 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer by layer, module by module: Choose both for optimal OOD probing of ViT
Mar 05, 2026Recent studies have observed that intermediate layers of foundation models often yield more discriminative representations than the final layer. While initially attributed to autoregressive pretraining, this phenomenon has also been identified in models trained via supervised and discriminative self-supervised objectives. In this paper, we conduct a comprehensive study to analyze the behavior of intermediate layers in pretrained vision transformers. Through extensive linear probing experiments across a diverse set of image classification benchmarks, we find that distribution shift between pretraining and downstream data is the primary cause of performance degradation in deeper layers. Furthermore, we perform a fine-grained analysis at the module level. Our findings reveal that standard probing of transformer block outputs is suboptimal; instead, probing the activation within the feedforward network yields the best performance under significant distribution shift, whereas the normalized output of the multi-head self-attention module is optimal when the shift is weak.
Vision Transformer Finetuning Benefits from Non-Smooth Components
Feb 09, 2026The smoothness of the transformer architecture has been extensively studied in the context of generalization, training stability, and adversarial robustness. However, its role in transfer learning remains poorly understood. In this paper, we analyze the ability of vision transformer components to adapt their outputs to changes in inputs, or, in other words, their plasticity. Defined as an average rate of change, it captures the sensitivity to input perturbation; in particular, a high plasticity implies low smoothness. We demonstrate through theoretical analysis and comprehensive experiments that this perspective provides principled guidance in choosing the components to prioritize during adaptation. A key takeaway for practitioners is that the high plasticity of the attention modules and feedforward layers consistently leads to better finetuning performance. Our findings depart from the prevailing assumption that smoothness is desirable, offering a novel perspective on the functional properties of transformers. The code is available at https://github.com/ambroiseodt/vit-plasticity.
Differentiable Generalized Sliced Wasserstein Plans
May 28, 2025Optimal Transport (OT) has attracted significant interest in the machine learning community, not only for its ability to define meaningful distances between probability distributions -- such as the Wasserstein distance -- but also for its formulation of OT plans. Its computational complexity remains a bottleneck, though, and slicing techniques have been developed to scale OT to large datasets. Recently, a novel slicing scheme, dubbed min-SWGG, lifts a single one-dimensional plan back to the original multidimensional space, finally selecting the slice that yields the lowest Wasserstein distance as an approximation of the full OT plan. Despite its computational and theoretical advantages, min-SWGG inherits typical limitations of slicing methods: (i) the number of required slices grows exponentially with the data dimension, and (ii) it is constrained to linear projections. Here, we reformulate min-SWGG as a bilevel optimization problem and propose a differentiable approximation scheme to efficiently identify the optimal slice, even in high-dimensional settings. We furthermore define its generalized extension for accommodating to data living on manifolds. Finally, we demonstrate the practical value of our approach in various applications, including gradient flows on manifolds and high-dimensional spaces, as well as a novel sliced OT-based conditional flow matching for image generation -- where fast computation of transport plans is essential.
Match-And-Deform: Time Series Domain Adaptation through Optimal Transport and Temporal Alignment
Aug 25, 2023



While large volumes of unlabeled data are usually available, associated labels are often scarce. The unsupervised domain adaptation problem aims at exploiting labels from a source domain to classify data from a related, yet different, target domain. When time series are at stake, new difficulties arise as temporal shifts may appear in addition to the standard feature distribution shift. In this paper, we introduce the Match-And-Deform (MAD) approach that aims at finding correspondences between the source and target time series while allowing temporal distortions. The associated optimization problem simultaneously aligns the series thanks to an optimal transport loss and the time stamps through dynamic time warping. When embedded into a deep neural network, MAD helps learning new representations of time series that both align the domains and maximize the discriminative power of the network. Empirical studies on benchmark datasets and remote sensing data demonstrate that MAD makes meaningful sample-to-sample pairing and time shift estimation, reaching similar or better classification performance than state-of-the-art deep time series domain adaptation strategies.
Time Series Alignment with Global Invariances
Feb 10, 2020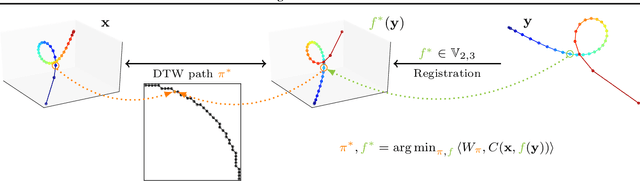

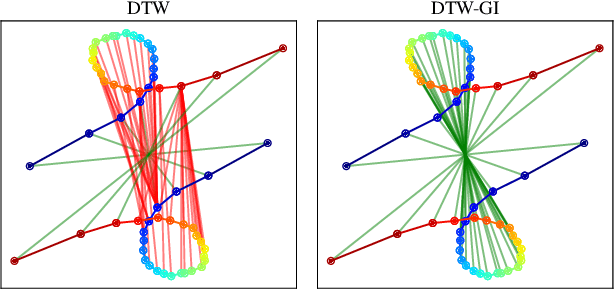
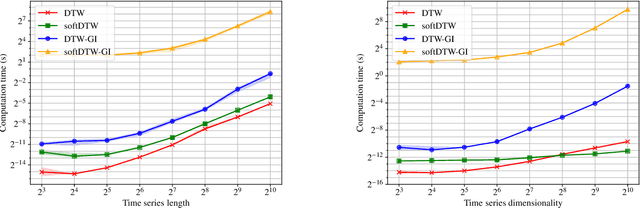
In this work we address the problem of comparing time series while taking into account both feature space transformation and temporal variability. The proposed framework combines a latent global transformation of the feature space with the widely used Dynamic Time Warping (DTW). The latent global transformation captures the feature invariance while the DTW (or its smooth counterpart soft-DTW) deals with the temporal shifts. We cast the problem as a joint optimization over the global transformation and the temporal alignments. The versatility of our framework allows for several variants depending on the invariance class at stake. Among our contributions we define a differentiable loss for time series and present two algorithms for the computation of time series barycenters under our new geometry. We illustrate the interest of our approach on both simulated and real world data.
Early Classification for Agricultural Monitoring from Satellite Time Series
Aug 27, 2019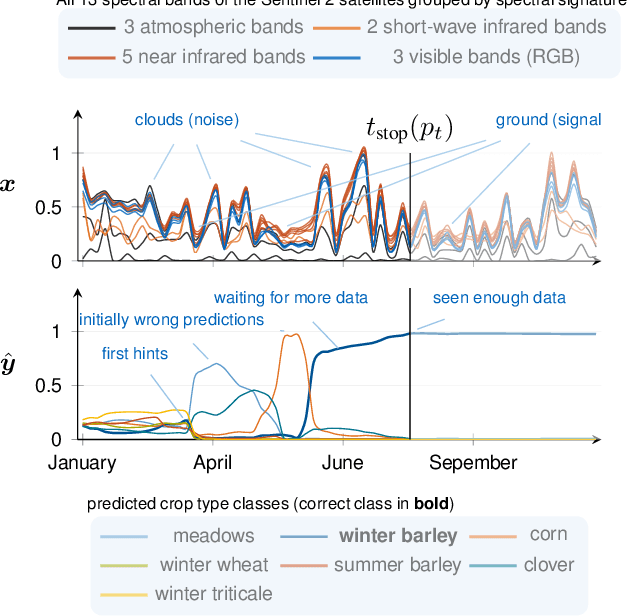
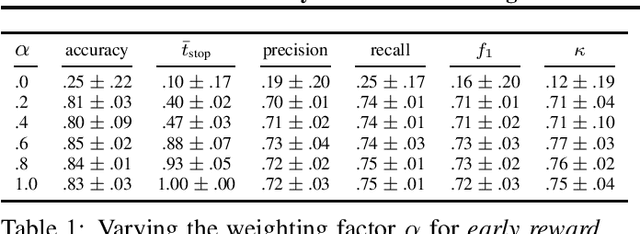
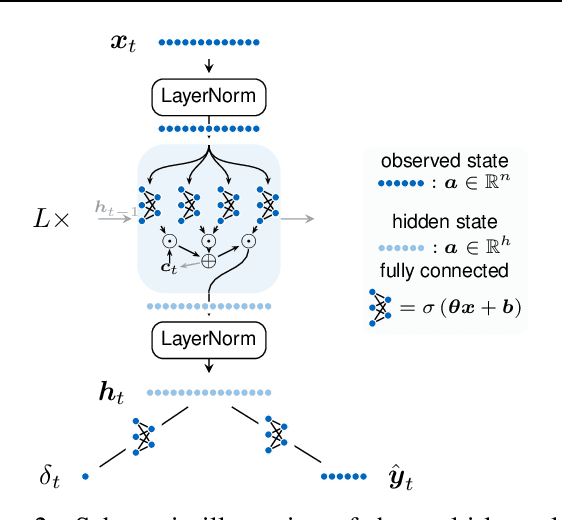
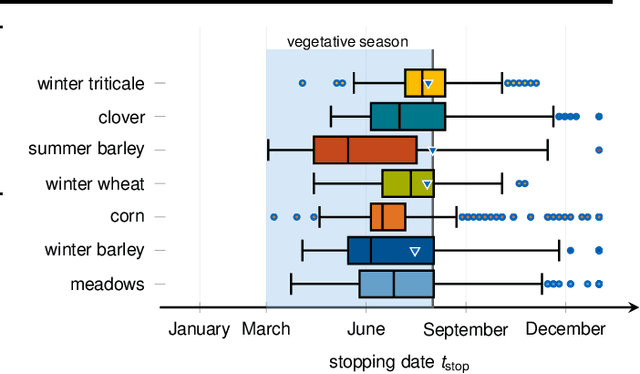
In this work, we introduce a recently developed early classification mechanism to satellite-based agricultural monitoring. It augments existing classification models by an additional stopping probability based on the previously seen information. This mechanism is end-to-end trainable and derives its stopping decision solely from the observed satellite data. We show results on field parcels in central Europe where sufficient ground truth data is available for an empiric evaluation of the results with local phenological information obtained from authorities. We observe that the recurrent neural network outfitted with this early classification mechanism was able to distinguish the many of the crop types before the end of the vegetative period. Further, we associated these stopping times with evaluated ground truth information and saw that the times of classification were related to characteristic events of the observed plants' phenology.
Learning Interpretable Shapelets for Time Series Classification through Adversarial Regularization
Jun 12, 2019
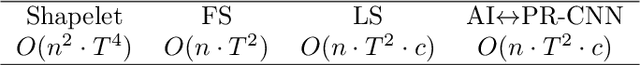
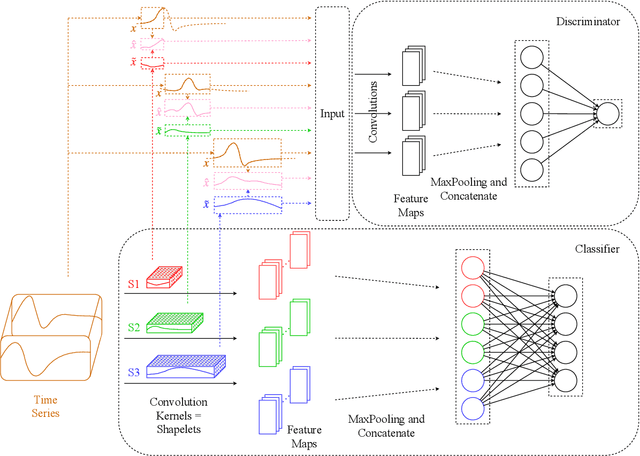
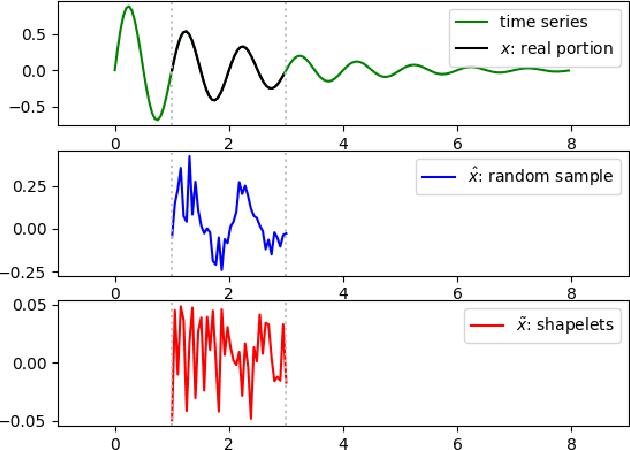
Times series classification can be successfully tackled by jointly learning a shapelet-based representation of the series in the dataset and classifying the series according to this representation. However, although the learned shapelets are discriminative, they are not always similar to pieces of a real series in the dataset. This makes it difficult to interpret the decision, i.e. difficult to analyze if there are particular behaviors in a series that triggered the decision. In this paper, we make use of a simple convolutional network to tackle the time series classification task and we introduce an adversarial regularization to constrain the model to learn more interpretable shapelets. Our classification results on all the usual time series benchmarks are comparable with the results obtained by similar state-of-the-art algorithms but our adversarially regularized method learns shapelets that are, by design, interpretable.
Sliced Gromov-Wasserstein
May 24, 2019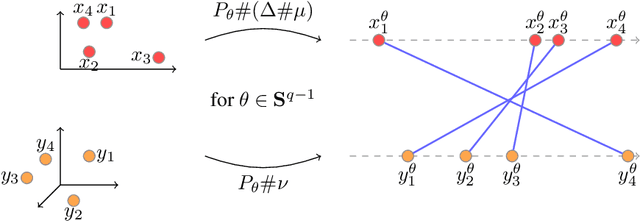
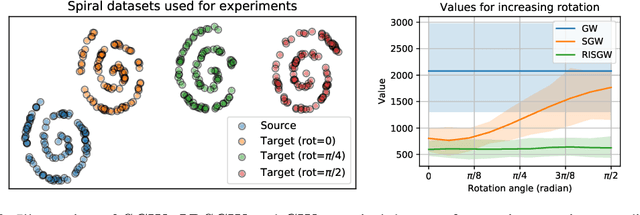
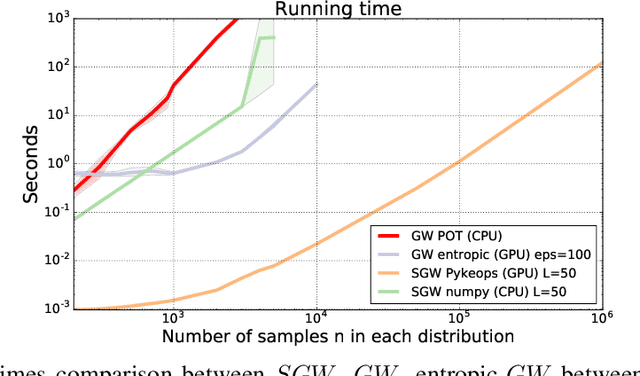
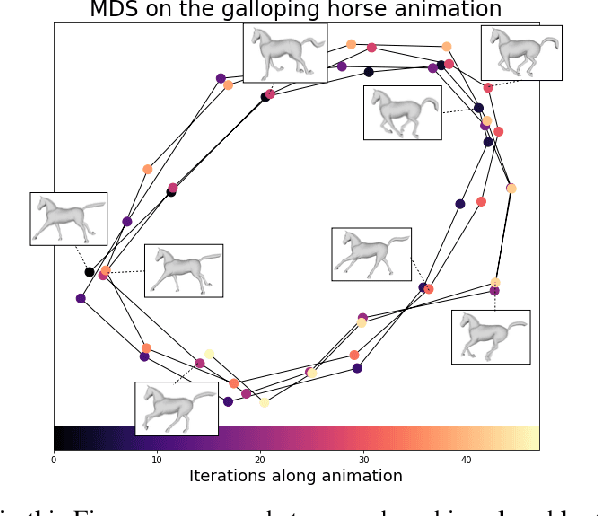
Recently used in various machine learning contexts, the Gromov-Wasserstein distance (GW) allows for comparing distributions that do not necessarily lie in the same metric space. However, this Optimal Transport (OT) distance requires solving a complex non convex quadratic program which is most of the time very costly both in time and memory. Contrary to GW, the Wasserstein distance (W) enjoys several properties (e.g. duality) that permit large scale optimization. Among those, the Sliced Wasserstein (SW) distance exploits the direct solution of W on the line, that only requires sorting discrete samples in 1D. This paper propose a new divergence based on GW akin to SW. We first derive a closed form for GW when dealing with 1D distributions, based on a new result for the related quadratic assignment problem. We then define a novel OT discrepancy that can deal with large scale distributions via a slicing approach and we show how it relates to the GW distance while being $O(n^2)$ to compute. We illustrate the behavior of this so called Sliced Gromov-Wasserstein (SGW) discrepancy in experiments where we demonstrate its ability to tackle similar problems as GW while being several order of magnitudes faster to compute
End-to-end Learning for Early Classification of Time Series
Jan 30, 2019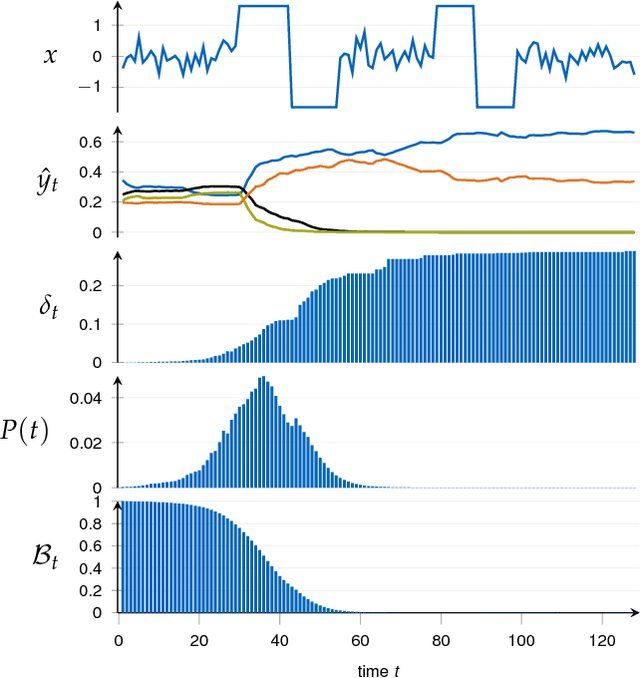

Classification of time series is a topical issue in machine learning. While accuracy stands for the most important evaluation criterion, some applications require decisions to be made as early as possible. Optimization should then target a compromise between earliness, i.e., a capacity of providing a decision early in the sequence, and accuracy. In this work, we propose a generic, end-to-end trainable framework for early classification of time series. This framework embeds a learnable decision mechanism that can be plugged into a wide range of already existing models. We present results obtained with deep neural networks on a diverse set of time series classification problems. Our approach compares well to state-of-the-art competitors while being easily adaptable by any existing neural network topology that evaluates a hidden state at each time step.
Fused Gromov-Wasserstein distance for structured objects: theoretical foundations and mathematical properties
Nov 07, 2018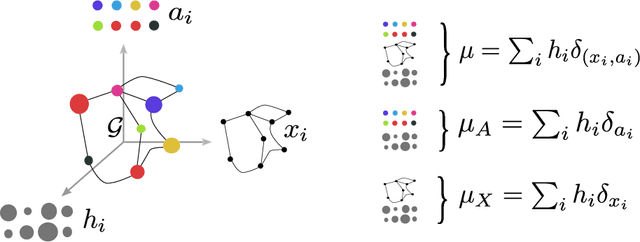


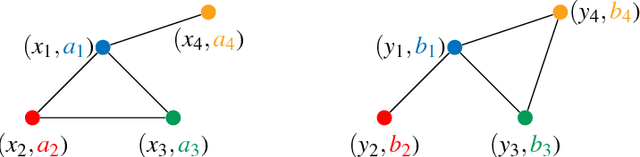
Optimal transport theory has recently found many applications in machine learning thanks to its capacity for comparing various machine learning objects considered as distributions. The Kantorovitch formulation, leading to the Wasserstein distance, focuses on the features of the elements of the objects but treat them independently, whereas the Gromov-Wasserstein distance focuses only on the relations between the elements, depicting the structure of the object, yet discarding its features. In this paper we propose to extend these distances in order to encode simultaneously both the feature and structure informations, resulting in the Fused Gromov-Wasserstein distance. We develop the mathematical framework for this novel distance, prove its metric and interpolation properties and provide a concentration result for the convergence of finite samples. We also illustrate and interpret its use in various contexts where structured objects are involved.