 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer by layer, module by module: Choose both for optimal OOD probing of ViT
Mar 05, 2026Recent studies have observed that intermediate layers of foundation models often yield more discriminative representations than the final layer. While initially attributed to autoregressive pretraining, this phenomenon has also been identified in models trained via supervised and discriminative self-supervised objectives. In this paper, we conduct a comprehensive study to analyze the behavior of intermediate layers in pretrained vision transformers. Through extensive linear probing experiments across a diverse set of image classification benchmarks, we find that distribution shift between pretraining and downstream data is the primary cause of performance degradation in deeper layers. Furthermore, we perform a fine-grained analysis at the module level. Our findings reveal that standard probing of transformer block outputs is suboptimal; instead, probing the activation within the feedforward network yields the best performance under significant distribution shift, whereas the normalized output of the multi-head self-attention module is optimal when the shift is weak.
Vision Transformer Finetuning Benefits from Non-Smooth Components
Feb 09, 2026The smoothness of the transformer architecture has been extensively studied in the context of generalization, training stability, and adversarial robustness. However, its role in transfer learning remains poorly understood. In this paper, we analyze the ability of vision transformer components to adapt their outputs to changes in inputs, or, in other words, their plasticity. Defined as an average rate of change, it captures the sensitivity to input perturbation; in particular, a high plasticity implies low smoothness. We demonstrate through theoretical analysis and comprehensive experiments that this perspective provides principled guidance in choosing the components to prioritize during adaptation. A key takeaway for practitioners is that the high plasticity of the attention modules and feedforward layers consistently leads to better finetuning performance. Our findings depart from the prevailing assumption that smoothness is desirable, offering a novel perspective on the functional properties of transformers. The code is available at https://github.com/ambroiseodt/vit-plasticity.
Bridging Arbitrary and Tree Metrics via Differentiable Gromov Hyperbolicity
May 28, 2025Trees and the associated shortest-path tree metrics provide a powerful framework for representing hierarchical and combinatorial structures in data. Given an arbitrary metric space, its deviation from a tree metric can be quantified by Gromov's $\delta$-hyperbolicity. Nonetheless, designing algorithms that bridge an arbitrary metric to its closest tree metric is still a vivid subject of interest, as most common approaches are either heuristical and lack guarantees, or perform moderately well. In this work, we introduce a novel differentiable optimization framework, coined DeltaZero, that solves this problem. Our method leverages a smooth surrogate for Gromov's $\delta$-hyperbolicity which enables a gradient-based optimization, with a tractable complexity. The corresponding optimization procedure is derived from a problem with better worst case guarantees than existing bounds, and is justified statistically. Experiments on synthetic and real-world datasets demonstrate that our method consistently achieves state-of-the-art distortion.
Differentiable Generalized Sliced Wasserstein Plans
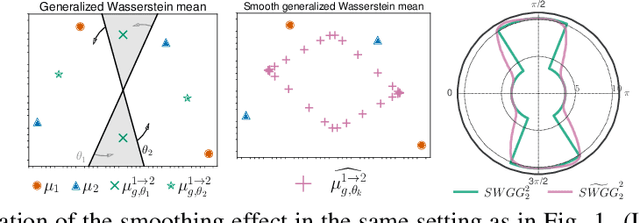
May 28, 2025Optimal Transport (OT) has attracted significant interest in the machine learning community, not only for its ability to define meaningful distances between probability distributions -- such as the Wasserstein distance -- but also for its formulation of OT plans. Its computational complexity remains a bottleneck, though, and slicing techniques have been developed to scale OT to large datasets. Recently, a novel slicing scheme, dubbed min-SWGG, lifts a single one-dimensional plan back to the original multidimensional space, finally selecting the slice that yields the lowest Wasserstein distance as an approximation of the full OT plan. Despite its computational and theoretical advantages, min-SWGG inherits typical limitations of slicing methods: (i) the number of required slices grows exponentially with the data dimension, and (ii) it is constrained to linear projections. Here, we reformulate min-SWGG as a bilevel optimization problem and propose a differentiable approximation scheme to efficiently identify the optimal slice, even in high-dimensional settings. We furthermore define its generalized extension for accommodating to data living on manifolds. Finally, we demonstrate the practical value of our approach in various applications, including gradient flows on manifolds and high-dimensional spaces, as well as a novel sliced OT-based conditional flow matching for image generation -- where fast computation of transport plans is essential.
Match-And-Deform: Time Series Domain Adaptation through Optimal Transport and Temporal Alignment
Aug 25, 2023



While large volumes of unlabeled data are usually available, associated labels are often scarce. The unsupervised domain adaptation problem aims at exploiting labels from a source domain to classify data from a related, yet different, target domain. When time series are at stake, new difficulties arise as temporal shifts may appear in addition to the standard feature distribution shift. In this paper, we introduce the Match-And-Deform (MAD) approach that aims at finding correspondences between the source and target time series while allowing temporal distortions. The associated optimization problem simultaneously aligns the series thanks to an optimal transport loss and the time stamps through dynamic time warping. When embedded into a deep neural network, MAD helps learning new representations of time series that both align the domains and maximize the discriminative power of the network. Empirical studies on benchmark datasets and remote sensing data demonstrate that MAD makes meaningful sample-to-sample pairing and time shift estimation, reaching similar or better classification performance than state-of-the-art deep time series domain adaptation strategies.
Fast Optimal Transport through Sliced Wasserstein Generalized Geodesics
Jul 04, 2023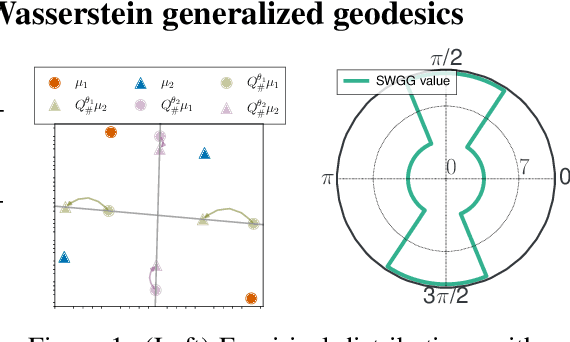

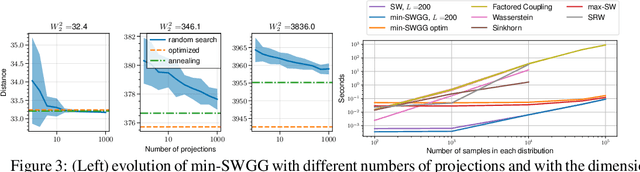
Wasserstein distance (WD) and the associated optimal transport plan have been proven useful in many applications where probability measures are at stake. In this paper, we propose a new proxy of the squared WD, coined min-SWGG, that is based on the transport map induced by an optimal one-dimensional projection of the two input distributions. We draw connections between min-SWGG and Wasserstein generalized geodesics in which the pivot measure is supported on a line. We notably provide a new closed form for the exact Wasserstein distance in the particular case of one of the distributions supported on a line allowing us to derive a fast computational scheme that is amenable to gradient descent optimization. We show that min-SWGG is an upper bound of WD and that it has a complexity similar to as Sliced-Wasserstein, with the additional feature of providing an associated transport plan. We also investigate some theoretical properties such as metricity, weak convergence, computational and topological properties. Empirical evidences support the benefits of min-SWGG in various contexts, from gradient flows, shape matching and image colorization, among others.
Hyperbolic Sliced-Wasserstein via Geodesic and Horospherical Projections
Nov 18, 2022



It has been shown beneficial for many types of data which present an underlying hierarchical structure to be embedded in hyperbolic spaces. Consequently, many tools of machine learning were extended to such spaces, but only few discrepancies to compare probability distributions defined over those spaces exist. Among the possible candidates, optimal transport distances are well defined on such Riemannian manifolds and enjoy strong theoretical properties, but suffer from high computational cost. On Euclidean spaces, sliced-Wasserstein distances, which leverage a closed-form of the Wasserstein distance in one dimension, are more computationally efficient, but are not readily available on hyperbolic spaces. In this work, we propose to derive novel hyperbolic sliced-Wasserstein discrepancies. These constructions use projections on the underlying geodesics either along horospheres or geodesics. We study and compare them on different tasks where hyperbolic representations are relevant, such as sampling or image classification.
Unbalanced Optimal Transport through Non-negative Penalized Linear Regression
Jun 08, 2021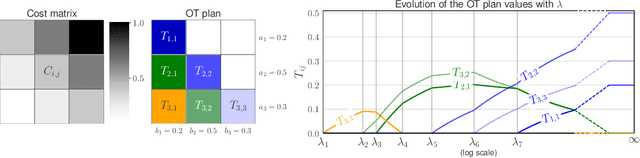
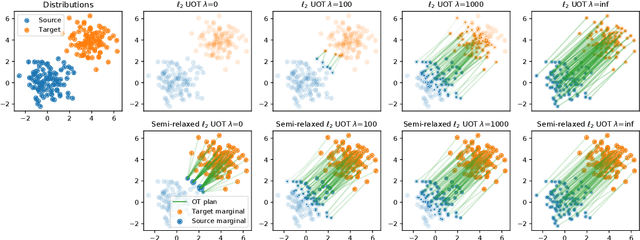
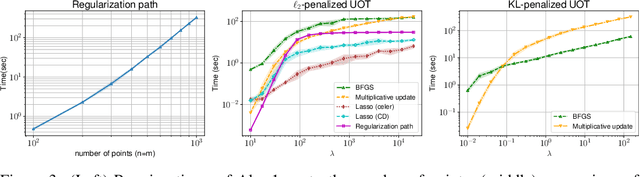
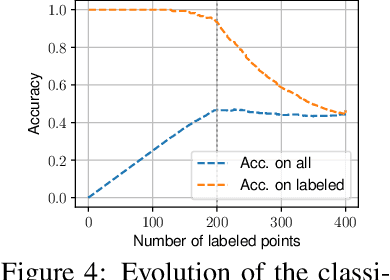
This paper addresses the problem of Unbalanced Optimal Transport (UOT) in which the marginal conditions are relaxed (using weighted penalties in lieu of equality) and no additional regularization is enforced on the OT plan. In this context, we show that the corresponding optimization problem can be reformulated as a non-negative penalized linear regression problem. This reformulation allows us to propose novel algorithms inspired from inverse problems and nonnegative matrix factorization. In particular, we consider majorization-minimization which leads in our setting to efficient multiplicative updates for a variety of penalties. Furthermore, we derive for the first time an efficient algorithm to compute the regularization path of UOT with quadratic penalties. The proposed algorithm provides a continuity of piece-wise linear OT plans converging to the solution of balanced OT (corresponding to infinite penalty weights). We perform several numerical experiments on simulated and real data illustrating the new algorithms, and provide a detailed discussion about more sophisticated optimization tools that can further be used to solve OT problems thanks to our reformulation.
Partial Gromov-Wasserstein with Applications on Positive-Unlabeled Learning
Feb 19, 2020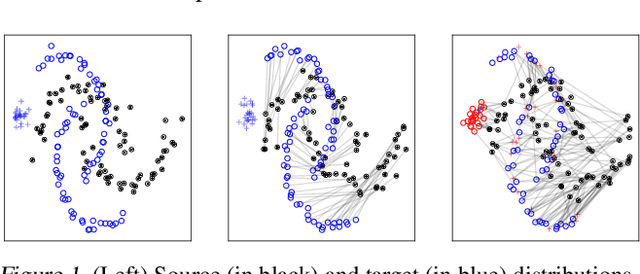
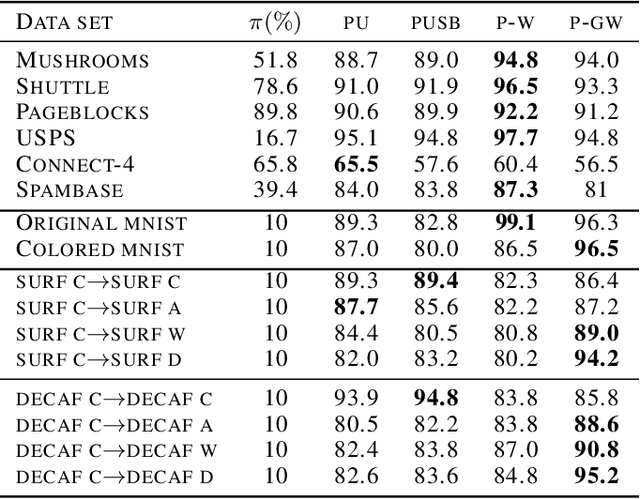
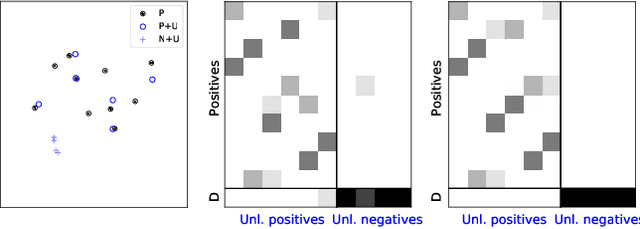

Optimal Transport (OT) framework allows defining similarity between probability distributions and provides metrics such as the Wasserstein and Gromov-Wasserstein discrepancies. Classical OT problem seeks a transportation map that preserves the total mass, requiring the mass of the source and target distributions to be the same. This may be too restrictive in certain applications such as color or shape matching, since the distributions may have arbitrary masses or that only a fraction of the total mass has to be transported. Several algorithms have been devised for computing unbalanced Wasserstein metrics but when it comes with the Gromov-Wasserstein problem, no partial formulation is available yet. This precludes from working with distributions that do not lie in the same metric space or when invariance to rotation or translation is needed. In this paper, we address the partial Gromov-Wasserstein problem and propose an algorithm to solve it. We showcase the new formulation in a positive-unlabeled (PU) learning application. To the best of our knowledge, this is the first application of optimal transport in this context and we first highlight that partial Wasserstein-based metrics prove effective in usual PU learning settings. We then demonstrate that partial Gromov-Wasserstein metrics is efficient in scenario where point clouds come from different domains or have different features.
Time Series Alignment with Global Invariances
Feb 10, 2020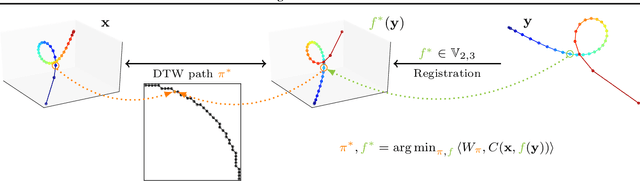

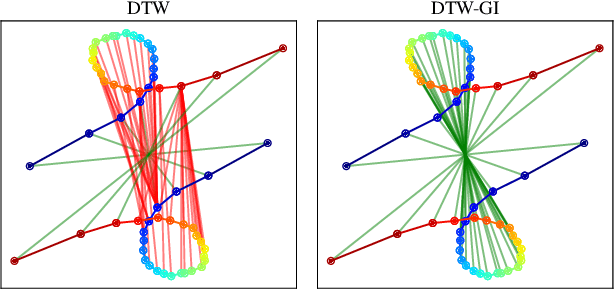
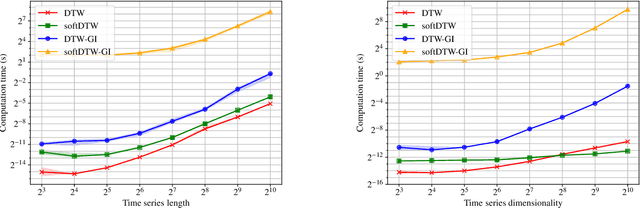
In this work we address the problem of comparing time series while taking into account both feature space transformation and temporal variability. The proposed framework combines a latent global transformation of the feature space with the widely used Dynamic Time Warping (DTW). The latent global transformation captures the feature invariance while the DTW (or its smooth counterpart soft-DTW) deals with the temporal shifts. We cast the problem as a joint optimization over the global transformation and the temporal alignments. The versatility of our framework allows for several variants depending on the invariance class at stake. Among our contributions we define a differentiable loss for time series and present two algorithms for the computation of time series barycenters under our new geometry. We illustrate the interest of our approach on both simulated and real world data.