-divergence
Jun 29, 2021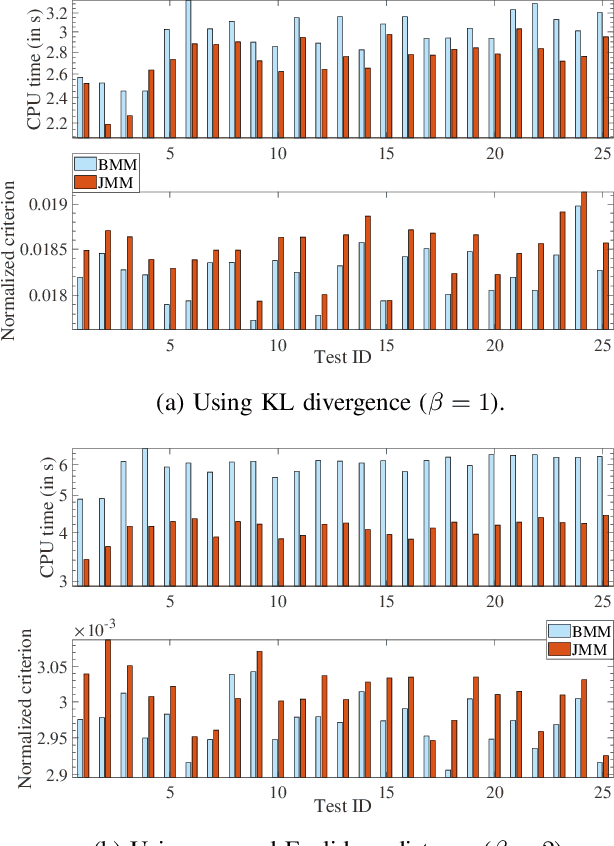
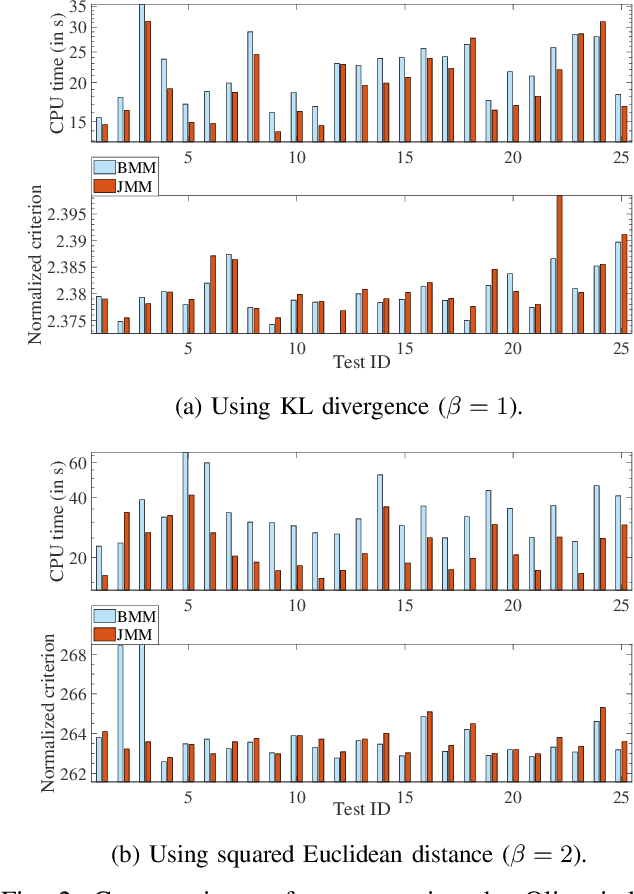
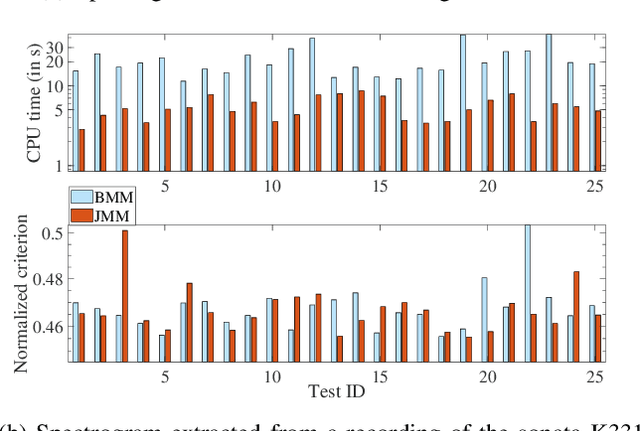
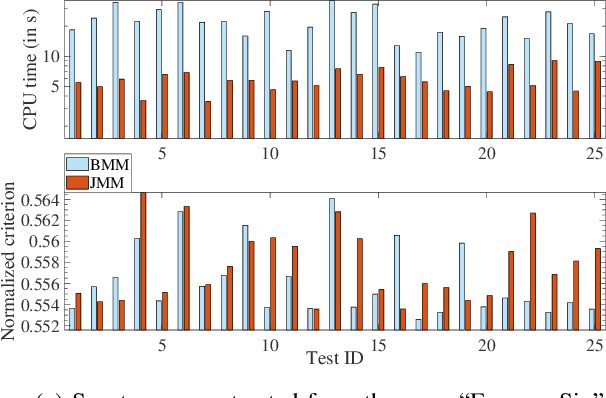
This article proposes new multiplicative updates for nonnegative matrix factorization (NMF) with the $\beta$-divergence objective function. Our new updates are derived from a joint majorization-minimization (MM) scheme, in which an auxiliary function (a tight upper bound of the objective function) is built for the two factors jointly and minimized at each iteration. This is in contrast with the classic approach in which the factors are optimized alternately and a MM scheme is applied to each factor individually. Like the classic approach, our joint MM algorithm also results in multiplicative updates that are simple to implement. They however yield a significant drop of computation time (for equally good solutions), in particular for some $\beta$-divergences of important applicative interest, such as the squared Euclidean distance and the Kullback-Leibler or Itakura-Saito divergences. We report experimental results using diverse datasets: face images, audio spectrograms, hyperspectral data and song play counts. Depending on the value of $\beta$ and on the dataset, our joint MM approach yields a CPU time reduction of about $10\%$ to $78\%$ in comparison to the classic alternating scheme.